
通知设置 新通知
原来ubuntu发行的版本数字是按照年份来定的22.04 是22年4月发行的
Linux • 李魔佛 发表了文章 • 0 个评论 • 1264 次浏览 • 2022-05-26 11:30
最早用的10.04 这么看就是12年前的操作系统了。
而18.04也差不多也是4年前的操作系统了。
而当前最新的应该就是22.04 LTS 长期支持版本了。
最早用的10.04 这么看就是12年前的操作系统了。
而18.04也差不多也是4年前的操作系统了。
而当前最新的应该就是22.04 LTS 长期支持版本了。
github ssh 报错 Permission denied (publickey) 原因居然是DNS 污染!
网络 • 李魔佛 发表了文章 • 0 个评论 • 1267 次浏览 • 2022-05-26 08:52
最后还怀疑自己电脑的ssl文件被修改了, 重装了一遍 openssh client和server。
结果还造成了悲剧,snap store安装的应用全部不见了。(里面应用包含pycharm goland vs code,mysql连接工具等)。
最后ping了github的ip,居然是这个
到站长助手查了它的DNS:
那问题就解决了。
把hosts的github.com 映射为上面可以使用的那几个即可。
查看全部
最后还怀疑自己电脑的ssl文件被修改了, 重装了一遍 openssh client和server。
结果还造成了悲剧,snap store安装的应用全部不见了。(里面应用包含pycharm goland vs code,mysql连接工具等)。
最后ping了github的ip,居然是这个
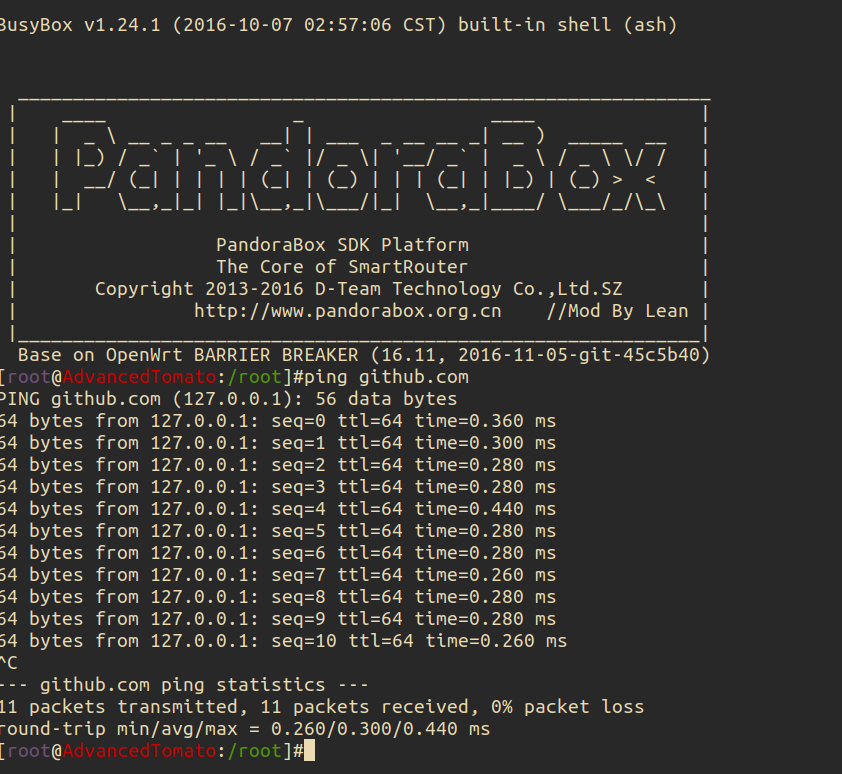
到站长助手查了它的DNS:
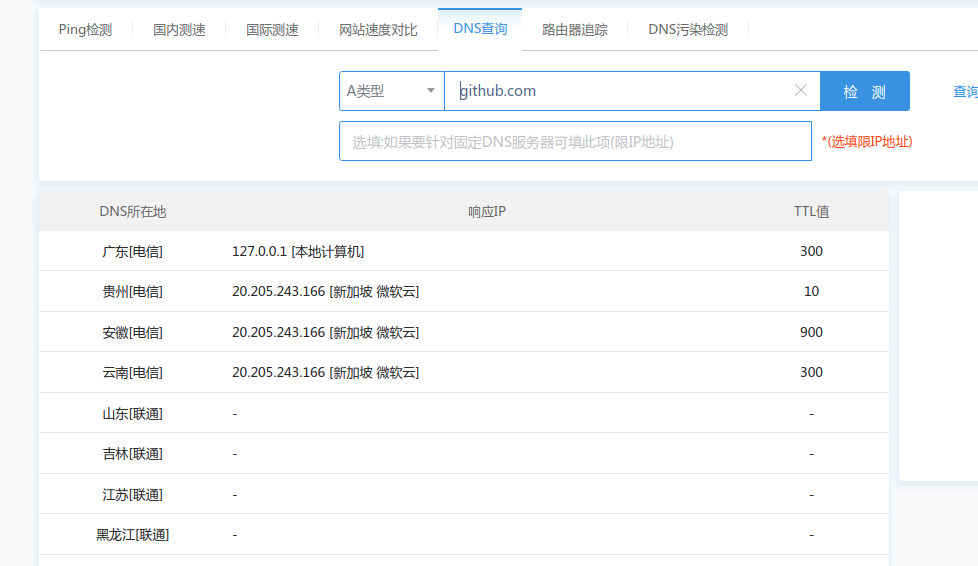
那问题就解决了。
把hosts的github.com 映射为上面可以使用的那几个即可。
B站累计500万播放量的UP主,收益有多少?
闲聊 • 绫波丽 发表了文章 • 0 个评论 • 15853 次浏览 • 2022-05-25 03:09
所以还是不建议大家靠这个B站视频来发财致富了。
累计300w的视频播放,总共收益只有300元,那么大概1万此播放,收益率只有1元,Oh my god。
感慨up主的时间真的很廉价。
再看多几个up主的收益。
大概有80w的播放量,然后总共的收益为600元
所以大概推算出来,B站上的收益,大约是1w的播放量,收益1元。
查看全部
所以还是不建议大家靠这个B站视频来发财致富了。

