

python量化交易
6行python代码 获取通达信的可转债分时数据
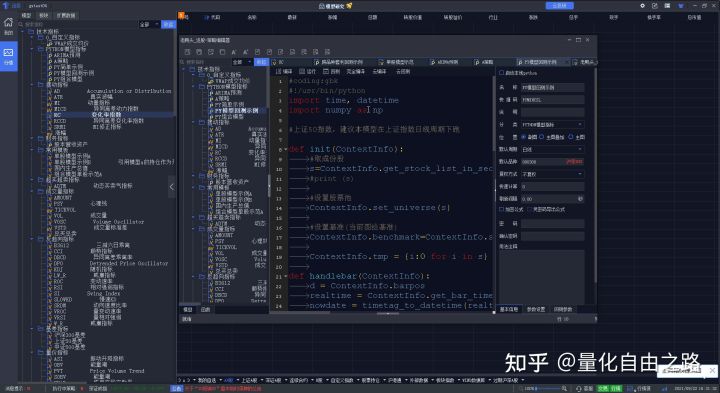
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 4161 次浏览 • 2022-08-27 14:33
api = TdxHq_API()
with api.connect('119.147.212.81', 7709):
data = api.get_security_bars(7, 0, '123045', 0, 240) # 123045 为转债代码 ,240 为获取 240个转债数据
df = api.to_df(data)
df=df.sort_values('datetime')
点击查看大图
如果需要遍历当前最新可转债代码(集思录),需要结合前面的文章。
公众号:
查看全部
from pytdx.hq import TdxHq_API
api = TdxHq_API()
with api.connect('119.147.212.81', 7709):
data = api.get_security_bars(7, 0, '123045', 0, 240) # 123045 为转债代码 ,240 为获取 240个转债数据
df = api.to_df(data)
df=df.sort_values('datetime')

如果需要遍历当前最新可转债代码(集思录),需要结合前面的文章。
公众号:

ptrade如何以指定价格下单?
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 4234 次浏览 • 2022-07-30 19:27
order函数:order-按数量买卖
order(security, amount, limit_price=None)
买卖标的。
注意:
由于下述原因,回测中实际买入或者卖出的股票数量有时候可能与委托设置的不一样,针对上述内容调整,系统会在日志中增加警告信息:
根据委托买入数量与价格经计算后的资金数量,大于当前可用资金;
委托卖出数量大于当前可用持仓数量;
每次交易数量只能是100的整数倍,但是卖出所有股票时不受此限制;
股票停牌、股票未上市或者退市、股票不存在;
回测中每天结束时会取消所有未完成交易;
order_target - 函数order_target(security, amount, limit_price=None)
买卖股票,直到股票最终数量达到指定的amount。
注意:该函数在委托股票时取整100股,委托可转债时取整100张。
参数
security: 股票代码(str);
amount: 期望的最终数量(int);
limit_price:买卖限价(float);
返回
Order对象中的id或者None。如果创建订单成功,则返回Order对象的id,失败则返回None(str)。
order_value 函数order_value - 指定目标价值买卖
order_value(security, value, limit_price=None)
买卖指定价值为value的股票。
注意:该函数在委托股票时取整100股,委托可转债时取整100张。
order_target_value - 函数order_target_value - 指定持仓市值买卖
order_target_value(security, value, limit_price=None)
调整股票仓位到value价值
注意:该函数在委托股票时取整100股,委托可转债时取整100张。
order_market 函数order_market - 按市价进行委托
order_market(security, amount, market_type=None, limit_price=None)
可以使用多种市价类型进行委托。
注意:该函数仅在股票交易模块可用。
上面几个在handle_data中使用的下单函数,都是无法指定价格的,limit_price 只是用于限价,比如你要卖1000股,limit_price的作用是不要把价格卖出你的目标,至于多少卖,是无法控制的。
但是有一个tick_data函数,专门用于行情交易的,里面可调用的函数也很少。tick_data(可选)
tick_data(context, data)
该函数会每隔3秒执行一次。
注意 :
该函数仅在交易模块可用。
该函数在9:30之后才能执行。
该函数中只能使用order_tick进行对应的下单操作。里面下单,用的下单函数是
order_tick - tick行情触发买卖
order_tick(sid, amount, priceGear='1', limit_price=None)
买卖股票下单,可设定价格档位进行委托
注意:该函数仅在交易模块可用。
参数
sid:股票代码(str);
amount:交易数量,正数表示买入,负数表示卖出(int)
priceGear:盘口档位,level1:1~5买档/-1~-5卖档,level2:1~10买档/-1~-10卖档(str)
limit_price:买卖限价,当输入参数中也包含priceGear时,下单价格以limit_price为主(float);
注意到里面:
limit_price:买卖限价,当输入参数中也包含priceGear时,下单价格以limit_price为主
发现这里面居然可以定义价格下单,所以如果一定要指定价格,就需要使用tick_data 触发。
使用代码:
def initialize(context):
g.security = "600570.SS"
set_universe(g.security)
def tick_data(context,data):
security = g.security
current_price = eval(data[security]['tick']['bid_grp'][0])[1][0]
if current_price > 56 and current_price < 57:
# 以买一档下单
order_tick(g.security, -100, "1")
# 以卖二档下单
order_tick(g.security, 100, "-2")
# 以指定价格下单
order_tick(g.security, 100, limit_price=56.5)
def handle_data(context, data):
pass 查看全部
order函数:
order-按数量买卖
order(security, amount, limit_price=None)
买卖标的。
注意:
由于下述原因,回测中实际买入或者卖出的股票数量有时候可能与委托设置的不一样,针对上述内容调整,系统会在日志中增加警告信息:
根据委托买入数量与价格经计算后的资金数量,大于当前可用资金;
委托卖出数量大于当前可用持仓数量;
每次交易数量只能是100的整数倍,但是卖出所有股票时不受此限制;
股票停牌、股票未上市或者退市、股票不存在;
回测中每天结束时会取消所有未完成交易;
order_target - 函数
order_target(security, amount, limit_price=None)
买卖股票,直到股票最终数量达到指定的amount。
注意:该函数在委托股票时取整100股,委托可转债时取整100张。
参数
security: 股票代码(str);
amount: 期望的最终数量(int);
limit_price:买卖限价(float);
返回
Order对象中的id或者None。如果创建订单成功,则返回Order对象的id,失败则返回None(str)。
order_value 函数
order_value - 指定目标价值买卖
order_value(security, value, limit_price=None)
买卖指定价值为value的股票。
注意:该函数在委托股票时取整100股,委托可转债时取整100张。
order_target_value - 函数
order_target_value - 指定持仓市值买卖
order_target_value(security, value, limit_price=None)
调整股票仓位到value价值
注意:该函数在委托股票时取整100股,委托可转债时取整100张。
order_market 函数
order_market - 按市价进行委托
order_market(security, amount, market_type=None, limit_price=None)
可以使用多种市价类型进行委托。
注意:该函数仅在股票交易模块可用。
上面几个在handle_data中使用的下单函数,都是无法指定价格的,limit_price 只是用于限价,比如你要卖1000股,limit_price的作用是不要把价格卖出你的目标,至于多少卖,是无法控制的。
但是有一个tick_data函数,专门用于行情交易的,里面可调用的函数也很少。
tick_data(可选)里面下单,用的下单函数是
tick_data(context, data)
该函数会每隔3秒执行一次。
注意 :
该函数仅在交易模块可用。
该函数在9:30之后才能执行。
该函数中只能使用order_tick进行对应的下单操作。
order_tick - tick行情触发买卖
order_tick(sid, amount, priceGear='1', limit_price=None)
买卖股票下单,可设定价格档位进行委托
注意:该函数仅在交易模块可用。
参数
sid:股票代码(str);
amount:交易数量,正数表示买入,负数表示卖出(int)
priceGear:盘口档位,level1:1~5买档/-1~-5卖档,level2:1~10买档/-1~-10卖档(str)
limit_price:买卖限价,当输入参数中也包含priceGear时,下单价格以limit_price为主(float);
注意到里面:
limit_price:买卖限价,当输入参数中也包含priceGear时,下单价格以limit_price为主
发现这里面居然可以定义价格下单,所以如果一定要指定价格,就需要使用tick_data 触发。
使用代码:
def initialize(context):
g.security = "600570.SS"
set_universe(g.security)
def tick_data(context,data):
security = g.security
current_price = eval(data[security]['tick']['bid_grp'][0])[1][0]
if current_price > 56 and current_price < 57:
# 以买一档下单
order_tick(g.security, -100, "1")
# 以卖二档下单
order_tick(g.security, 100, "-2")
# 以指定价格下单
order_tick(g.security, 100, limit_price=56.5)
def handle_data(context, data):
pass
国盛证券qmt mini模式 xtquant
券商万一免五 • 李魔佛 发表了文章 • 0 个评论 • 14383 次浏览 • 2022-07-29 01:00
【国盛QMT支持 xtquant qmt mini模式】
mini模式可以在外部运行,同时可以下载历史tick数据。xtdata是xtquant库中提供行情相关数据的模块,本模块旨在提供精简直接的数据满足量化交易者的数
据需求,作为python库的形式可以被灵活添加到各种策略脚本中。
主要提供行情数据(历史和实时的K线和分笔)、财务数据、合约基础信息、板块和行业分类信息等通
用的行情数据
可以直接获取level2的数据
使用python代码直接运行,不用在qmt软件里面憋屈地写代码,可直接使用pycharm,vscode编写,且有代码提示,补全,好用多了。
附一个完整的策略例子。
保存为: demo.py
命令行下运行:
python demo.py# 创建策略
#coding=utf-8
from xtquant.xttrader import XtQuantTrader, XtQuantTraderCallback
from xtquant.xtquant import StockAccount
from xtquant import xtconstant
class MyXtQuantTraderCallback(XtQuantTraderCallback):
def on_disconnected(self):
"""
连接断开
:return:
"""
print("connection lost")
def on_stock_order(self, order):
"""
委托回报推送
:param order: XtOrder对象
:return:
"""
print("on order callback:")
print(order.stock_code, order.order_status, order.order_sysid)
def on_stock_asset(self, asset):
"""
资金变动推送
:param asset: XtAsset对象
:return:
"""
print("on asset callback")
print(asset.account_id, asset.cash, asset.total_asset)
def on_stock_trade(self, trade):
"""
成交变动推送
:param trade: XtTrade对象
:return:
"""
print("on trade callback")
print(trade.account_id, trade.stock_code, trade.order_id)
def on_stock_position(self, position):
"""
持仓变动推送
:param position: XtPosition对象
:return:
"""
print("on position callback")
print(position.stock_code, position.volume)
def on_order_error(self, order_error):
"""
委托失败推送
:param order_error:XtOrderError 对象
:return:
"""
print("on order_error callback")
print(order_error.order_id, order_error.error_id, order_error.error_msg)
def on_cancel_error(self, cancel_error):
"""
撤单失败推送
:param cancel_error: XtCancelError 对象
:return:
"""
print("on cancel_error callback")
print(cancel_error.order_id, cancel_error.error_id,
cancel_error.error_msg)
def on_order_stock_async_response(self, response):
"""
异步下单回报推送
:param response: XtOrderResponse 对象
:return:
"""
print("on_order_stock_async_response")
print(response.account_id, response.order_id, response.seq)
if __name__ == "__main__":
print("demo test")
# path为mini qmt客户端安装目录下userdata_mini路径
path = 'D:\\迅投极速交易终端 睿智融科版\\userdata_mini'
# session_id为会话编号,策略使用方对于不同的Python策略需要使用不同的会话编号
session_id = 123456
xt_trader = XtQuantTrader(path, session_id)
# 创建资金账号为1000000365的证券账号对象
acc = StockAccount('1000000365')
# 创建交易回调类对象,并声明接收回调
callback = MyXtQuantTraderCallback()
xt_trader.register_callback(callback)
# 启动交易线程
xt_trader.start()
# 建立交易连接,返回0表示连接成功
connect_result = xt_trader.connect()
print(connect_result)
# 对交易回调进行订阅,订阅后可以收到交易主推,返回0表示订阅成功
subscribe_result = xt_trader.subscribe(acc)
print(subscribe_result)
stock_code = '600000.SH'
# 使用指定价下单,接口返回订单编号,后续可以用于撤单操作以及查询委托状态
print("order using the fix price:")
fix_result_order_id = xt_trader.order_stock(acc, stock_code,
xtconstant.STOCK_BUY, 200, xtconstant.FIX_PRICE, 10.5, 'strategy_name',
'remark')
print(fix_result_order_id)
# 使用订单编号撤单
print("cancel order:")
cancel_order_result = xt_trader.cancel_order_stock(acc, fix_result_order_id)
print(cancel_order_result)
# 使用异步下单接口,接口返回下单请求序号seq,seq可以和on_order_stock_async_response
的委托反馈response对应起来
print("order using async api:")
async_seq = xt_trader.order_stock(acc, stock_code, xtconstant.STOCK_BUY,
200, xtconstant.FIX_PRICE, 10.5, 'strategy_name', 'remark')
print(async_seq)
# 查询证券资产
print("query asset:")
asset = xt_trader.query_stock_asset(acc)
if asset:
print("asset:")
print("cash {0}".format(asset.cash))
# 根据订单编号查询委托
print("query order:")
order = xt_trader.query_stock_order(acc, fix_result_order_id)
if order:
print("order:")
print("order {0}".format(order.order_id))
# 查询当日所有的委托
print("query orders:")
orders = xt_trader.query_stock_orders(acc)
print("orders:", len(orders))
if len(orders) != 0:
print("last order:")
print("{0} {1} {2}".format(orders[-1].stock_code,
orders[-1].order_volume, orders[-1].price))
# 查询当日所有的成交
print("query trade:")
trades = xt_trader.query_stock_trades(acc)
print("trades:", len(trades))
if len(trades) != 0:
print("last trade:")
print("{0} {1} {2}".format(trades[-1].stock_code,
trades[-1].traded_volume, trades[-1].traded_price))
# 查询当日所有的持仓
print("query positions:")
positions = xt_trader.query_stock_positions(acc)
print("positions:", len(positions))
if len(positions) != 0:
print("last position:")
print("{0} {1} {2}".format(positions[-1].account_id,
positions[-1].stock_code, positions[-1].volume))
# 根据股票代码查询对应持仓
print("query position:")
position = xt_trader.query_stock_position(acc, stock_code)
if position:
print("position:")
print("{0} {1} {2}".format(position.account_id, position.stock_code,
position.volume))
# 阻塞线程,接收交易推送
xt_trader.run_forever()
开通xtquant的方式可以咨询。
目前开户费率低,门槛低,提供技术支持与交流。
需要的朋友,可以扫码咨询:
备注开户 查看全部
【国盛QMT支持 xtquant qmt mini模式】
mini模式可以在外部运行,同时可以下载历史tick数据。
xtdata是xtquant库中提供行情相关数据的模块,本模块旨在提供精简直接的数据满足量化交易者的数
据需求,作为python库的形式可以被灵活添加到各种策略脚本中。
主要提供行情数据(历史和实时的K线和分笔)、财务数据、合约基础信息、板块和行业分类信息等通
用的行情数据
可以直接获取level2的数据