累计300w的视频播放,总共收益只有300元,那么大概1万此播放,收益率只有1元,Oh my god。
感慨up主的时间真的很廉价。
再看多几个up主的收益。

大概有80w的播放量,然后总共的收益为600元

所以大概推算出来,B站上的收益,大约是1w的播放量,收益1元。
ptrade qmt量化平台收费吗?
券商万一免五 • 李魔佛 回复了问题 • 2 人关注 • 1 个回复 • 3880 次浏览 • 2022-07-13 17:04
vs code远程开发 ssh端口不是默认22时如何配置
网络 • 李魔佛 发表了文章 • 0 个评论 • 1594 次浏览 • 2022-05-23 19:19
其实这个和ssh远程连接一样。
ssh root@192.168.1.1:2222
然后按下enter键 就可以了。
其实这个和ssh远程连接一样。
ssh root@192.168.1.1:2222
然后按下enter键 就可以了。
python识别股票K线形态,准确率回测(一)
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 1 个评论 • 4949 次浏览 • 2022-05-22 01:13
对于一些做股票技术分析的投资者来说,对常见的k线形态应该都不陌生,比如十字星,红三兵,头肩顶(底),岛型反转,吊颈线,两只乌鸦,三只乌鸦,四只乌鸦(哈)
做价投的投资者可能会对这些划线的嗤之以鼻,而短线操盘者却有可能把它奉为圭臬,以之作为买卖标准。
海乃百川,兼听则明,笔者认为多吸收不同的观点与技术,可以更加全面的加深投资认知。你画的圆圈越大,圆圈外的未知空间也越大。
本文介绍使用python对A股市场的股票(转债也可以)的K线进行识别,然后回测某个形态出现后接下来的涨跌幅,还可以通过设定的形态进行选股。
举个例子,我们可以统计所有个股出现了“早晨之星“这一形态后,一周后甚至一个月后,个股是涨了还是跌了,从大量结果中统计出一些有意义的结果。
为了便于验证查看结果图形,我们先介绍如何使用python来画股票K线图。
有数据之后,剩下画图是很简单的,很多第三方的库已经封装好了各种蜡烛图绘制函数。我们要做只是传入每天开,收盘价,以及最高最低价。
获取股票的数据
市面有不少第三方的库可以获取股票和可转债的日线数据,比如tushare和akshare。本文以股票数据为例。
以akshare为例,代码如下所示:
# pip install akshare
import akshare as ak
def get_k_line(code="sz002241"): #
df = ak.stock_zh_a_daily(symbol=code, start_date="20220101", end_date="20220515",
adjust="qfq")
# 这个函数只适合取股票数据,转债会报错,转债的日线数据可以使用其他函数,这里选择股价前复权
df.to_excel("同和药业k.xlsx")
如上面代码所示,我们使用stock_zh_a_daily方法获取一段时间的数据,这里的日期可以根据你的需求进行调整,比如设置start_date=“20200101”,end_date=“20220515”,就可以获取一年时间段的股票数据。
而股票的代码有sh与sz之分,sz代表深市的股票,所有深市的股票前面都必须带上sz,比如这里的同和药业,就是sz002241。
同样的,sh是上证交易所的股票,所有上证的股票前面必须带上sh。
这里,我们来看看获取的同和药业股票数据格式,如下图所示:
date:交易日期
open:代表开盘价
high:当天最高价
low:当天最低价
close:当天收盘价
volume:当天成交量(元)
outstanding_share:流动股本(股)
turnover:换手率
既然已经拿到了数据,下面我们来绘制K线图。
绘制K线图
在python中,绘制K线图需要用到mpl_finance库,而这个库提供了4种方式绘制K线图,这里我们介绍其中的一种,代码如下所示:
import mpl_finance as mpf
import matplotlib.pyplot as plt
import pandas as pd
#创建绘图的基本参数
fig=plt.figure(figsize=(12, 8))
ax=fig.add_subplot(111)
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
#显示出来
plt.show()
运行此段代码后,会显示如下效果图:
和东财上的同和药业的k线图基本一致的。
不过,这个K线图有一个问题,就是X坐标轴并不是显示的时间,而是数字,这是因为我们绘制K线图的方法,并没有提供X轴的参数,那怎么让下面的数字替换为时间呢?
我们先来看一段代码:
import matplotlib.ticker as ticker
#将股票时间转换为标准时间,不带时分秒的数据
def date_to_num(dates):
num_time = []
for date in dates:
date_time = datetime.strptime(date, '%Y-%m-%d')
num_date = date2num(date_time)
num_time.append(num_date)
return num_time
#创建绘图的基本参数
fig=plt.figure(figsize=(12, 8))
ax=fig.add_subplot(111)
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
df['date'] = pd.to_datetime(df['date'])
df['date'] = df['date'].apply(lambda x: x.strftime('%Y-%m-%d'))
def format_date(x, pos=None):
if x < 0 or x > len(df['date']) - 1:
return ''
return df['date'][int(x)]
ax.xaxis.set_major_formatter(ticker.FuncFormatter(format_date))
plt.setp(plt.gca().get_xticklabels(), rotation=45, horizontalalignment='right')
#显示出来
plt.show()
这里,我们定义了2个方法:第1个方法date_to_num主要的作用就是将获取的时间数据转换为标准的日期数据;第2个方法,就是根据X的数值替换时间值。
其中,set_major_formatter方法是将数值替换为时间值的操作库,而plt.setup的功能就是设置X轴的标签倾斜45度以及右对齐。运行之后,我们的K线图就显示的非常完美了,如下图所示:
均线图
虽然我们实现了K线图,但是有没有发现,其实大多数的股票交易软件K线图上面其实还标记有均线,比如常用的有5日均线,10日均线,30均线。
所以,我们需要将均线一起添加到我们的K线图之上。
计算均线的方式如下:
df["SMA5"] = df["close"].rolling(5).mean()
df["SMA10"] = df["close"].rolling(10).mean()
df["SMA30"] = df["close"].rolling(30).mean()
3行代码就可以获取到股票的均线值。
接着,我们可以使用上面的ax进行绘制均线了,
添加的代码如下所示:
ax.plot(np.arange(0, len(df)), df['SMA5']) # 绘制5日均线
ax.plot(np.arange(0, len(df)), df['SMA10']) # 绘制10日均线
ax.plot(np.arange(0, len(df)), df['SMA30']) # 绘制30日均线
这里,同样将X轴设置为数字,将这两段代码添加到上面的K线图代码中,自然也会将X轴替换为时间。运行之后,显示效果如下图所示:
这里5日均线为蓝色,10日均线为橙色,30日均线为绿色,如果需要自己设置颜色,可以在每条均线的的绘制方法中加入color参数。
细心的读者肯定发现30日均线只有最后一小段,这是因为前29日不够30日是算不出均线的,同样的5,10日均线也是如此。
成交量
最后,我们还需要绘制成交量。在多数的股票交易软件中,上面是K线图,一般下面对应的就是成交量,这样对比起来看,往往能直观的看到数据的变化。
但是,因为上面有个K线图,那么同一个画布中就有了2个图片,且它们共用一个X轴,那么我们需要更改一下基本的参数,
代码如下所示:
import mpl_finance as mpf
import matplotlib.pyplot as plt
import pandas as pd
import matplotlib.ticker as ticker
import numpy as np
#创建绘图的基本参数
fig, axes = plt.subplots(2, 1, sharex=True, figsize=(15, 10))
ax1, ax2 = axes.flatten()
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax1, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
df['date'] = pd.to_datetime(df['date'])
df['date'] = df['date'].apply(lambda x: x.strftime('%Y-%m-%d'))
def format_date(x, pos=None):
if x < 0 or x > len(df['date']) - 1:
return ''
return df['date'][int(x)]
df["SMA5"] = df["close"].rolling(5).mean()
df["SMA10"] = df["close"].rolling(10).mean()
df["SMA30"] = df["close"].rolling(30).mean()
ax1.plot(np.arange(0, len(df)), df['SMA5']) # 绘制5日均线
ax1.plot(np.arange(0, len(df)), df['SMA10']) # 绘制10日均线
ax1.plot(np.arange(0, len(df)), df['SMA30']) # 绘制30日均线
ax1.xaxis.set_major_formatter(ticker.FuncFormatter(format_date))
plt.setp(plt.gca().get_xticklabels(), rotation=45, horizontalalignment='right')
#显示出来
plt.show()
这里,我们将绘图的画布设置为2行1列。同时,将上面绘制的所有数据都更改为ax1,这样均线与K线图会绘制到第一个子图中。
接着,我们需要绘制成交量,但是我们知道,一般股票交易软件都将上涨的那天成交量设置为红色,而将下跌的成交量绘制成绿色。所以,首先我们要做的是将获取的股票数据根据当天的涨跌情况进行分类。
具体代码如下:
red_pred = np.where(df["close"] > df["open"], df["volume"], 0)
blue_pred = np.where(df["close"] < df["open"], df["volume"], 0)
如上面代码所示,我们通过np.where(condition, x, y)筛选数据。这里满足条件condition,输出X,不满足条件输出Y,这样我们就将涨跌的成交量数据进行了分类。
最后,我们直接通过柱状图方法绘制成交量,
具体代码如下所示:
ax2.bar(np.arange(0, len(df)), red_pred, facecolor="red")
ax2.bar(np.arange(0, len(df)), blue_pred, facecolor="blue")
将这4行代码,全部加入到plt.show()代码的前面即可。
运行之后,输出的效果图如下:
根据定义编写形态
接下来,我们根据定义来构造一个简单的形态函数,比如长上影线。
上影线
根据网络上的定义:
⑤上影阳线:开盘后价格冲高回落,涨势受阻,虽然收盘价仍高于开盘价,但上方有阻力,可视为弱势。
⑥上影阴线:开盘后价格冲高受阻,涨势受阻,收盘价低于开盘价,上方有阻力,可视为弱势。
那么简单定义为:(high - close)/close > 7%,(high - open)/open > 7% ,可能不是太精确,这里只是为了演示,忽略一些具体细节。
简单理解就是,当天最高价比收盘价,开盘价高得多。
长上影匹配函数,简单,只有一行就搞定。
def long_up_shadow(o,c,h,l):
return True if (h-c)/c >=0.07 and (h-o)/o>=0.07 else False
然后把这个长上影函数应用到上面的同和药业。
得到的效果:
df = pd.read_excel("同和药业k.xlsx")
count_num = []
for row,item in df.iterrows():
if long_up_shadow(item['open'],item['close'],item['high'],item['low']):
count_num.append(row)
plot_image(df,count_num)
图里面的4个箭头长上影是python自动标上去的,然后对着数据到同花顺核对一下,都是满足长度大于7%的。
可以看到在3月18日和28日的两根长上影之后,同和药业的股价走了一波趋势下跌。【PS:选这个股票并没有刻意去挑选,在集思录默认排名,找了一个跌幅第一个转债的正股就把代码拷贝过来测试】
那么,有这么多的形态,难道每一个都要自己写代码筛选形态吗? 不用哈,因为已经有人写了第三方的库,你只需要调用就可以了。
截取的部分函数名与说明
比如,像两只乌鸦,描述起来都感觉有点复杂,自己手撸代码都会搞出一堆bug。而用taLib这个库,你只需要一行调用代码,就可以完成这些复杂的形态筛选工作。
示例代码:
df['tow_crows'] = talib.CDL2CROWS(df['open'].values, df['high'].values, df['low'].values, df['close'].values)
pattern = df[(df['tow_crows'] == 100) | (df['tow_crows'] == -100)]
上面得到的pattern就是满足要求的形态,如CDL2CROWS 两只乌鸦。测试的个股是歌尔股份2020的日K线。
虽然我不知道两只乌鸦是什么玩意,但是可以通过遍历某个长周期(5-10年)下的全部A股数据,通过数据证伪,统计这个形态过后的一周或一个月(个人随意设定)涨跌幅,来证伪这个形态的有效性。
如果得到的是一个50%概率涨跌概况,那说明这个指标形态只是个游走在随机概率的指标,并不能作为一个有效指标参考。
(未完待续) 查看全部
对于一些做股票技术分析的投资者来说,对常见的k线形态应该都不陌生,比如十字星,红三兵,头肩顶(底),岛型反转,吊颈线,两只乌鸦,三只乌鸦,四只乌鸦(哈)

做价投的投资者可能会对这些划线的嗤之以鼻,而短线操盘者却有可能把它奉为圭臬,以之作为买卖标准。
海乃百川,兼听则明,笔者认为多吸收不同的观点与技术,可以更加全面的加深投资认知。你画的圆圈越大,圆圈外的未知空间也越大。
本文介绍使用python对A股市场的股票(转债也可以)的K线进行识别,然后回测某个形态出现后接下来的涨跌幅,还可以通过设定的形态进行选股。
举个例子,我们可以统计所有个股出现了“早晨之星“这一形态后,一周后甚至一个月后,个股是涨了还是跌了,从大量结果中统计出一些有意义的结果。
为了便于验证查看结果图形,我们先介绍如何使用python来画股票K线图。
有数据之后,剩下画图是很简单的,很多第三方的库已经封装好了各种蜡烛图绘制函数。我们要做只是传入每天开,收盘价,以及最高最低价。
获取股票的数据
市面有不少第三方的库可以获取股票和可转债的日线数据,比如tushare和akshare。本文以股票数据为例。
以akshare为例,代码如下所示:
# pip install akshare
import akshare as ak
def get_k_line(code="sz002241"): #
df = ak.stock_zh_a_daily(symbol=code, start_date="20220101", end_date="20220515",
adjust="qfq")
# 这个函数只适合取股票数据,转债会报错,转债的日线数据可以使用其他函数,这里选择股价前复权
df.to_excel("同和药业k.xlsx")
如上面代码所示,我们使用stock_zh_a_daily方法获取一段时间的数据,这里的日期可以根据你的需求进行调整,比如设置start_date=“20200101”,end_date=“20220515”,就可以获取一年时间段的股票数据。
而股票的代码有sh与sz之分,sz代表深市的股票,所有深市的股票前面都必须带上sz,比如这里的同和药业,就是sz002241。
同样的,sh是上证交易所的股票,所有上证的股票前面必须带上sh。
这里,我们来看看获取的同和药业股票数据格式,如下图所示:
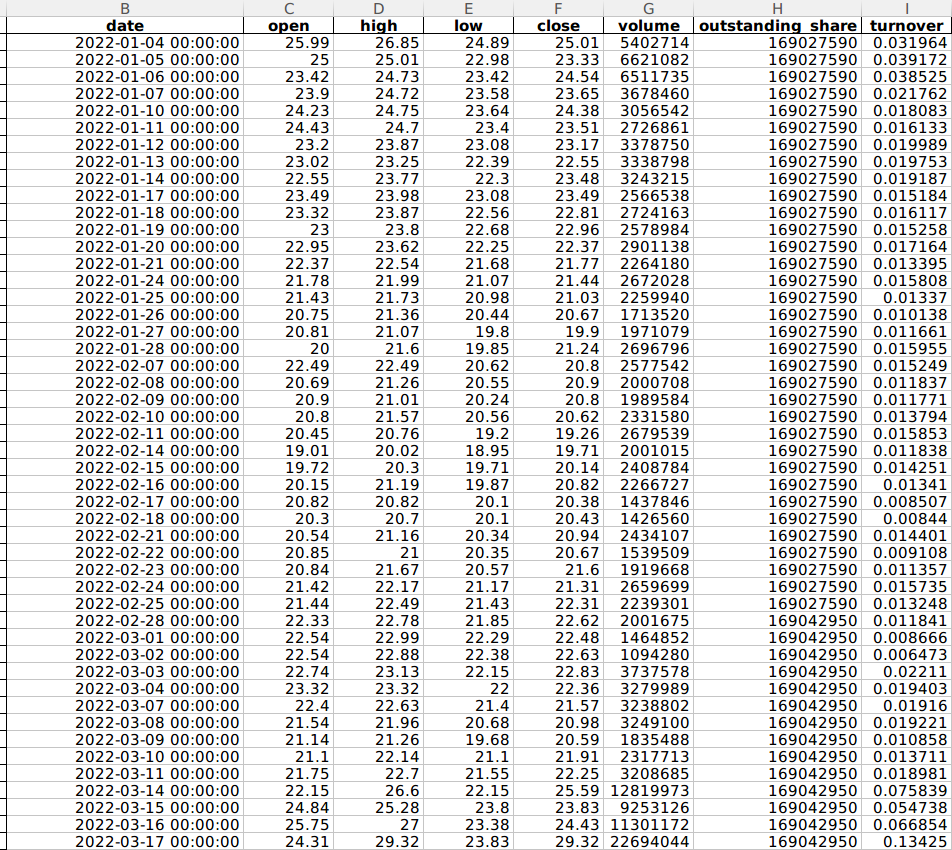
date:交易日期
open:代表开盘价
high:当天最高价
low:当天最低价
close:当天收盘价
volume:当天成交量(元)
outstanding_share:流动股本(股)
turnover:换手率
既然已经拿到了数据,下面我们来绘制K线图。
绘制K线图
在python中,绘制K线图需要用到mpl_finance库,而这个库提供了4种方式绘制K线图,这里我们介绍其中的一种,代码如下所示:
import mpl_finance as mpf
import matplotlib.pyplot as plt
import pandas as pd
#创建绘图的基本参数
fig=plt.figure(figsize=(12, 8))
ax=fig.add_subplot(111)
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
#显示出来
plt.show()
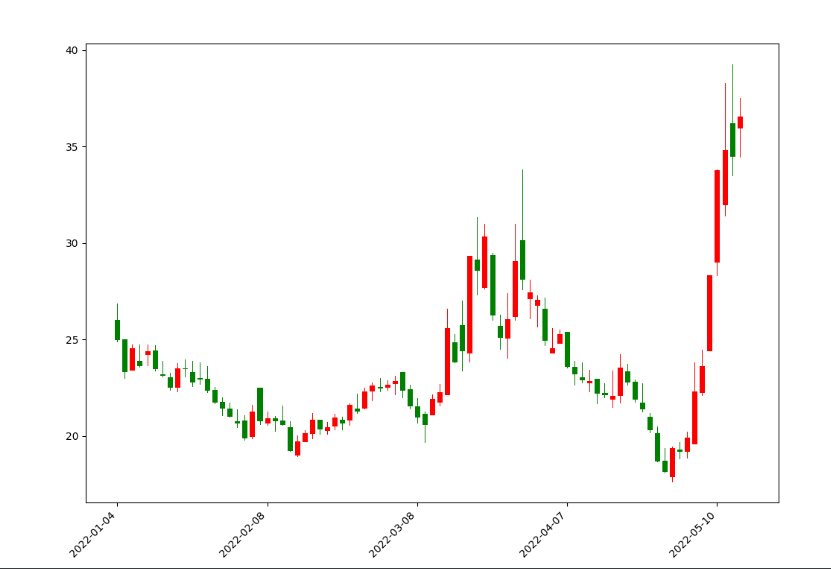
运行此段代码后,会显示如下效果图:
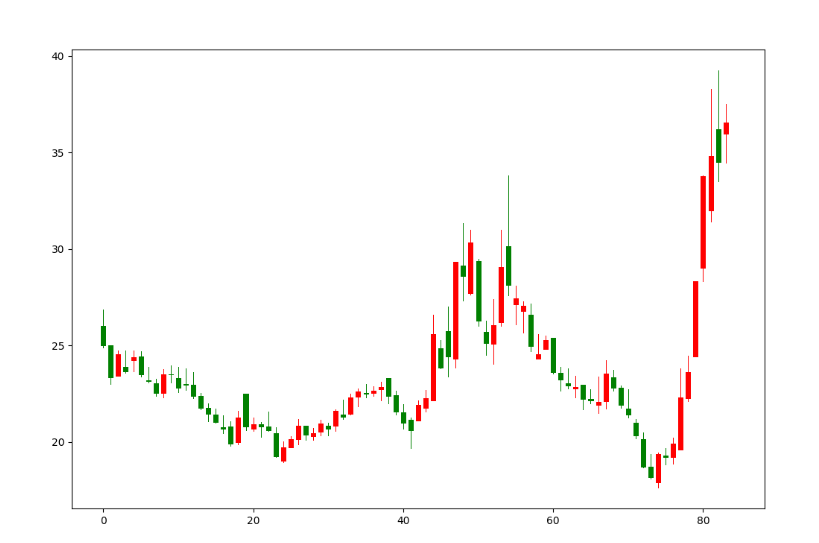
和东财上的同和药业的k线图基本一致的。
不过,这个K线图有一个问题,就是X坐标轴并不是显示的时间,而是数字,这是因为我们绘制K线图的方法,并没有提供X轴的参数,那怎么让下面的数字替换为时间呢?
我们先来看一段代码:
import matplotlib.ticker as ticker
#将股票时间转换为标准时间,不带时分秒的数据
def date_to_num(dates):
num_time = []
for date in dates:
date_time = datetime.strptime(date, '%Y-%m-%d')
num_date = date2num(date_time)
num_time.append(num_date)
return num_time
#创建绘图的基本参数
fig=plt.figure(figsize=(12, 8))
ax=fig.add_subplot(111)
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
df['date'] = pd.to_datetime(df['date'])
df['date'] = df['date'].apply(lambda x: x.strftime('%Y-%m-%d'))
def format_date(x, pos=None):
if x < 0 or x > len(df['date']) - 1:
return ''
return df['date'][int(x)]
ax.xaxis.set_major_formatter(ticker.FuncFormatter(format_date))
plt.setp(plt.gca().get_xticklabels(), rotation=45, horizontalalignment='right')
#显示出来
plt.show()
这里,我们定义了2个方法:第1个方法date_to_num主要的作用就是将获取的时间数据转换为标准的日期数据;第2个方法,就是根据X的数值替换时间值。
其中,set_major_formatter方法是将数值替换为时间值的操作库,而plt.setup的功能就是设置X轴的标签倾斜45度以及右对齐。运行之后,我们的K线图就显示的非常完美了,如下图所示:
均线图
虽然我们实现了K线图,但是有没有发现,其实大多数的股票交易软件K线图上面其实还标记有均线,比如常用的有5日均线,10日均线,30均线。
所以,我们需要将均线一起添加到我们的K线图之上。
计算均线的方式如下:
df["SMA5"] = df["close"].rolling(5).mean()
df["SMA10"] = df["close"].rolling(10).mean()
df["SMA30"] = df["close"].rolling(30).mean()
3行代码就可以获取到股票的均线值。
接着,我们可以使用上面的ax进行绘制均线了,
添加的代码如下所示:
ax.plot(np.arange(0, len(df)), df['SMA5']) # 绘制5日均线
ax.plot(np.arange(0, len(df)), df['SMA10']) # 绘制10日均线
ax.plot(np.arange(0, len(df)), df['SMA30']) # 绘制30日均线
这里,同样将X轴设置为数字,将这两段代码添加到上面的K线图代码中,自然也会将X轴替换为时间。运行之后,显示效果如下图所示:
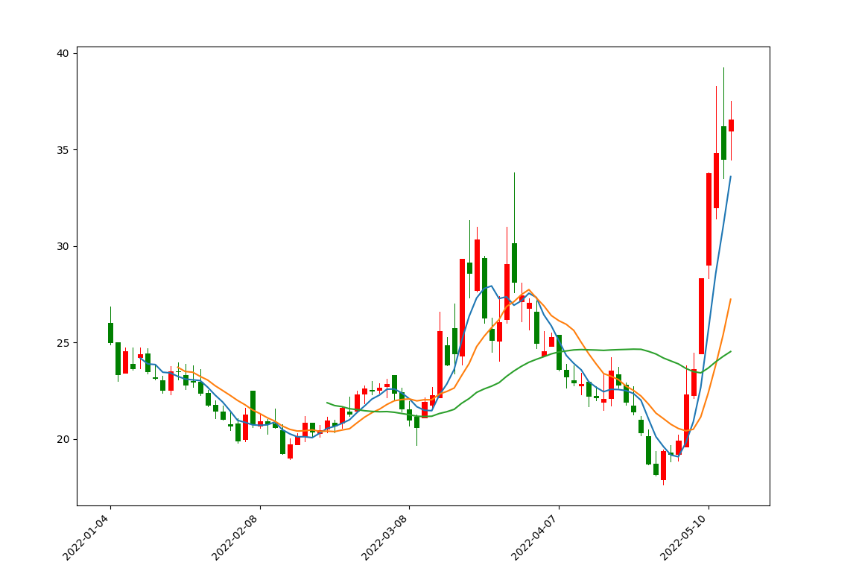
这里5日均线为蓝色,10日均线为橙色,30日均线为绿色,如果需要自己设置颜色,可以在每条均线的的绘制方法中加入color参数。
细心的读者肯定发现30日均线只有最后一小段,这是因为前29日不够30日是算不出均线的,同样的5,10日均线也是如此。
成交量
最后,我们还需要绘制成交量。在多数的股票交易软件中,上面是K线图,一般下面对应的就是成交量,这样对比起来看,往往能直观的看到数据的变化。
但是,因为上面有个K线图,那么同一个画布中就有了2个图片,且它们共用一个X轴,那么我们需要更改一下基本的参数,
代码如下所示:
import mpl_finance as mpf
import matplotlib.pyplot as plt
import pandas as pd
import matplotlib.ticker as ticker
import numpy as np
#创建绘图的基本参数
fig, axes = plt.subplots(2, 1, sharex=True, figsize=(15, 10))
ax1, ax2 = axes.flatten()
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax1, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
df['date'] = pd.to_datetime(df['date'])
df['date'] = df['date'].apply(lambda x: x.strftime('%Y-%m-%d'))
def format_date(x, pos=None):
if x < 0 or x > len(df['date']) - 1:
return ''
return df['date'][int(x)]
df["SMA5"] = df["close"].rolling(5).mean()
df["SMA10"] = df["close"].rolling(10).mean()
df["SMA30"] = df["close"].rolling(30).mean()
ax1.plot(np.arange(0, len(df)), df['SMA5']) # 绘制5日均线
ax1.plot(np.arange(0, len(df)), df['SMA10']) # 绘制10日均线
ax1.plot(np.arange(0, len(df)), df['SMA30']) # 绘制30日均线
ax1.xaxis.set_major_formatter(ticker.FuncFormatter(format_date))
plt.setp(plt.gca().get_xticklabels(), rotation=45, horizontalalignment='right')
#显示出来
plt.show()
这里,我们将绘图的画布设置为2行1列。同时,将上面绘制的所有数据都更改为ax1,这样均线与K线图会绘制到第一个子图中。
接着,我们需要绘制成交量,但是我们知道,一般股票交易软件都将上涨的那天成交量设置为红色,而将下跌的成交量绘制成绿色。所以,首先我们要做的是将获取的股票数据根据当天的涨跌情况进行分类。
具体代码如下:
red_pred = np.where(df["close"] > df["open"], df["volume"], 0)
blue_pred = np.where(df["close"] < df["open"], df["volume"], 0)
如上面代码所示,我们通过np.where(condition, x, y)筛选数据。这里满足条件condition,输出X,不满足条件输出Y,这样我们就将涨跌的成交量数据进行了分类。
最后,我们直接通过柱状图方法绘制成交量,
具体代码如下所示:
ax2.bar(np.arange(0, len(df)), red_pred, facecolor="red")
ax2.bar(np.arange(0, len(df)), blue_pred, facecolor="blue")
将这4行代码,全部加入到plt.show()代码的前面即可。
运行之后,输出的效果图如下:
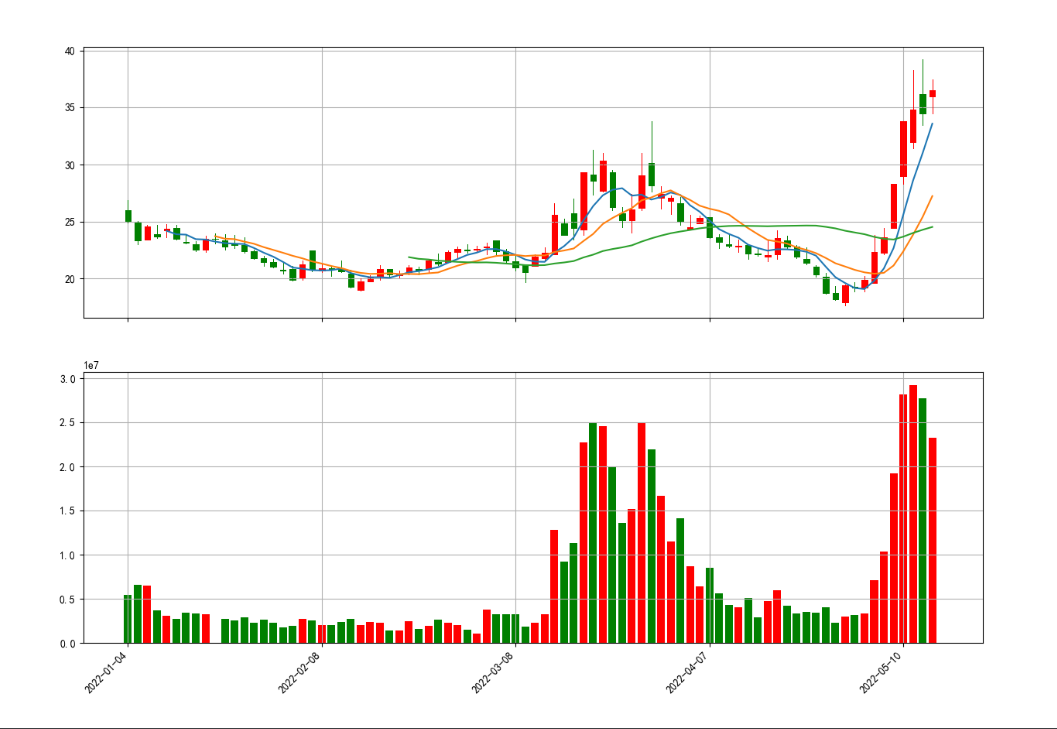
根据定义编写形态
接下来,我们根据定义来构造一个简单的形态函数,比如长上影线。
上影线