使用python代码直接运行,不用在qmt软件里面憋屈地写代码,可直接使用pycharm,vscode编写,且有代码提示,补全,好用多了。
附一个完整的策略例子。
保存为: demo.py
命令行下运行:
python demo.py
# 创建策略
#coding=utf-8
from xtquant.xttrader import XtQuantTrader, XtQuantTraderCallback
from xtquant.xtquant import StockAccount
from xtquant import xtconstant
class MyXtQuantTraderCallback(XtQuantTraderCallback):
def on_disconnected(self):
"""
连接断开
:return:
"""
print("connection lost")
def on_stock_order(self, order):
"""
委托回报推送
:param order: XtOrder对象
:return:
"""
print("on order callback:")
print(order.stock_code, order.order_status, order.order_sysid)
def on_stock_asset(self, asset):
"""
资金变动推送
:param asset: XtAsset对象
:return:
"""
print("on asset callback")
print(asset.account_id, asset.cash, asset.total_asset)
def on_stock_trade(self, trade):
"""
成交变动推送
:param trade: XtTrade对象
:return:
"""
print("on trade callback")
print(trade.account_id, trade.stock_code, trade.order_id)
def on_stock_position(self, position):
"""
持仓变动推送
:param position: XtPosition对象
:return:
"""
print("on position callback")
print(position.stock_code, position.volume)
def on_order_error(self, order_error):
"""
委托失败推送
:param order_error:XtOrderError 对象
:return:
"""
print("on order_error callback")
print(order_error.order_id, order_error.error_id, order_error.error_msg)
def on_cancel_error(self, cancel_error):
"""
撤单失败推送
:param cancel_error: XtCancelError 对象
:return:
"""
print("on cancel_error callback")
print(cancel_error.order_id, cancel_error.error_id,
cancel_error.error_msg)
def on_order_stock_async_response(self, response):
"""
异步下单回报推送
:param response: XtOrderResponse 对象
:return:
"""
print("on_order_stock_async_response")
print(response.account_id, response.order_id, response.seq)
if __name__ == "__main__":
print("demo test")
# path为mini qmt客户端安装目录下userdata_mini路径
path = 'D:\\迅投极速交易终端 睿智融科版\\userdata_mini'
# session_id为会话编号,策略使用方对于不同的Python策略需要使用不同的会话编号
session_id = 123456
xt_trader = XtQuantTrader(path, session_id)
# 创建资金账号为1000000365的证券账号对象
acc = StockAccount('1000000365')
# 创建交易回调类对象,并声明接收回调
callback = MyXtQuantTraderCallback()
xt_trader.register_callback(callback)
# 启动交易线程
xt_trader.start()
# 建立交易连接,返回0表示连接成功
connect_result = xt_trader.connect()
print(connect_result)
# 对交易回调进行订阅,订阅后可以收到交易主推,返回0表示订阅成功
subscribe_result = xt_trader.subscribe(acc)
print(subscribe_result)
stock_code = '600000.SH'
# 使用指定价下单,接口返回订单编号,后续可以用于撤单操作以及查询委托状态
print("order using the fix price:")
fix_result_order_id = xt_trader.order_stock(acc, stock_code,
xtconstant.STOCK_BUY, 200, xtconstant.FIX_PRICE, 10.5, 'strategy_name',
'remark')
print(fix_result_order_id)
# 使用订单编号撤单
print("cancel order:")
cancel_order_result = xt_trader.cancel_order_stock(acc, fix_result_order_id)
print(cancel_order_result)
# 使用异步下单接口,接口返回下单请求序号seq,seq可以和on_order_stock_async_response
的委托反馈response对应起来
print("order using async api:")
async_seq = xt_trader.order_stock(acc, stock_code, xtconstant.STOCK_BUY,
200, xtconstant.FIX_PRICE, 10.5, 'strategy_name', 'remark')
print(async_seq)
# 查询证券资产
print("query asset:")
asset = xt_trader.query_stock_asset(acc)
if asset:
print("asset:")
print("cash {0}".format(asset.cash))
# 根据订单编号查询委托
print("query order:")
order = xt_trader.query_stock_order(acc, fix_result_order_id)
if order:
print("order:")
print("order {0}".format(order.order_id))
# 查询当日所有的委托
print("query orders:")
orders = xt_trader.query_stock_orders(acc)
print("orders:", len(orders))
if len(orders) != 0:
print("last order:")
print("{0} {1} {2}".format(orders[-1].stock_code,
orders[-1].order_volume, orders[-1].price))
# 查询当日所有的成交
print("query trade:")
trades = xt_trader.query_stock_trades(acc)
print("trades:", len(trades))
if len(trades) != 0:
print("last trade:")
print("{0} {1} {2}".format(trades[-1].stock_code,
trades[-1].traded_volume, trades[-1].traded_price))
# 查询当日所有的持仓
print("query positions:")
positions = xt_trader.query_stock_positions(acc)
print("positions:", len(positions))
if len(positions) != 0:
print("last position:")
print("{0} {1} {2}".format(positions[-1].account_id,
positions[-1].stock_code, positions[-1].volume))
# 根据股票代码查询对应持仓
print("query position:")
position = xt_trader.query_stock_position(acc, stock_code)
if position:
print("position:")
print("{0} {1} {2}".format(position.account_id, position.stock_code,
position.volume))
# 阻塞线程,接收交易推送
xt_trader.run_forever()
开通xtquant的方式可以咨询。
目前开户费率低,门槛低,提供技术支持与交流。
需要的朋友,可以扫码咨询:

备注开户
ptrade每天自动打新 (新股和可转债)附python代码
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 5710 次浏览 • 2022-07-28 11:10
def initialize(context):
g.flag = False
log.info("initialize g.flag=" + str(g.flag) )
def before_trading_start(context, data):
g.flag = False
log.info("before_trading_start g.flag=" + str(g.flag) )
def handle_data(context, data):
if not g.flag and time.strftime("%H:%M:%S", time.localtime()) > '09:35:00':
# 自动打新
log.info("自动打新")
ipo_stocks_order()
g.flag = True
def on_order_response(context, order_list):
# 该函数会在委托回报返回时响应
log.info(order_list)
交易页面
程序运行返回代码:
点击查看大图
【如果没有打新额度或者没有开通对应的权限,会显示可收购为0】
底下的成功的是可转债申购成功。
然后可以到券商app上看看是否已经有自动申购成功的记录。 查看全部
import time
def initialize(context):
g.flag = False
log.info("initialize g.flag=" + str(g.flag) )
def before_trading_start(context, data):
g.flag = False
log.info("before_trading_start g.flag=" + str(g.flag) )
def handle_data(context, data):
if not g.flag and time.strftime("%H:%M:%S", time.localtime()) > '09:35:00':
# 自动打新
log.info("自动打新")
ipo_stocks_order()
g.flag = True
def on_order_response(context, order_list):
# 该函数会在委托回报返回时响应
log.info(order_list)
交易页面

程序运行返回代码:

【如果没有打新额度或者没有开通对应的权限,会显示可收购为0】
底下的成功的是可转债申购成功。
然后可以到券商app上看看是否已经有自动申购成功的记录。
优矿接口的日期定义真让人蛋疼
股票 • 李魔佛 发表了文章 • 0 个评论 • 2872 次浏览 • 2021-07-17 20:24
然后接口查询结果返回的是YYYY-MM-DD
难道统一一下这么难吗?
然后接口查询结果返回的是YYYY-MM-DD
难道统一一下这么难吗?
优矿数据导出
股票 • 李魔佛 发表了文章 • 0 个评论 • 7862 次浏览 • 2020-12-04 09:11
比如有一个所有股票的dataframe ->df
df.to_csv('all_stock.csv')
然后到左边的数据栏里面,可以在里面看到自己刚刚导出的数据,然后可以选择你刚刚导出的文件,有个选项可以下载,一天可以下载100MB的文件。 查看全部
比如有一个所有股票的dataframe ->df
df.to_csv('all_stock.csv')
然后到左边的数据栏里面,可以在里面看到自己刚刚导出的数据,然后可以选择你刚刚导出的文件,有个选项可以下载,一天可以下载100MB的文件。
基于文本及符号密度的网页正文提取方法 python实现
python • 李魔佛 发表了文章 • 0 个评论 • 6048 次浏览 • 2019-09-10 15:19
项目路径https://github.com/Rockyzsu/CodePool/tree/master/GeneralNewsExtractor
完成后在本文详细介绍,
请密切关注。 查看全部
项目路径https://github.com/Rockyzsu/CodePool/tree/master/GeneralNewsExtractor
完成后在本文详细介绍,
请密切关注。
根据东财股吧爬虫数据进行自然语言分析,展示股市热度
股票 • 李魔佛 发表了文章 • 0 个评论 • 7135 次浏览 • 2019-09-10 09:27
项目开展中.....
https://github.com/Rockyzsu/StockPredict
完工后会把代码搬上来并加注释。
### 2019-11-17 更新 ######
股市舆情情感分类可视化系统
此Web基于Django+Bootstrap+Echarts等框架,个股交易行情数据调用了Tushare接口。对于舆情文本数据采取先爬取东方财富网股吧论坛标题词语设置机器学习训练集,在此基础上运用scikit-learn机器学习朴素贝叶斯方法构建文本分类器。通过Django Web框架,将所得数据传递到前端经过Bootstrap渲染过的html,对数据使用Echarts进行图表可视化处理
不足之处或交流学习欢迎通过邮箱联系我
目前的功能:
个股历史交易行情
个股相关词云展示
情感字典舆情预测
朴素贝叶斯舆情预测
Quick Start
在项目当前目录下: $ python manage.py runserver
浏览器打开127.0.0.1:8000
查看全部
项目开展中.....
https://github.com/Rockyzsu/StockPredict
完工后会把代码搬上来并加注释。
### 2019-11-17 更新 ######
股市舆情情感分类可视化系统
此Web基于Django+Bootstrap+Echarts等框架,个股交易行情数据调用了Tushare接口。对于舆情文本数据采取先爬取东方财富网股吧论坛标题词语设置机器学习训练集,在此基础上运用scikit-learn机器学习朴素贝叶斯方法构建文本分类器。通过Django Web框架,将所得数据传递到前端经过Bootstrap渲染过的html,对数据使用Echarts进行图表可视化处理
不足之处或交流学习欢迎通过邮箱联系我
目前的功能:
个股历史交易行情
个股相关词云展示
情感字典舆情预测
朴素贝叶斯舆情预测