根据网络上的定义:
⑤上影阳线:开盘后价格冲高回落,涨势受阻,虽然收盘价仍高于开盘价,但上方有阻力,可视为弱势。
⑥上影阴线:开盘后价格冲高受阻,涨势受阻,收盘价低于开盘价,上方有阻力,可视为弱势。

那么简单定义为:(high - close)/close > 7%,(high - open)/open > 7% ,可能不是太精确,这里只是为了演示,忽略一些具体细节。
简单理解就是,当天最高价比收盘价,开盘价高得多。
长上影匹配函数,简单,只有一行就搞定。
def long_up_shadow(o,c,h,l):
return True if (h-c)/c >=0.07 and (h-o)/o>=0.07 else False
然后把这个长上影函数应用到上面的同和药业。
得到的效果:
df = pd.read_excel("同和药业k.xlsx")
count_num = []
for row,item in df.iterrows():
if long_up_shadow(item['open'],item['close'],item['high'],item['low']):
count_num.append(row)
plot_image(df,count_num)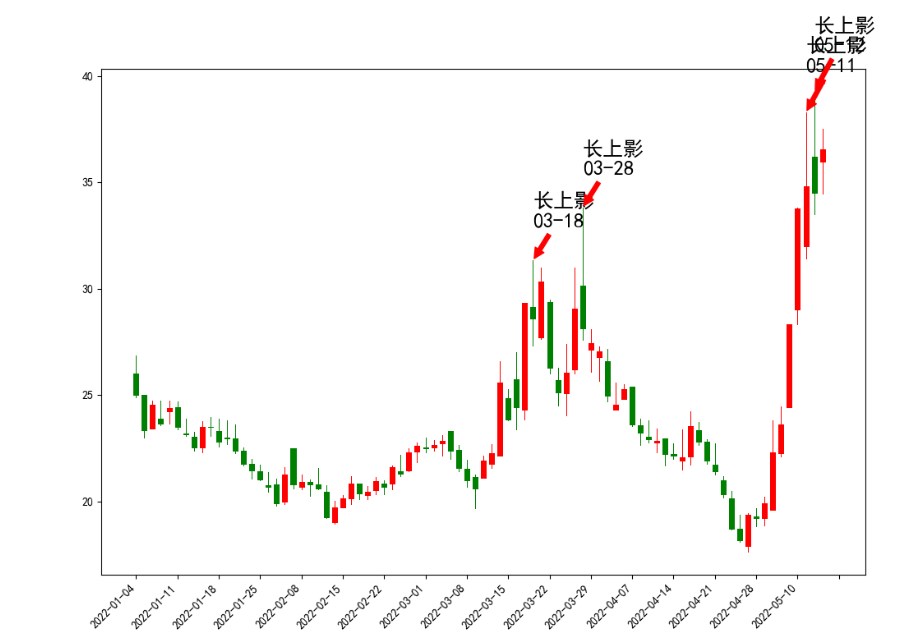
图里面的4个箭头长上影是python自动标上去的,然后对着数据到同花顺核对一下,都是满足长度大于7%的。
可以看到在3月18日和28日的两根长上影之后,同和药业的股价走了一波趋势下跌。【PS:选这个股票并没有刻意去挑选,在集思录默认排名,找了一个跌幅第一个转债的正股就把代码拷贝过来测试】
那么,有这么多的形态,难道每一个都要自己写代码筛选形态吗? 不用哈,因为已经有人写了第三方的库,你只需要调用就可以了。

截取的部分函数名与说明
比如,像两只乌鸦,描述起来都感觉有点复杂,自己手撸代码都会搞出一堆bug。而用taLib这个库,你只需要一行调用代码,就可以完成这些复杂的形态筛选工作。
示例代码:
df['tow_crows'] = talib.CDL2CROWS(df['open'].values, df['high'].values, df['low'].values, df['close'].values)
pattern = df[(df['tow_crows'] == 100) | (df['tow_crows'] == -100)]
上面得到的pattern就是满足要求的形态,如CDL2CROWS 两只乌鸦。测试的个股是歌尔股份2020的日K线。
虽然我不知道两只乌鸦是什么玩意,但是可以通过遍历某个长周期(5-10年)下的全部A股数据,通过数据证伪,统计这个形态过后的一周或一个月(个人随意设定)涨跌幅,来证伪这个形态的有效性。
如果得到的是一个50%概率涨跌概况,那说明这个指标形态只是个游走在随机概率的指标,并不能作为一个有效指标参考。
(未完待续)
B站批量下载某个UP主的所有视频
python • 李魔佛 发表了文章 • 0 个评论 • 2241 次浏览 • 2022-05-21 18:48
使用python实现
https://github.com/Rockyzsu/bilibili
B站视频下载
自动批量下载B站一个系列的视频
下载某个UP主的所有视频
使用:
下载you-get库,git clone https://github.com/soimort/you-get.git 复制其本地路径,比如/root/you-get/you-get
初次运行,删除history.db 文件, 修改配置文件config.py
START=1 # 下载系列视频的 第一个
END=1 # 下载系列视频的最后一个 , 比如一个系列教程有30个视频, start=5 ,end = 20 下载从第5个到第20个
ID='BV1oK411L7au' # 视频的ID
YOU_GET_PATH='/home/xda/othergit/you-get/you-get' # 你的you-get路径
MINS=1 # 每次循环等待1分钟
user_id = '518973111' # UP主的ID
total_page = 3 # up主的视频的页数
执行 python downloader.py ,进行下载循环
python people.py ,把某个up主的视频链接加入到待下载队列
python add_data.py --id=BV1oK411L7au --start=4 --end=8 下载视频id为BV1oK411L7au的系列教程,从第4开始,到第8个结束,如果只有一个的话,start和end设为1即可。
可以不断地往队列里面添加下载链接。
主要代码:
# @Time : 2019/1/28 14:19
# @File : youtube_downloader.py
import logging
import os
import subprocess
import datetime
import sqlite3
import time
from config import YOU_GET_PATH,MINS
CMD = 'python {} {}'
filename = 'url.txt'
class SQLite():
def __init__(self):
self.conn = sqlite3.connect('history.db')
self.cursor = self.conn.cursor()
self.create_table()
def create_table(self):
create_sql = 'create table if not exists tb_download (url varchar(100),status tinyint,crawltime datetime)'
create_record_tb = 'create table if not exists tb_record (idx varchar(100) PRIMARY KEY,start tinyint,end tinyint,status tinyint)'
self.cursor.execute(create_record_tb)
self.conn.commit()
self.cursor.execute(create_sql)
self.conn.commit()
def exists(self,url):
querySet = 'select * from tb_download where url = ? and status = 1'
self.cursor.execute(querySet,(url,))
ret = self.cursor.fetchone()
return True if ret else False
def insert_history(self,url,status):
query = 'select * from tb_download where url=?'
self.cursor.execute(query,(url,))
ret = self.cursor.fetchone()
current = datetime.datetime.now()
if ret:
insert_sql='update tb_download set status=?,crawltime=? where url = ?'
args=(status,status,current,url)
else:
insert_sql = 'insert into tb_download values(?,?,?)'
args=(url,status,current)
try:
self.cursor.execute(insert_sql,args)
except:
self.conn.rollback()
return False
else:
self.conn.commit()
return True
def get(self):
sql = 'select idx,start,end from tb_record where status=0'
self.cursor.execute(sql)
ret= self.cursor.fetchone()
return ret
def set(self,idx):
print('set status =1')
sql='update tb_record set status=1 where idx=?'
self.cursor.execute(sql,(idx,))
self.conn.commit()
def llogger(filename):
logger = logging.getLogger(filename) # 不加名称设置root logger
logger.setLevel(logging.DEBUG) # 设置输出级别
formatter = logging.Formatter(
'[%(asctime)s][%(filename)s][line: %(lineno)d]\[%(levelname)s] ## %(message)s)',
datefmt='%Y-%m-%d %H:%M:%S')
# 使用FileHandler输出到文件
prefix = os.path.splitext(filename)[0]
fh = logging.FileHandler(prefix + '.log')
fh.setLevel(logging.DEBUG)
fh.setFormatter(formatter)
# 使用StreamHandler输出到屏幕
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG)
ch.setFormatter(formatter)
# 添加两个Handler
logger.addHandler(ch)
logger.addHandler(fh)
return logger
logger = llogger('download.log')
sql_obj = SQLite()
def run():
while 1:
result = sql_obj.get()
print(result)
if result:
idx=result[0]
start=result[1]
end=result[2]
try:
download_bilibili(idx,start,end)
except:
pass
else:
sql_obj.set(idx)
else:
time.sleep(MINS*60)
def download_bilibili(id,start_page,total_page):
global doc
bilibili_url = 'https://www.bilibili.com/video/{}?p={}'
for i in range(start_page, total_page+1):
next_url = bilibili_url.format(id, i)
if sql_obj.exists(next_url):
print('have download')
continue
try:
command = CMD.format(YOU_GET_PATH, next_url)
p = subprocess.Popen(command, stdout=subprocess.PIPE, stderr=subprocess.PIPE,
shell=True)
output, error = p.communicate()
except Exception as e:
print('has execption')
sql_obj.insert_history(next_url,status=0)
logger.error(e)
continue
else:
output_str = output.decode()
if len(output_str) == 0:
sql_obj.insert_history(next_url,status=0)
logger.info('下载失败')
continue
logger.info('{} has been downloaded !'.format(next_url))
sql_obj.insert_history(next_url,status=1)
run()
查看全部

使用python实现
https://github.com/Rockyzsu/bilibili
B站视频下载
自动批量下载B站一个系列的视频
下载某个UP主的所有视频
使用:
下载you-get库,git clone https://github.com/soimort/you-get.git 复制其本地路径,比如/root/you-get/you-get
初次运行,删除history.db 文件, 修改配置文件config.py
START=1 # 下载系列视频的 第一个
END=1 # 下载系列视频的最后一个 , 比如一个系列教程有30个视频, start=5 ,end = 20 下载从第5个到第20个
ID='BV1oK411L7au' # 视频的ID
YOU_GET_PATH='/home/xda/othergit/you-get/you-get' # 你的you-get路径
MINS=1 # 每次循环等待1分钟
user_id = '518973111' # UP主的ID
total_page = 3 # up主的视频的页数
执行 python downloader.py ,进行下载循环
python people.py ,把某个up主的视频链接加入到待下载队列
python add_data.py --id=BV1oK411L7au --start=4 --end=8 下载视频id为BV1oK411L7au的系列教程,从第4开始,到第8个结束,如果只有一个的话,start和end设为1即可。
可以不断地往队列里面添加下载链接。
主要代码:
# @Time : 2019/1/28 14:19
# @File : youtube_downloader.py
import logging
import os
import subprocess
import datetime
import sqlite3
import time
from config import YOU_GET_PATH,MINS
CMD = 'python {} {}'
filename = 'url.txt'
class SQLite():
def __init__(self):
self.conn = sqlite3.connect('history.db')
self.cursor = self.conn.cursor()
self.create_table()
def create_table(self):
create_sql = 'create table if not exists tb_download (url varchar(100),status tinyint,crawltime datetime)'
create_record_tb = 'create table if not exists tb_record (idx varchar(100) PRIMARY KEY,start tinyint,end tinyint,status tinyint)'
self.cursor.execute(create_record_tb)
self.conn.commit()
self.cursor.execute(create_sql)
self.conn.commit()
def exists(self,url):
querySet = 'select * from tb_download where url = ? and status = 1'
self.cursor.execute(querySet,(url,))
ret = self.cursor.fetchone()
return True if ret else False
def insert_history(self,url,status):
query = 'select * from tb_download where url=?'
self.cursor.execute(query,(url,))
ret = self.cursor.fetchone()
current = datetime.datetime.now()
if ret:
insert_sql='update tb_download set status=?,crawltime=? where url = ?'
args=(status,status,current,url)
else:
insert_sql = 'insert into tb_download values(?,?,?)'
args=(url,status,current)
try:
self.cursor.execute(insert_sql,args)
except:
self.conn.rollback()
return False
else:
self.conn.commit()
return True
def get(self):
sql = 'select idx,start,end from tb_record where status=0'
self.cursor.execute(sql)
ret= self.cursor.fetchone()
return ret
def set(self,idx):
print('set status =1')
sql='update tb_record set status=1 where idx=?'
self.cursor.execute(sql,(idx,))
self.conn.commit()
def llogger(filename):
logger = logging.getLogger(filename) # 不加名称设置root logger
logger.setLevel(logging.DEBUG) # 设置输出级别
formatter = logging.Formatter(
'[%(asctime)s][%(filename)s][line: %(lineno)d]\[%(levelname)s] ## %(message)s)',
datefmt='%Y-%m-%d %H:%M:%S')
# 使用FileHandler输出到文件
prefix = os.path.splitext(filename)[0]
fh = logging.FileHandler(prefix + '.log')
fh.setLevel(logging.DEBUG)
fh.setFormatter(formatter)
# 使用StreamHandler输出到屏幕
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG)
ch.setFormatter(formatter)
# 添加两个Handler
logger.addHandler(ch)
logger.addHandler(fh)
return logger
logger = llogger('download.log')
sql_obj = SQLite()
def run():
while 1:
result = sql_obj.get()
print(result)
if result:
idx=result[0]
start=result[1]
end=result[2]
try:
download_bilibili(idx,start,end)
except:
pass
else:
sql_obj.set(idx)
else:
time.sleep(MINS*60)
def download_bilibili(id,start_page,total_page):
global doc
bilibili_url = 'https://www.bilibili.com/video/{}?p={}'
for i in range(start_page, total_page+1):
next_url = bilibili_url.format(id, i)
if sql_obj.exists(next_url):
print('have download')
continue
try:
command = CMD.format(YOU_GET_PATH, next_url)
p = subprocess.Popen(command, stdout=subprocess.PIPE, stderr=subprocess.PIPE,
shell=True)
output, error = p.communicate()
except Exception as e:
print('has execption')
sql_obj.insert_history(next_url,status=0)
logger.error(e)
continue
else:
output_str = output.decode()
if len(output_str) == 0:
sql_obj.insert_history(next_url,status=0)
logger.info('下载失败')
continue
logger.info('{} has been downloaded !'.format(next_url))
sql_obj.insert_history(next_url,status=1)
run()
python3的map是迭代器,不用for循环或者next触发是不会执行的
python • 李魔佛 发表了文章 • 0 个评论 • 1244 次浏览 • 2022-05-21 17:59
def update_data(id,start,end):
status=0
conn = sqlite3.connect('history.db')
cursor = conn.cursor()
insert_sql ='insert into tb_record values(?,?,?,?)'
try:
cursor.execute(insert_sql,(id,start,end,status))
except Exception as e:
print(e)
print('Error')
else:
conn.commit()
print("successfully insert")
bv_list = []
for i in range(1, total_page + 1):
bv_list.extend(visit(i))
print(bv_list)
map(lambda x:update_data(x,1,1),bv_list)
作用很简单,就是拿到列表后用map放入到sqlite里面。
但是上面的代码并不起作用。
因为map只是定义了一个迭代器,并没有被触发。
可以加一个list(map(lambda x:update_data(x,1,1),bv_list))
这样就可以执行了。 查看全部
def update_data(id,start,end):
status=0
conn = sqlite3.connect('history.db')
cursor = conn.cursor()
insert_sql ='insert into tb_record values(?,?,?,?)'
try:
cursor.execute(insert_sql,(id,start,end,status))
except Exception as e:
print(e)
print('Error')
else:
conn.commit()
print("successfully insert")
bv_list = []
for i in range(1, total_page + 1):
bv_list.extend(visit(i))
print(bv_list)
map(lambda x:update_data(x,1,1),bv_list)
作用很简单,就是拿到列表后用map放入到sqlite里面。
但是上面的代码并不起作用。
因为map只是定义了一个迭代器,并没有被触发。
可以加一个list(map(lambda x:update_data(x,1,1),bv_list))
这样就可以执行了。
dataframe如何 遍历所有的列?
python • 李魔佛 发表了文章 • 0 个评论 • 2005 次浏览 • 2022-05-21 02:16
可以使用df.items()
Python pandas.DataFrame.items用法及代码示例
用法:
DataFrame.items()
迭代(列名,系列)对。
遍历 DataFrame 列,返回一个包含列名和内容的元组作为一个系列。
生成(Yield):
label:对象
被迭代的 DataFrame 的列名。
content:Series
属于每个标签的列条目,作为一个系列。
例子:
>>> df = pd.DataFrame({'species':['bear', 'bear', 'marsupial'],
... 'population':[1864, 22000, 80000]},
... index=['panda', 'polar', 'koala'])
>>> df
species population
panda bear 1864
polar bear 22000
koala marsupial 80000
>>> for label, content in df.items():
... print(f'label:{label}')
... print(f'content:{content}', sep='\n')
...
label:species
content:
panda bear
polar bear
koala marsupial
Name:species, dtype:object
label:population
content:
panda 1864
polar 22000
koala 80000
Name:population, dtype:int64 查看全部
可以使用df.items()
Python pandas.DataFrame.items用法及代码示例
用法:
DataFrame.items()
迭代(列名,系列)对。
遍历 DataFrame 列,返回一个包含列名和内容的元组作为一个系列。
生成(Yield):
label:对象
被迭代的 DataFrame 的列名。
content:Series
属于每个标签的列条目,作为一个系列。
例子:
>>> df = pd.DataFrame({'species':['bear', 'bear', 'marsupial'],
... 'population':[1864, 22000, 80000]},
... index=['panda', 'polar', 'koala'])
>>> df
species population
panda bear 1864
polar bear 22000
koala marsupial 80000
>>> for label, content in df.items():
... print(f'label:{label}')
... print(f'content:{content}', sep='\n')
...
label:species
content:
panda bear
polar bear
koala marsupial
Name:species, dtype:object
label:population
content:
panda 1864
polar 22000
koala 80000
Name:population, dtype:int64
ubuntu20 conda安装python ta-lib 股票分析库
Linux • 李魔佛 发表了文章 • 0 个评论 • 1720 次浏览 • 2022-05-20 23:11
$ conda install -c quantopian ta-lib=0.4.9一般而说,上面的会失败,可以按照下面的方法:2. 自己手工编译安装,适合需要自己修改内部的一些函数
a) 下载ta-lib的源码
$ wget [url=http://prdownloads.sourceforge ... ar.gz(]http://prdownloads.sourceforge ... ar.gz[/url] 如果无法下载的话,可以直接复制到浏览器下载,我的wget就是无法下载,估计有反盗链设计了
prdownloads.sourceforge.net/ta-lib/ta-lib-0.4.0-src.tar.gz或者文末也可以获取。
$ untar and cd
$ ./configure --prefix=/usr
$ make
$ sudo make install
假如之前用anaconda安装过,需要将生成的库替换到anaconda安装的目录
$ cp /usr/lib/libta_lib* /home/user/anaconda2/lib/
b) 下载ta-lib的Python wrapper
pip install ta-lib或者
$ git clone https://github.com/mrjbq7/ta-lib.git
$ cd ta-lib
$ python setup.py install 最后在Python里面 import talib没有报错就安装成功了
在公众号后台留言: talib 就可以获取文件。
查看全部
. 使用 Anaconda 里面的conda 工具
$ conda install -c quantopian ta-lib=0.4.9
一般而说,上面的会失败,可以按照下面的方法:
2. 自己手工编译安装,适合需要自己修改内部的一些函数
a) 下载ta-lib的源码
$ wget [url=http://prdownloads.sourceforge ... ar.gz(]http://prdownloads.sourceforge ... ar.gz[/url]
如果无法下载的话,可以直接复制到浏览器下载,我的wget就是无法下载,估计有反盗链设计了
prdownloads.sourceforge.net/ta-lib/ta-lib-0.4.0-src.tar.gz
或者文末也可以获取。
$ untar and cd
$ ./configure --prefix=/usr
$ make
$ sudo make install
假如之前用anaconda安装过,需要将生成的库替换到anaconda安装的目录
$ cp /usr/lib/libta_lib* /home/user/anaconda2/lib/
b) 下载ta-lib的Python wrapper
pip install ta-lib
或者
$ git clone https://github.com/mrjbq7/ta-lib.git
$ cd ta-lib
$ python setup.py install
最后在Python里面 import talib没有报错就安装成功了
在公众号后台留言: talib 就可以获取文件。