Quick Start
在项目当前目录下: $ python manage.py runserver
浏览器打开127.0.0.1:8000
python分析目前为止科创板企业省份分布
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 6334 次浏览 • 2019-08-26 00:45
首先获取行情数据,借助tushare这个框架:
在python3环境下,pip install tushare --upgrade ,记得要更新,因为用的旧版本会获取不到科创板的数据。
安装成功后试试import tushare as ts,看看有没有报错。没有就是安装成功了。
接下来抓取全市场的行情.
(点击查看大图)
查看前5条数据
现在行情数据存储在df中,然后分析数据。
因为提取的是全市场的数据,然后获取科创板的企业:
(点击查看大图)
使用的是正则表达式,匹配688开头的代码。
接下来就是分析企业归属地:
(点击查看大图)
使用value_counts函数,统计该列每个值出现的次数。
搞定了! 是不是很简单?
而且企业地区分布和自己的构想也差不多,江浙沪一带占了一半,加上北京地区,占了80%以上的科创板企业了。
每周会定期更新一篇python数据分析股票的文章。
原创文章,欢迎转载
请注明出处:
http://30daydo.com/article/528
查看全部
首先获取行情数据,借助tushare这个框架:
在python3环境下,pip install tushare --upgrade ,记得要更新,因为用的旧版本会获取不到科创板的数据。
安装成功后试试import tushare as ts,看看有没有报错。没有就是安装成功了。
接下来抓取全市场的行情.

查看前5条数据
现在行情数据存储在df中,然后分析数据。
因为提取的是全市场的数据,然后获取科创板的企业:

使用的是正则表达式,匹配688开头的代码。
接下来就是分析企业归属地:

使用value_counts函数,统计该列每个值出现的次数。
搞定了! 是不是很简单?
而且企业地区分布和自己的构想也差不多,江浙沪一带占了一半,加上北京地区,占了80%以上的科创板企业了。
每周会定期更新一篇python数据分析股票的文章。
原创文章,欢迎转载
请注明出处:
http://30daydo.com/article/528
截止今天(2019-05-14)银行股今年的涨幅排名
股票 • 李魔佛 发表了文章 • 0 个评论 • 6669 次浏览 • 2019-05-14 23:59
31 601288 农业银行 中国农业银行股份有限公司 -0.341178
11 600015 华夏银行 华夏银行股份有限公司 1.856174
45 601988 中国银行 中国银行股份有限公司 2.248533
32 601328 交通银行 交通银行股份有限公司 3.532657
30 601229 上海银行 上海银行股份有限公司 3.725781
35 601398 工商银行 中国工商银行股份有限公司 4.771403
40 601818 光大银行 中国光大银行股份有限公司 5.643119
27 601169 北京银行 北京银行股份有限公司 6.205580
14 600016 民生银行 中国民生银行股份有限公司 7.092815
5 002936 郑州银行 郑州银行股份有限公司 7.551112
49 601998 中信银行 中信银行股份有限公司 8.181956
43 601939 建设银行 中国建设银行股份有限公司 9.402651
41 601838 成都银行 成都银行股份有限公司 9.424554
52 603323 苏农银行 江苏苏州农村商业银行股份有限公司 12.375732
20 600926 杭州银行 杭州银行股份有限公司 12.933645
8 600000 浦发银行 上海浦东发展银行股份有限公司 14.752244
39 601577 长沙银行 长沙银行股份有限公司 14.792683
18 600908 无锡银行 无锡农村商业银行股份有限公司 16.181704
3 002807 江阴银行 江苏江阴农村商业银行股份有限公司 19.274586
48 601997 贵阳银行 贵阳银行股份有限公司 20.489563
4 002839 张家港行 江苏张家港农村商业银行股份有限公司 20.599511
25 601166 兴业银行 兴业银行股份有限公司 21.206503
24 601128 常熟银行 江苏常熟农村商业银行股份有限公司 21.571187
19 600919 江苏银行 江苏银行股份有限公司 23.218299
22 601009 南京银行 南京银行股份有限公司 26.297500
16 600036 招商银行 招商银行股份有限公司 27.518708
0 000001 平安银行 平安银行股份有限公司 31.624747
2 002142 宁波银行 宁波银行股份有限公司 31.729062
6 002948 青岛银行 青岛银行股份有限公司 48.602573
7 002958 青农商行 青岛农村商业银行股份有限公司 108.983776
42 601860 紫金银行 江苏紫金农村商业银行股份有限公司 115.147347
21 600928 西安银行 西安银行股份有限公司 128.496683 查看全部
ticker secShortName secFullName y_chgPct
31 601288 农业银行 中国农业银行股份有限公司 -0.341178
11 600015 华夏银行 华夏银行股份有限公司 1.856174
45 601988 中国银行 中国银行股份有限公司 2.248533
32 601328 交通银行 交通银行股份有限公司 3.532657
30 601229 上海银行 上海银行股份有限公司 3.725781
35 601398 工商银行 中国工商银行股份有限公司 4.771403
40 601818 光大银行 中国光大银行股份有限公司 5.643119
27 601169 北京银行 北京银行股份有限公司 6.205580
14 600016 民生银行 中国民生银行股份有限公司 7.092815
5 002936 郑州银行 郑州银行股份有限公司 7.551112
49 601998 中信银行 中信银行股份有限公司 8.181956
43 601939 建设银行 中国建设银行股份有限公司 9.402651
41 601838 成都银行 成都银行股份有限公司 9.424554
52 603323 苏农银行 江苏苏州农村商业银行股份有限公司 12.375732
20 600926 杭州银行 杭州银行股份有限公司 12.933645
8 600000 浦发银行 上海浦东发展银行股份有限公司 14.752244
39 601577 长沙银行 长沙银行股份有限公司 14.792683
18 600908 无锡银行 无锡农村商业银行股份有限公司 16.181704
3 002807 江阴银行 江苏江阴农村商业银行股份有限公司 19.274586
48 601997 贵阳银行 贵阳银行股份有限公司 20.489563
4 002839 张家港行 江苏张家港农村商业银行股份有限公司 20.599511
25 601166 兴业银行 兴业银行股份有限公司 21.206503
24 601128 常熟银行 江苏常熟农村商业银行股份有限公司 21.571187
19 600919 江苏银行 江苏银行股份有限公司 23.218299
22 601009 南京银行 南京银行股份有限公司 26.297500
16 600036 招商银行 招商银行股份有限公司 27.518708
0 000001 平安银行 平安银行股份有限公司 31.624747
2 002142 宁波银行 宁波银行股份有限公司 31.729062
6 002948 青岛银行 青岛银行股份有限公司 48.602573
7 002958 青农商行 青岛农村商业银行股份有限公司 108.983776
42 601860 紫金银行 江苏紫金农村商业银行股份有限公司 115.147347
21 600928 西安银行 西安银行股份有限公司 128.496683
【可转债剩余转股比例数据排序】【2019-05-06】
股票 • 李魔佛 发表了文章 • 0 个评论 • 7387 次浏览 • 2019-05-06 15:28
剩余的比例越少,上市公司下调转股价的欲望就越少。 也就是会任由可转债在那里晾着,不会积极拉正股。
数据定期更新。
原创文章,
转载请注明出处:
http://30daydo.com/article/472
查看全部


剩余的比例越少,上市公司下调转股价的欲望就越少。 也就是会任由可转债在那里晾着,不会积极拉正股。
数据定期更新。
原创文章,
转载请注明出处:
http://30daydo.com/article/472

可转债价格分布堆叠图 绘制 可视化 python+pyecharts
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 13208 次浏览 • 2019-01-30 10:59
即使你有很多数据,可是,你无法直观地看到数据的总体趋势。使用可视化的绘图,可以帮助我们看到数据背后看不到的数据。 比如我已经有每一个可转债的价格,评级。数据如下:
点击查看大图
如果我用下面的图形就可以看出规律:
点击查看大图
横坐标是价格,纵坐标是落在该价格的可转债数量,不同颜色代表不同评级的可转债。
可以看到大部分AA-评级(浅橙色)的可转债价格都在100元以下,而AA(浅蓝色)的可转债价格分布较为平均,从90到110都有。而AA+和AAA的一般都在100以上。
那么如何使用代码实现呢?from setting import get_mysql_conn,get_engine
import pandas as pd
import pymongo
from pyecharts import Geo,Style,Map
engine = get_engine('db_stock',local='local')
# 堆叠图
from pyecharts import Bar
df = pd.read_sql('tb_bond_jisilu',con=engine)
result ={}
for name,grades in df.groupby('评级'):
# print(name,grades[['可转债名称','可转债价格']])
for each in grades['可转债价格']:
result.setdefault(name,)
result[name].append(each)
# 确定价格的范围
value = [str(i) for i in range(85,140)]
ret = [0]*len(value)
ret1 = dict(zip(value,ret))
ret_A_add = ret1.copy()
for item in result['A+']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
ret_A_add[k]+=1
retAA_ = ret1.copy()
for item in result['']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
retAA_[k]+=1
retAA = ret1.copy()
for item in result['AA']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
retAA[k]+=1
retAA_add = ret1.copy()
for item in result['AA+']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
retAA_add[k]+=1
retAAA = ret1.copy()
for item in result['AAA']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
retAAA[k]+=1
bar = Bar('可转债价格分布')
bar.add('A+',value,list(ret_A_add.values()),is_stack=True,yaxis_max=11)
bar.add('',value,list(retAA_.values()),is_stack=True,yaxis_max=11)
bar.add('AA',value,list(retAA.values()),is_stack=True,yaxis_max=11)
bar.add('AA+',value,list(retAA_add.values()),is_stack=True,yaxis_max=11)
bar.add('AAA',value,list(retAAA.values()),is_stack=True,yaxis_max=11)
如果没有安装pyecharts,需要用pip安装即可。
原创文章
转载请注明出处:
http://30daydo.com/article/400
查看全部
即使你有很多数据,可是,你无法直观地看到数据的总体趋势。使用可视化的绘图,可以帮助我们看到数据背后看不到的数据。 比如我已经有每一个可转债的价格,评级。数据如下:

点击查看大图
如果我用下面的图形就可以看出规律:

点击查看大图
横坐标是价格,纵坐标是落在该价格的可转债数量,不同颜色代表不同评级的可转债。
可以看到大部分AA-评级(浅橙色)的可转债价格都在100元以下,而AA(浅蓝色)的可转债价格分布较为平均,从90到110都有。而AA+和AAA的一般都在100以上。
那么如何使用代码实现呢?
from setting import get_mysql_conn,get_engine
import pandas as pd
import pymongo
from pyecharts import Geo,Style,Map
engine = get_engine('db_stock',local='local')
# 堆叠图
from pyecharts import Bar
df = pd.read_sql('tb_bond_jisilu',con=engine)
result ={}
for name,grades in df.groupby('评级'):
# print(name,grades[['可转债名称','可转债价格']])
for each in grades['可转债价格']:
result.setdefault(name,)
result[name].append(each)
# 确定价格的范围
value = [str(i) for i in range(85,140)]
ret = [0]*len(value)
ret1 = dict(zip(value,ret))
ret_A_add = ret1.copy()
for item in result['A+']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
ret_A_add[k]+=1
retAA_ = ret1.copy()
for item in result['']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
retAA_[k]+=1
retAA = ret1.copy()
for item in result['AA']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
retAA[k]+=1
retAA_add = ret1.copy()
for item in result['AA+']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
retAA_add[k]+=1
retAAA = ret1.copy()
for item in result['AAA']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
retAAA[k]+=1
bar = Bar('可转债价格分布')
bar.add('A+',value,list(ret_A_add.values()),is_stack=True,yaxis_max=11)
bar.add('',value,list(retAA_.values()),is_stack=True,yaxis_max=11)
bar.add('AA',value,list(retAA.values()),is_stack=True,yaxis_max=11)
bar.add('AA+',value,list(retAA_add.values()),is_stack=True,yaxis_max=11)
bar.add('AAA',value,list(retAAA.values()),is_stack=True,yaxis_max=11)
如果没有安装pyecharts,需要用pip安装即可。
原创文章
转载请注明出处:
http://30daydo.com/article/400
为什么使用talib查找K线形态和优矿上查到的不一样?
股票 • camel 回复了问题 • 2 人关注 • 1 个回复 • 8985 次浏览 • 2018-11-01 20:16
numpy logspace的用法
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 9046 次浏览 • 2018-10-28 17:54
numpy.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None)[source]
Return numbers spaced evenly on a log scale.
In linear space, the sequence starts at base ** start (base to the power of start) and ends with base ** stop (see endpoint below).
Parameters:
start : float
base ** start is the starting value of the sequence.
stop : float
base ** stop is the final value of the sequence, unless endpoint is False. In that case, num + 1 values are spaced over the interval in log-space, of which all but the last (a sequence of length num) are returned.
num : integer, optional
Number of samples to generate. Default is 50.
endpoint : boolean, optional
If true, stop is the last sample. Otherwise, it is not included. Default is True.
base : float, optional
The base of the log space. The step size between the elements in ln(samples) / ln(base) (or log_base(samples)) is uniform. Default is 10.0.
dtype : dtype
The type of the output array. If dtype is not given, infer the data type from the other input arguments.
Returns:
samples : ndarray
num samples, equally spaced on a log scale
上面是官方的文档,英文说的很明白,但网上尤其是csdn的解释,(其实都是你抄我,我抄你),实在让人看的一头雾水
numpy.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None)
比如 np.logspace(0,10,9)
那么会有结果是:
array([1.00000000e+00, 1.77827941e+01, 3.16227766e+02, 5.62341325e+03,
1.00000000e+05, 1.77827941e+06, 3.16227766e+07, 5.62341325e+08,
1.00000000e+10])
第一位是开始值0,第二位是结束值10,然后在这0-10之间产生9个值,这9个值是均匀分布的,默认包括最后一个结束点,就是0到10的9个等产数列,那么根据等差数列的公式,a1+(n-1)*d=an,算出,d=1.25,那么a1=0,接着a2=1.25,a3=2.5,。。。。。a9=10,然后再对这9个值做已10为底的指数运算,也就是10^0, 10^1.25 , 10^2.5 这样的结果 查看全部
numpy.logspace
numpy.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None)[source]
Return numbers spaced evenly on a log scale.
In linear space, the sequence starts at base ** start (base to the power of start) and ends with base ** stop (see endpoint below).
Parameters:
start : float
base ** start is the starting value of the sequence.
stop : float
base ** stop is the final value of the sequence, unless endpoint is False. In that case, num + 1 values are spaced over the interval in log-space, of which all but the last (a sequence of length num) are returned.
num : integer, optional
Number of samples to generate. Default is 50.
endpoint : boolean, optional
If true, stop is the last sample. Otherwise, it is not included. Default is True.
base : float, optional
The base of the log space. The step size between the elements in ln(samples) / ln(base) (or log_base(samples)) is uniform. Default is 10.0.
dtype : dtype
The type of the output array. If dtype is not given, infer the data type from the other input arguments.
Returns:
samples : ndarray
num samples, equally spaced on a log scale
上面是官方的文档,英文说的很明白,但网上尤其是csdn的解释,(其实都是你抄我,我抄你),实在让人看的一头雾水
numpy.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None)
比如 np.logspace(0,10,9)
那么会有结果是:
array([1.00000000e+00, 1.77827941e+01, 3.16227766e+02, 5.62341325e+03,
1.00000000e+05, 1.77827941e+06, 3.16227766e+07, 5.62341325e+08,
1.00000000e+10])
第一位是开始值0,第二位是结束值10,然后在这0-10之间产生9个值,这9个值是均匀分布的,默认包括最后一个结束点,就是0到10的9个等产数列,那么根据等差数列的公式,a1+(n-1)*d=an,算出,d=1.25,那么a1=0,接着a2=1.25,a3=2.5,。。。。。a9=10,然后再对这9个值做已10为底的指数运算,也就是10^0, 10^1.25 , 10^2.5 这样的结果
python数据分析入门 --分析雪球元卫南每个月打赏收入
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 2 个评论 • 10506 次浏览 • 2018-10-24 14:34
最近居然被元神拉黑了。因为帖子不知道被哪位挖坟,估计被元神看到了。
重新跑了下原来的代码,还能跑通,看来雪球并没有改动什么代码。但是雪球经历了一波app下架风波,2019年前的帖子全部无法见到了。
重新获取数据:
点击查看大图
统计数据:
点击查看大图
2019年1月到现在(8月),元神收到的赏金为31851.6,数额比他2019年前所有的金额都要多,虽然总额不高,但是说明了元神这一年影响力大增了。
************************* 写于 2018-11 *******************************
在上一篇 雪球的元卫南靠打赏收割了多少钱 ? python爬虫实例 中,统计出来元卫南所有打赏收入为 24128.13 ,这个数字出乎不少人的意料。因为不少人看到元卫南最近收到的打赏都很多,不少都是100,200的。 那么接下来我就顺便带大家学一下,如何用python做数据分析。
数据来源于上一篇文章中获取到的数据。
首先,从数据库mongodb中读取数据
(点击查看大图)
上面显示数据的前10条,确保数据被正常载入。
观察到列 created_at 是打赏的时间, 导入的数据是字符类型,那么对列 created_at 进行换算, 转化为dataframe中的datetime类型。重新定义一列 pub_date 为打赏时间,设为index,因为dataframe可以对时间index做很多丰富的操作。
(点击查看大图)
可以看到转换后的时间精确到小时,分,秒,而我们需要统计的是每个月(或者每周,每季度,每年都可以)的数据,那么我们就需要重新采样, pandas提供了很好的resample函数,可以对数据按照时间频次进行重新采样。
(点击查看大图)
现在可以看到获取到2018年9月的所有打赏金额的数据。
那么现在就对所有数据进行重采样,并打赏金额进行求和
(点击查看大图)
现在可以看到,每个月得到的打赏金额的总和都可以看到了。从2016年7月到现在2018年10月,最多的月份是这个月,共1.4万,占了所有金额的60%多,所以才让大家造成一个错觉,元兄靠打赏赚了不少粉丝的打赏钱,其实只是最近才多起来的。
还可以绘制条形图。
(点击查看大图)
不过因为月份金额差距过大,导致部分月份的条形显示很短。
不过对于赏金的分布也一目了然了吧。
原创文章
转载请注明出处:
http://30daydo.com/article/362
个人公众号: 查看全部
最近居然被元神拉黑了。因为帖子不知道被哪位挖坟,估计被元神看到了。
重新跑了下原来的代码,还能跑通,看来雪球并没有改动什么代码。但是雪球经历了一波app下架风波,2019年前的帖子全部无法见到了。
重新获取数据:

点击查看大图
统计数据:

点击查看大图
2019年1月到现在(8月),元神收到的赏金为31851.6,数额比他2019年前所有的金额都要多,虽然总额不高,但是说明了元神这一年影响力大增了。
************************* 写于 2018-11 *******************************
在上一篇 雪球的元卫南靠打赏收割了多少钱 ? python爬虫实例 中,统计出来元卫南所有打赏收入为 24128.13 ,这个数字出乎不少人的意料。因为不少人看到元卫南最近收到的打赏都很多,不少都是100,200的。 那么接下来我就顺便带大家学一下,如何用python做数据分析。
数据来源于上一篇文章中获取到的数据。
首先,从数据库mongodb中读取数据


(点击查看大图)
上面显示数据的前10条,确保数据被正常载入。
观察到列 created_at 是打赏的时间, 导入的数据是字符类型,那么对列 created_at 进行换算, 转化为dataframe中的datetime类型。重新定义一列 pub_date 为打赏时间,设为index,因为dataframe可以对时间index做很多丰富的操作。