Ubuntu20安装搜狗输入法 (自带的智能拼音太烂了)
Linux • 李魔佛 发表了文章 • 0 个评论 • 1776 次浏览 • 2022-05-20 13:49
Ubuntu20.04安装搜狗输入法步骤
1、更新源
在终端执行 sudo apt update
2、安装fcitx输入法框架
\1. 在终端输入 sudo apt install fcitx
\2. 设置fcitx为系统输入法
点击左下角菜单选择语言支持,将语言选择为fcitx(如下图二)
\3. 设置fcitx开机自启动
在终端执行sudo cp /usr/share/applications/fcitx.desktop /etc/xdg/autostart/
\4. 卸载系统ibus输入法框架
在终端执行 sudo apt purge ibus
3、安装搜狗输入法
\1. 在官网下载搜狗输入法安装包,并安装,安装命令 sudo dpkg -i 安装包名
\2. 安装输入法依赖
在终端执行
sudo apt install libqt5qml5 libqt5quick5 libqt5quickwidgets5 qml-module-qtquick2
sudo apt install libgsettings-qt1
4、重启电脑、调出输入法
1.重启电脑
2.查看右上角,可以看到“搜狗”字样,在输入窗口即可且出搜狗输入法。
\3. 没有“搜狗”字样,选择配置,将搜狗加入输入法列表即可
至此,搜狗输入法安装完毕 查看全部

Ubuntu20.04安装搜狗输入法步骤
1、更新源
在终端执行 sudo apt update
2、安装fcitx输入法框架
\1. 在终端输入 sudo apt install fcitx
\2. 设置fcitx为系统输入法
点击左下角菜单选择语言支持,将语言选择为fcitx(如下图二)
\3. 设置fcitx开机自启动
在终端执行sudo cp /usr/share/applications/fcitx.desktop /etc/xdg/autostart/
\4. 卸载系统ibus输入法框架
在终端执行 sudo apt purge ibus
3、安装搜狗输入法
\1. 在官网下载搜狗输入法安装包,并安装,安装命令 sudo dpkg -i 安装包名
\2. 安装输入法依赖
在终端执行
sudo apt install libqt5qml5 libqt5quick5 libqt5quickwidgets5 qml-module-qtquick2
sudo apt install libgsettings-qt1
4、重启电脑、调出输入法
1.重启电脑
2.查看右上角,可以看到“搜狗”字样,在输入窗口即可且出搜狗输入法。
\3. 没有“搜狗”字样,选择配置,将搜狗加入输入法列表即可
至此,搜狗输入法安装完毕
国金证券可转债费率 最低是多少?
券商万一免五 • 绫波丽 发表了文章 • 0 个评论 • 2025 次浏览 • 2022-05-20 11:20
也就是你 单笔买入沪市可转债 10万,就收4.1块钱,如果买入5千元,就收2毛0.5分钱。 非常低,适合日内做T
除此之外,不会加收其他费用,买卖都是一样,不象股票那样,除非给券商交易佣金,还要给交易所印花税,过户费,股民就像个过街肥羊一样,谁都想要来咬一口。
一般沪市转债的代码是11开头的,深市转债的代码是12开头的。
目前本营业部的股票费率是万1,比你自己在官方app开通要便宜得多。因为我们会帮你们调佣。
需要开通国金证券的,可以扫描下面微信二维码: 查看全部

目前笔者这里的营业部的国金证券的可转债(新规)费率是 沪十万分之4.1,深市 十万分之4。
也就是你 单笔买入沪市可转债 10万,就收4.1块钱,如果买入5千元,就收2毛0.5分钱。 非常低,适合日内做T
除此之外,不会加收其他费用,买卖都是一样,不象股票那样,除非给券商交易佣金,还要给交易所印花税,过户费,股民就像个过街肥羊一样,谁都想要来咬一口。
一般沪市转债的代码是11开头的,深市转债的代码是12开头的。
目前本营业部的股票费率是万1,比你自己在官方app开通要便宜得多。因为我们会帮你们调佣。
需要开通国金证券的,可以扫描下面微信二维码:

shell批量导入mysql数据库 附代码
Linux • 李魔佛 发表了文章 • 0 个评论 • 1293 次浏览 • 2022-05-19 17:52
restore_db=(db_bond_daily.sql db_bond_history.sql)
里面,比如这里的 db_bond_daily.sql db_bond_history.sql
#!/bin/bash
# 批量备份数据库
MYSQL_USER=root
MYSQL_PASSWORD=123456 # 改为你的mysql密码
HOST=127.0.0.1
restore_db=(db_bond_daily.sql db_bond_history.sql) # sql 文件列表
for i in ${restore_db[*]}
do
name=(${i//./ }) # 切割名字
mysql -h$HOST -u$MYSQL_USER -p$MYSQL_PASSWORD ${name[0]}<${i}
done
查看全部
restore_db=(db_bond_daily.sql db_bond_history.sql)
里面,比如这里的 db_bond_daily.sql db_bond_history.sql
#!/bin/bash
# 批量备份数据库
MYSQL_USER=root
MYSQL_PASSWORD=123456 # 改为你的mysql密码
HOST=127.0.0.1
restore_db=(db_bond_daily.sql db_bond_history.sql) # sql 文件列表
for i in ${restore_db[*]}
do
name=(${i//./ }) # 切割名字
mysql -h$HOST -u$MYSQL_USER -p$MYSQL_PASSWORD ${name[0]}<${i}
done
腾讯云轻量服务器使用mysqldump导出数据 导致进程被杀
数据库 • 李魔佛 发表了文章 • 0 个评论 • 1202 次浏览 • 2022-05-18 19:43
稍微密集一点,直接被杀掉。
在方面放mysql服务,简直就是煞笔行为。
稍微密集一点,直接被杀掉。
在方面放mysql服务,简直就是煞笔行为。
centos yum安装mysql client 客户端
数据库 • 马化云 发表了文章 • 0 个评论 • 2149 次浏览 • 2022-05-17 11:51
这时需要从官网下载
1.安装rpm源
rpm -ivh https://repo.mysql.com//mysql57-community-release-el7-11.noarch.rpm
2.安装客户端
#可以通过yum搜索yum search mysql
#若是64位的话直接安装yum install mysql-community-client.x86_64
结果报错
报以下密钥错误:The GPG keys listed for the "MySQL 5.7 Community Server" repository are already installed but they are not correct for this package.
Check that the correct key URLs are configured for this repository.
则先执行以下命令再安装:rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022
wget -q -O - https://repo.mysql.com/RPM-GPG-KEY-mysql-2022|yum install然后重新安装 yum install mysql-community-client.x86_64
操作:
连到数据库:mysql -h 数据库地址 -u数据库用户名 -p数据库密码 -D 数据库名称
mysql -h 88.88.19.252 -utravelplat -pHdkj1234 -D etravel
数据库导出(表结构):mysqldump -h 数据库地址 -u数据库用户名 -p数据库密码 -d 数据库名称 > 文件名.sql
mysqldump -h 88.88.19.252 -utravelplat -pHdkj1234 -d etravel > db20190713.sql
数据库导出(表结构 + 表数据):mysqldump -h 数据库地址 -u数据库用户名 -p数据库密码 数据库名称 > 文件名.sql
mysqldump -h 88.88.19.252 -utravelplat -pHdkj1234 etravel > db20190713.sql
数据库表导出(表结构 + 表数据):
mysqldump -h 88.88.19.252 -utravelplat -pHdkj1234 etravel doc > doc.sql
导入到数据库:source 文件名.sql
source db20190713.sql
查看全部
这时需要从官网下载
1.安装rpm源
rpm -ivh https://repo.mysql.com//mysql57-community-release-el7-11.noarch.rpm
2.安装客户端
#可以通过yum搜索
yum search mysql
#若是64位的话直接安装
yum install mysql-community-client.x86_64
结果报错
报以下密钥错误:
The GPG keys listed for the "MySQL 5.7 Community Server" repository are already installed but they are not correct for this package.
Check that the correct key URLs are configured for this repository.
则先执行以下命令再安装:
rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022然后重新安装 yum install mysql-community-client.x86_64
wget -q -O - https://repo.mysql.com/RPM-GPG-KEY-mysql-2022|yum install
操作:
连到数据库:mysql -h 数据库地址 -u数据库用户名 -p数据库密码 -D 数据库名称
mysql -h 88.88.19.252 -utravelplat -pHdkj1234 -D etravel
数据库导出(表结构):mysqldump -h 数据库地址 -u数据库用户名 -p数据库密码 -d 数据库名称 > 文件名.sql
mysqldump -h 88.88.19.252 -utravelplat -pHdkj1234 -d etravel > db20190713.sql
数据库导出(表结构 + 表数据):mysqldump -h 数据库地址 -u数据库用户名 -p数据库密码 数据库名称 > 文件名.sql
mysqldump -h 88.88.19.252 -utravelplat -pHdkj1234 etravel > db20190713.sql
数据库表导出(表结构 + 表数据):
mysqldump -h 88.88.19.252 -utravelplat -pHdkj1234 etravel doc > doc.sql
导入到数据库:source 文件名.sql
source db20190713.sql
ubuntu20 设置程序/脚本开机自动启动 可视化
Linux • 马化云 发表了文章 • 0 个评论 • 2647 次浏览 • 2022-05-16 16:40
无非都是把脚本写入到/etc/rc.local 里面
不过笔者在ubuntu20下,试了他们的方法,发现都没有生效,所以就比较郁闷了。
不过也找到了一种图形界面的方法,亲测也可以使用。
1. 在终端下输入
sudo gnome-session-properties
2. 在弹出来的图形界面中,会让你输入自动启动的命令路径和名字。
这个时候,点击add,然后只需要把你的程序路径填入 command 的地址中,然后随意写一个名字(有意义即可)
查看全部
无非都是把脚本写入到/etc/rc.local 里面
不过笔者在ubuntu20下,试了他们的方法,发现都没有生效,所以就比较郁闷了。
不过也找到了一种图形界面的方法,亲测也可以使用。
1. 在终端下输入
sudo gnome-session-properties
2. 在弹出来的图形界面中,会让你输入自动启动的命令路径和名字。
这个时候,点击add,然后只需要把你的程序路径填入 command 的地址中,然后随意写一个名字(有意义即可)

typora markdown 调整表格宽度
闲聊 • 马化云 发表了文章 • 0 个评论 • 4404 次浏览 • 2022-05-15 23:39
如果要控制具体的宽度,需要用html的语言控制:<span style="display:inline-block;width: 80px"> 列名 </span>
上面的语句控制表格宽度为80像素。 改动数字80 ,可以设置为你;需要的任意宽度。
查看全部
如果要控制具体的宽度,需要用html的语言控制:
<span style="display:inline-block;width: 80px"> 列名 </span>
上面的语句控制表格宽度为80像素。 改动数字80 ,可以设置为你;需要的任意宽度。

为什么市面上大部分银河证券不免五了? 还有哪些营业部可以免五
券商万一免五 • 绫波丽 发表了文章 • 0 个评论 • 2994 次浏览 • 2022-05-12 18:52
目前能够无条件开除免五的营业部已经不多了。
当然如果你满足一定资金量的话,个别营业部还是可以开出万一免五的低佣费率。
资金门槛在1w-50w不等。
需要的朋友可以扫码联系:
备注:开户
非诚勿扰。
也欢迎同行合作~ 查看全部
目前能够无条件开除免五的营业部已经不多了。
当然如果你满足一定资金量的话,个别营业部还是可以开出万一免五的低佣费率。

资金门槛在1w-50w不等。
需要的朋友可以扫码联系:
备注:开户
非诚勿扰。
也欢迎同行合作~
ubuntu的Shotwell 图片处理,居然连图片大小调整的功能都没有
Linux • 李魔佛 发表了文章 • 0 个评论 • 1266 次浏览 • 2022-05-11 17:31
只好用用中的photogimg(号称ubuntu下的photoshop)

只好用用中的photogimg(号称ubuntu下的photoshop)
禁止google浏览器http链接强制跳转为https ->网上的根本都是无效的方法
网络 • 李魔佛 发表了文章 • 0 个评论 • 1615 次浏览 • 2022-05-11 17:11
一般在网上的都是按照上面的方法操作,不过实际弄下来,发现根本无法组织chrome自动调转的https。
主要这个网站的主域名是https的,而他的二级域名是http的,用http的二级域名访问是,总是调转到https的页面(首页)。
最后无奈,只好用firefox来浏览这个http的页面。
郁闷ing。。 查看全部
在Chrome浏览器地址栏中输入chrome://net-internals/,打开HSTS标签,在Add domain里的Domain输入要添加的域名地址(不带http的地址),点Add即可。 其中Include subdomains选项还可以添加子域名,保证所有子域名都使用HTTPS访问。
一般在网上的都是按照上面的方法操作,不过实际弄下来,发现根本无法组织chrome自动调转的https。
主要这个网站的主域名是https的,而他的二级域名是http的,用http的二级域名访问是,总是调转到https的页面(首页)。
最后无奈,只好用firefox来浏览这个http的页面。
郁闷ing。。
docker访问外部主机的ip
Linux • 马化云 发表了文章 • 0 个评论 • 2508 次浏览 • 2022-05-10 01:48
那么假如我部署了一个nginx容器在docker里面,那么我的nginx要如何反向代理到我的linux主机的80端口呢?
那么我们测试一下,加入nginx容器的名字为ng110,那么我们通过命令docker exec -it ng110 /bin/bash
进入容器内部。
然后我们尝试curl获取主机的80端口。
首先,curl http://127.0.0.1/
这样子是不通的,因为127.0.0.1是docker内部的回环地址。并不是外部linux的ip。
那么我们先在linux外部,运行命令:ifconfig
这里有一个docker的的字样的ip地址。 那么这个地址就是在docker看来的外部ip地址。
然后我们继续回到docker容器里面,curl http://172.17.0.1/
结果我们发现有返回数据了。
所以在外面的ifconfig的docker容器地址,就是主机相对容器的ip地址。
所以我的nginx配置文件应该这么写:
proxy_pass http://172.17.0.1:80 查看全部
那么假如我部署了一个nginx容器在docker里面,那么我的nginx要如何反向代理到我的linux主机的80端口呢?
那么我们测试一下,加入nginx容器的名字为ng110,那么我们通过命令docker exec -it ng110 /bin/bash
进入容器内部。
然后我们尝试curl获取主机的80端口。
首先,curl http://127.0.0.1/
这样子是不通的,因为127.0.0.1是docker内部的回环地址。并不是外部linux的ip。
那么我们先在linux外部,运行命令:ifconfig

这里有一个docker的的字样的ip地址。 那么这个地址就是在docker看来的外部ip地址。
然后我们继续回到docker容器里面,curl http://172.17.0.1/
结果我们发现有返回数据了。
所以在外面的ifconfig的docker容器地址,就是主机相对容器的ip地址。
所以我的nginx配置文件应该这么写:

proxy_pass http://172.17.0.1:80
集思录这个站点的技术人员挺菜的,连cdn都不用
网络 • 李魔佛 发表了文章 • 0 个评论 • 1028 次浏览 • 2022-05-09 23:21
用稍微大点的ddos攻击下,就容易瘫痪大了的。。。。。。。
心真大。

用稍微大点的ddos攻击下,就容易瘫痪大了的。。。。。。。
心真大。
csdn自定义域名居然都要收费,而且......
闲聊 • 李魔佛 发表了文章 • 0 个评论 • 1131 次浏览 • 2022-05-09 12:02
正规买个域名都没这么贵的。
只是个csdn自定义的二级域名,人家其他新浪微博啥的都任你改名字。。。
正规买个域名都没这么贵的。
只是个csdn自定义的二级域名,人家其他新浪微博啥的都任你改名字。。。

有道云笔记7.0版本太卡了
闲聊 • 李魔佛 发表了文章 • 0 个评论 • 2021 次浏览 • 2022-05-09 00:30
只要打开有道云笔记,立马超越chrome成为内存大户。
笔记本cpu风扇瞬间转起来。

只要打开有道云笔记,立马超越chrome成为内存大户。
笔记本cpu风扇瞬间转起来。
python对视频添加水印 调整帧率
python • 李魔佛 发表了文章 • 0 个评论 • 1260 次浏览 • 2022-05-07 11:37
FFmpeg是一套可以用来记录、转换数字音频、视频,并能将其转化为流的开源计算机程序。采用LGPL或GPL许可证。 它提供了录制、转换以及流化音视频的完整解决方案。它包含了非常先进的音频/视频编解码库libavcodec,为了保证高可移植性和编解码质量,libavcodec里很多code都是从头开发的。 FFmpeg在Linux平台下开发,但它同样也可以在其它操作系统环境中编译运行,包括Windows、Mac OS X等。 这个项目最早由Fabrice Bellard发起,2004年至2015年间由Michael Niedermayer主要负责维护。 许多FFmpeg的开发人员都来自MPlayer项目,而且当前FFmpeg也是放在MPlayer项目组的服务器上。 项目的名称来自MPEG视频编码标准,前面的"FF"代表"Fast Forward"。
# coding=utf-8
import os
import subprocess
import datetime
import json, pprint
import re, time
import threading
import random
import shutil
class FFmpeg:
def __init__(self, editvdo, addlogo=None, addmusic=None,
addvdohead=None, addvdotail=None):
self.editvdo = editvdo
self.addlogo = addlogo
self.addmusic = addmusic
self.addvdohead = addvdohead
self.addvdotail = addvdotail
self.vdo_time, self.vdo_width, self.vdo_height, self.attr_dict = self.get_attr()
self.editvdo_path = os.path.dirname(editvdo)
self.editvdo_name = os.path.basename(editvdo)
def get_attr(self):
"""
获取视频属性参数
:return:
"""
strcmd = r'ffprobe -print_format json -show_streams -i "{}"'.format(self.editvdo)
status, output = subprocess.getstatusoutput(strcmd)
agrs = eval(re.search('{.*}', output, re.S).group().replace("\n", "").replace(" ", ''))
streams = agrs.get('streams', )
agrs_dict = dict()
[agrs_dict.update(x) for x in streams]
vdo_time = agrs_dict.get('duration')
vdo_width = agrs_dict.get('width')
vdo_height = agrs_dict.get('height')
attr = (vdo_time, vdo_width, vdo_height, agrs_dict)
return attr
def edit_head(self, start_time, end_time, deposit=None):
"""
截取指定长度视频
:param second: 去除开始的多少秒
:param deposit: 另存为文件
:return: True/Flase
"""
if None == deposit:
deposit = self.editvdo_path+'/'+'edit_head'+self.editvdo_name
start = time.strftime('%H:%M:%S', time.gmtime(start_time))
end = time.strftime('%H:%M:%S', time.gmtime(end_time))
strcmd = 'ffmpeg -i "{}" -vcodec copy -acodec copy -ss {} -to {} "{}" -y'.format(
self.editvdo, start, end, deposit)
result = subprocess.run(args=strcmd, stdout=subprocess.PIPE, shell=True)
if os.path.exists(deposit):
os.remove(self.editvdo)
os.rename(deposit, self.editvdo)
return True
else:
return False
def edit_logo(self, deposit=None):
"""
添加水印
:param deposit:添加水印后另存为路径,为空则覆盖
:return: True/False
"""
if None == deposit:
deposit = self.editvdo_path+'/'+'edit_logo'+self.editvdo_name
strcmd = r'ffmpeg -i "{}" -vf "movie=\'{}\' [watermark];[in] ' \
r'[watermark] overlay=main_w-overlay_w-10:10 [out]" "{}"'.format(
self.editvdo, self.addlogo, deposit)
result = subprocess.run(args=strcmd, stdout=subprocess.PIPE, shell=True)
if os.path.exists(deposit):
os.remove(self.editvdo)
os.rename(deposit, self.editvdo)
return True
else:
return False
def edit_music(self, deposit=None):
if None == deposit:
deposit = self.editvdo_path+'/'+'edit_music'+self.editvdo_name
strcmd = r'ffmpeg -y -i "{}" -i "{}" -filter_complex "[0:a] ' \
r'pan=stereo|c0=1*c0|c1=1*c1 [a1], [1:a] ' \
r'pan=stereo|c0=1*c0|c1=1*c1 [a2],[a1][a2]amix=duration=first,' \
r'pan=stereo|c0<c0+c1|c1<c2+c3,pan=mono|c0=c0+c1[a]" ' \
r'-map "[a]" -map 0:v -c:v libx264 -c:a aac ' \
r'-strict -2 -ac 2 "{}"'.format(self.editvdo, self.addmusic, deposit)
result = subprocess.run(args=strcmd, stdout=subprocess.PIPE, shell=True)
if os.path.exists(deposit):
os.remove(self.editvdo)
os.rename(deposit, self.editvdo)
return True
else:
return False
def edit_rate(self, rete=30, deposit=None):
"""
改变帧率
:param rete: 修改大小帧率
:param deposit: 修改后保存路径
:return:
"""
if None == deposit:
deposit = self.editvdo_path+'/'+'edit_music'+self.editvdo_name
strcmd = r'ffmpeg -i "{}" -r {} "{}"' % (self.editvdo, rete, deposit)
result = subprocess.run(args=strcmd, stdout=subprocess.PIPE, shell=True)
if os.path.exists(deposit):
os.remove(self.editvdo)
os.rename(deposit, self.editvdo)
return True
else:
return False
def edit_power(self, power='1280x720', deposit=None):
"""
修改分辨率
:param power: 分辨率
:param deposit: 修改后保存路径,为空则覆盖
:return:
"""
if None == deposit:
deposit = self.editvdo_path+'/'+'edit_power'+self.editvdo_name
strcmd = r'ffmpeg -i "{}" -s {} "{}"'.format(self.editvdo, power, deposit)
result = subprocess.run(args=strcmd, stdout=subprocess.PIPE, shell=True)
if os.path.exists(deposit):
os.remove(self.editvdo)
os.rename(deposit, self.editvdo)
return True
else:
return False
def rdit_marge(self, vdo_head, vdo_tail, deposit=None):
if None == deposit:
deposit = self.editvdo_path+'/'+'rdit_marge'+self.editvdo_name
with open(self.editvdo_path+'/'+'rdit_marge.txt', 'w', encoding='utf-8') as f:
f.write("file '{}' \nfile '{}' \nfile '{}'" .format(
vdo_head, self.editvdo, vdo_tail))
strcmd = r'ffmpeg -f concat -safe 0 -i "{}" -c copy "{}"'.format(
self.editvdo_path + '/' + 'rdit_marge.txt', deposit)
result = subprocess.run(args=strcmd, stdout=subprocess.PIPE, shell=True)
if os.path.exists(deposit):
os.remove(self.editvdo)
os.rename(deposit, self.editvdo)
return True
else:
return False
# ffmpeg - i input.mkv - filter_complex "[0:v]setpts=0.5*PTS[v];[0:a]atempo=2.0[a]" - map"[v]" - map"[a]" output.mkv
test = FFmpeg(r"D:\vdio\4.mp4")
PS:需要电脑把ffmpeg的可执行文件放到环境变量中 查看全部
FFmpeg是一套可以用来记录、转换数字音频、视频,并能将其转化为流的开源计算机程序。采用LGPL或GPL许可证。 它提供了录制、转换以及流化音视频的完整解决方案。它包含了非常先进的音频/视频编解码库libavcodec,为了保证高可移植性和编解码质量,libavcodec里很多code都是从头开发的。 FFmpeg在Linux平台下开发,但它同样也可以在其它操作系统环境中编译运行,包括Windows、Mac OS X等。 这个项目最早由Fabrice Bellard发起,2004年至2015年间由Michael Niedermayer主要负责维护。 许多FFmpeg的开发人员都来自MPlayer项目,而且当前FFmpeg也是放在MPlayer项目组的服务器上。 项目的名称来自MPEG视频编码标准,前面的"FF"代表"Fast Forward"。
# coding=utf-8
import os
import subprocess
import datetime
import json, pprint
import re, time
import threading
import random
import shutil
class FFmpeg:
def __init__(self, editvdo, addlogo=None, addmusic=None,
addvdohead=None, addvdotail=None):
self.editvdo = editvdo
self.addlogo = addlogo
self.addmusic = addmusic
self.addvdohead = addvdohead
self.addvdotail = addvdotail
self.vdo_time, self.vdo_width, self.vdo_height, self.attr_dict = self.get_attr()
self.editvdo_path = os.path.dirname(editvdo)
self.editvdo_name = os.path.basename(editvdo)
def get_attr(self):
"""
获取视频属性参数
:return:
"""
strcmd = r'ffprobe -print_format json -show_streams -i "{}"'.format(self.editvdo)
status, output = subprocess.getstatusoutput(strcmd)
agrs = eval(re.search('{.*}', output, re.S).group().replace("\n", "").replace(" ", ''))
streams = agrs.get('streams', )
agrs_dict = dict()
[agrs_dict.update(x) for x in streams]
vdo_time = agrs_dict.get('duration')
vdo_width = agrs_dict.get('width')
vdo_height = agrs_dict.get('height')
attr = (vdo_time, vdo_width, vdo_height, agrs_dict)
return attr
def edit_head(self, start_time, end_time, deposit=None):
"""
截取指定长度视频
:param second: 去除开始的多少秒
:param deposit: 另存为文件
:return: True/Flase
"""
if None == deposit:
deposit = self.editvdo_path+'/'+'edit_head'+self.editvdo_name
start = time.strftime('%H:%M:%S', time.gmtime(start_time))
end = time.strftime('%H:%M:%S', time.gmtime(end_time))
strcmd = 'ffmpeg -i "{}" -vcodec copy -acodec copy -ss {} -to {} "{}" -y'.format(
self.editvdo, start, end, deposit)
result = subprocess.run(args=strcmd, stdout=subprocess.PIPE, shell=True)
if os.path.exists(deposit):
os.remove(self.editvdo)
os.rename(deposit, self.editvdo)
return True
else:
return False
def edit_logo(self, deposit=None):
"""
添加水印
:param deposit:添加水印后另存为路径,为空则覆盖
:return: True/False
"""
if None == deposit:
deposit = self.editvdo_path+'/'+'edit_logo'+self.editvdo_name
strcmd = r'ffmpeg -i "{}" -vf "movie=\'{}\' [watermark];[in] ' \
r'[watermark] overlay=main_w-overlay_w-10:10 [out]" "{}"'.format(
self.editvdo, self.addlogo, deposit)
result = subprocess.run(args=strcmd, stdout=subprocess.PIPE, shell=True)
if os.path.exists(deposit):
os.remove(self.editvdo)
os.rename(deposit, self.editvdo)
return True
else:
return False
def edit_music(self, deposit=None):
if None == deposit:
deposit = self.editvdo_path+'/'+'edit_music'+self.editvdo_name
strcmd = r'ffmpeg -y -i "{}" -i "{}" -filter_complex "[0:a] ' \
r'pan=stereo|c0=1*c0|c1=1*c1 [a1], [1:a] ' \
r'pan=stereo|c0=1*c0|c1=1*c1 [a2],[a1][a2]amix=duration=first,' \
r'pan=stereo|c0<c0+c1|c1<c2+c3,pan=mono|c0=c0+c1[a]" ' \
r'-map "[a]" -map 0:v -c:v libx264 -c:a aac ' \
r'-strict -2 -ac 2 "{}"'.format(self.editvdo, self.addmusic, deposit)
result = subprocess.run(args=strcmd, stdout=subprocess.PIPE, shell=True)
if os.path.exists(deposit):
os.remove(self.editvdo)
os.rename(deposit, self.editvdo)
return True
else:
return False
def edit_rate(self, rete=30, deposit=None):
"""
改变帧率
:param rete: 修改大小帧率
:param deposit: 修改后保存路径
:return:
"""
if None == deposit:
deposit = self.editvdo_path+'/'+'edit_music'+self.editvdo_name
strcmd = r'ffmpeg -i "{}" -r {} "{}"' % (self.editvdo, rete, deposit)
result = subprocess.run(args=strcmd, stdout=subprocess.PIPE, shell=True)
if os.path.exists(deposit):
os.remove(self.editvdo)
os.rename(deposit, self.editvdo)
return True
else:
return False
def edit_power(self, power='1280x720', deposit=None):
"""
修改分辨率
:param power: 分辨率
:param deposit: 修改后保存路径,为空则覆盖
:return:
"""
if None == deposit:
deposit = self.editvdo_path+'/'+'edit_power'+self.editvdo_name
strcmd = r'ffmpeg -i "{}" -s {} "{}"'.format(self.editvdo, power, deposit)
result = subprocess.run(args=strcmd, stdout=subprocess.PIPE, shell=True)
if os.path.exists(deposit):
os.remove(self.editvdo)
os.rename(deposit, self.editvdo)
return True
else:
return False
def rdit_marge(self, vdo_head, vdo_tail, deposit=None):
if None == deposit:
deposit = self.editvdo_path+'/'+'rdit_marge'+self.editvdo_name
with open(self.editvdo_path+'/'+'rdit_marge.txt', 'w', encoding='utf-8') as f:
f.write("file '{}' \nfile '{}' \nfile '{}'" .format(
vdo_head, self.editvdo, vdo_tail))
strcmd = r'ffmpeg -f concat -safe 0 -i "{}" -c copy "{}"'.format(
self.editvdo_path + '/' + 'rdit_marge.txt', deposit)
result = subprocess.run(args=strcmd, stdout=subprocess.PIPE, shell=True)
if os.path.exists(deposit):
os.remove(self.editvdo)
os.rename(deposit, self.editvdo)
return True
else:
return False
# ffmpeg - i input.mkv - filter_complex "[0:v]setpts=0.5*PTS[v];[0:a]atempo=2.0[a]" - map"[v]" - map"[a]" output.mkv
test = FFmpeg(r"D:\vdio\4.mp4")
PS:需要电脑把ffmpeg的可执行文件放到环境变量中
格式工厂去除视频水印logo效果不好
python • 李魔佛 发表了文章 • 0 个评论 • 1639 次浏览 • 2022-05-07 10:53
试了一下,结果效果不理想,格式工厂只是把logo区域进行模糊处理,也就是logo区域变得不可再阅读。

wp super cache缓存文件在哪里?
网络 • 李魔佛 发表了文章 • 0 个评论 • 1429 次浏览 • 2022-05-07 01:01
里面的静态文件是html后缀结尾的。
如果同时开启了cdn加速,和wp super cache, 那么会有个问题。 你写的文章,发布出去后,无论怎么刷新都出不了的。
为什么?
因为你的首页也是做了wp super cache 变成了静态页面,以html结尾的。
而html文件默认是被cdn缓存起来的。
也就是用户访问你的网站的时候, 看到的是cdn里面的index.html, 而这个文件是有wp super cache生成的,而你的缓存规则如果是所有文件缓存7天的话,意味着你7天后才可以看到你新发的文章。
当然解决办法也很简单,在缓存规则里面,把html后缀设置为不缓存就可以了。 查看全部
里面的静态文件是html后缀结尾的。

如果同时开启了cdn加速,和wp super cache, 那么会有个问题。 你写的文章,发布出去后,无论怎么刷新都出不了的。
为什么?
因为你的首页也是做了wp super cache 变成了静态页面,以html结尾的。
而html文件默认是被cdn缓存起来的。
也就是用户访问你的网站的时候, 看到的是cdn里面的index.html, 而这个文件是有wp super cache生成的,而你的缓存规则如果是所有文件缓存7天的话,意味着你7天后才可以看到你新发的文章。
当然解决办法也很简单,在缓存规则里面,把html后缀设置为不缓存就可以了。
typora 复制公众号文章时图片无法正确上传到图床
闲聊 • 李魔佛 发表了文章 • 0 个评论 • 1520 次浏览 • 2022-05-07 00:54
可是对于微信公众号的文章,typora复制出来的图片都是一样的。主要原因是公众号的图片命名都叫640.png。
以至于上传的图片都是同一张。
那么如何解决这个问题呢?
我们可以绕道。
先用有道云笔记保存公众号的文章。
有道云保存文章时,可以正常把公众号的图片正常拉下来的。
然后右键,导出word。 对,有道云笔记这个功能。
然后打开保存的word文件,全选,复制里面的内容,包含图片。
然后ctrl+v 粘贴到typora。
然后图片就可以正常上传的腾讯云,七牛云的文件服务器啦。
查看全部
可是对于微信公众号的文章,typora复制出来的图片都是一样的。主要原因是公众号的图片命名都叫640.png。
以至于上传的图片都是同一张。
那么如何解决这个问题呢?
我们可以绕道。
先用有道云笔记保存公众号的文章。
有道云保存文章时,可以正常把公众号的图片正常拉下来的。
然后右键,导出word。 对,有道云笔记这个功能。
然后打开保存的word文件,全选,复制里面的内容,包含图片。
然后ctrl+v 粘贴到typora。
然后图片就可以正常上传的腾讯云,七牛云的文件服务器啦。
腾讯云添加cdn加速后 域名加上www无法访问
网络 • 李魔佛 发表了文章 • 0 个评论 • 1956 次浏览 • 2022-05-06 00:31
而加入了cdn加速之后,30daydo.com 可以正常访问, 而www.30daydo.com 却访问异常。
解决方法:
www的域名访问 也要加入一个cdn加速记录。
如下图所示:
添加完记录后,需要在你的DNSPod 的域名解析里面,把这个www的解析CNAME也加进去。 这一步也不能少。
类型要填写CNAME,不能填A哦。
然后过大概十来分钟才能生效。并不是马上就生效的哦。
查看全部
而加入了cdn加速之后,30daydo.com 可以正常访问, 而www.30daydo.com 却访问异常。
解决方法:
www的域名访问 也要加入一个cdn加速记录。
如下图所示:

添加完记录后,需要在你的DNSPod 的域名解析里面,把这个www的解析CNAME也加进去。 这一步也不能少。

类型要填写CNAME,不能填A哦。
然后过大概十来分钟才能生效。并不是马上就生效的哦。
使用代理VPN后,微信公众号发文章显示的是代理后的VPN归属地
闲聊 • 李魔佛 发表了文章 • 0 个评论 • 4808 次浏览 • 2022-05-05 00:28
公众号也不例外。
如果想修改归属地,首先需要有一个代理或者VPN软件。设置为全局代理,然后发文,你的发文地址就会显示你的代理和VPN地址啦。