(点击查看大图)
可以看到转换后的时间精确到小时,分,秒,而我们需要统计的是每个月(或者每周,每季度,每年都可以)的数据,那么我们就需要重新采样, pandas提供了很好的resample函数,可以对数据按照时间频次进行重新采样。

(点击查看大图)
现在可以看到获取到2018年9月的所有打赏金额的数据。
那么现在就对所有数据进行重采样,并打赏金额进行求和

(点击查看大图)
现在可以看到,每个月得到的打赏金额的总和都可以看到了。从2016年7月到现在2018年10月,最多的月份是这个月,共1.4万,占了所有金额的60%多,所以才让大家造成一个错觉,元兄靠打赏赚了不少粉丝的打赏钱,其实只是最近才多起来的。
还可以绘制条形图。

(点击查看大图)
不过因为月份金额差距过大,导致部分月份的条形显示很短。
不过对于赏金的分布也一目了然了吧。
原创文章
转载请注明出处:
http://30daydo.com/article/362
个人公众号:

雪球的元卫南靠打赏收割了多少钱 ? python爬虫实例
python爬虫 • 李魔佛 发表了文章 • 7 个评论 • 33682 次浏览 • 2018-10-23 18:37
今天重新爬了一下,元卫南今年的人气暴涨,在2019年开始到现在,已经获取了31851.6元的打赏金额,虽然金额也不是特别高,但是已经比他2019年前所有打赏金额之和还要高了。 具体分析过程见 http://30daydo.com/article/362
********* 2019-08-05 更新 ***********
文章是去年写的,没想到最近居然在雪球火了。 后续会更新下最新的数据,还有趴一趴释老毛的打赏金额。
雪球的元卫南每天坚持发帖,把一个股民的日常描述的栩栩如生,让人感叹股民的无助与悲哀。 同时也看到上了严重杠杆后,对生活造成的压力,靠着借债来给股票续命。
元卫南雪球链接:https://xueqiu.com/u/2227798650
而且不断有人质疑元卫南写文章,靠打赏金来消费粉丝。 刚开始我也这么觉得,毕竟不少人几十块,一百块的打赏,十几万的粉丝,那每天的收入都很客观呀。 于是抱着好奇心,把元卫南的所有专栏的文章都爬下来,获取每个文章的赏金金额,然后就知道元兄到底靠赏金拿了多少钱。
撸起袖子干。 代码不多,在python3的环境下运行,隐去了header的个人信息,如果在电脑上运行,把你个人的header和cookie加上即可# -*-coding=utf-8-*-
# @Time : 2018/10/23 9:26
# @File : money_reward.py
import requests
from collections import OrderedDict
import time
import datetime
import pymongo
import config
session = requests.Session()
def get_proxy(retry=10):
proxyurl = 'http://{}:8081/dynamicIp/common/getDynamicIp.do'.format(config.PROXY)
count = 0
for i in range(retry):
try:
r = requests.get(proxyurl, timeout=10)
except Exception as e:
print(e)
count += 1
print('代理获取失败,重试' + str(count))
time.sleep(1)
else:
js = r.json()
proxyServer = 'http://{0}:{1}'.format(js.get('ip'), js.get('port'))
proxies_random = {
'http': proxyServer
}
return proxies_random
def get_content(url):
headers = {
# 此处添加个人的header信息
}
try:
proxy = get_proxy()
except Exception as e:
print(e)
proxy = get_proxy()
try:
r = session.get(url=url, headers=headers,proxies=proxy,timeout=10)
except Exception as e:
print(e)
proxy = get_proxy()
r = session.get(url=url, headers=headers,proxies=proxy,timeout=10)
return r
def parse_content(post_id):
url = 'https://xueqiu.com/statuses/reward/list_by_user.json?status_id={}&page=1&size=99999999'.format(post_id)
r = get_content(url)
print(r.text)
if r.status_code != 200:
print('status code != 200')
failed_doc.insert({'post_id':post_id,'status':0})
return None
try:
js_data = r.json()
except Exception as e:
print(e)
print('can not parse to json')
print(post_id)
failed_doc.insert({'post_id': post_id, 'status': 0})
return
ret =
been_reward_user = '元卫南'
for item in js_data.get('items'):
name = item.get('name')
amount = item.get('amount')
description = item.get('description')
user_id = item.get('user_id')
created_at = item.get('created_at')
if created_at:
created_at = datetime.datetime.fromtimestamp(int(created_at) / 1000).strftime('%Y-%m-%d %H:%M:%S')
d = OrderedDict()
d['name'] = name
d['user_id'] = user_id
d['amount'] = amount / 100
d['description'] = description
d['created_at'] = created_at
d['been_reward'] = been_reward_user
ret.append(d)
print(ret)
if ret:
doc.insert_many(ret)
failed_doc.insert({'post_id':post_id,'status':1})
def get_all_page_id(user_id):
doc = db['db_parker']['xueqiu_zhuanglan']
get_page_url = 'https://xueqiu.com/statuses/original/timeline.json?user_id={}&page=1'.format(user_id)
r = get_content(get_page_url)
max_page = int(r.json().get('maxPage'))
for i in range(1, max_page + 1):
url = 'https://xueqiu.com/statuses/original/timeline.json?user_id=2227798650&page={}'.format(i)
r = get_content(url)
js_data = r.json()
ret =
for item in js_data.get('list'):
d = OrderedDict()
d['article_id'] = item.get('id')
d['title'] = item.get('title')
d['description'] = item.get('description')
d['view_count'] = item.get('view_count')
d['target'] = 'https://xueqiu.com/' + item.get('target')
d['user_id']= item.get('user_id')
d['created_at'] = datetime.datetime.fromtimestamp(int(item.get('created_at')) / 1000).strftime(
'%Y-%m-%d %H:%M:%S')
ret.append(d)
print(d)
doc.insert_many(ret)
def loop_page_id():
doc = db['db_parker']['xueqiu_zhuanglan']
ret = doc.find({},{'article_id':1})
failed_doc = db['db_parker']['xueqiu_reward_status']
failed_ret = failed_doc.find({'status':1})
article_id_list =
for i in failed_ret:
article_id_list.append(i.get('article_id'))
for item in ret:
article_id = item.get('article_id')
print(article_id)
if article_id in article_id_list:
continue
else:
parse_content(article_id)
loop_page_id()
然后就是开始爬。
因为使用了代理,所有速度回有点慢,大概10分钟就把所有内容爬完了。
点击查看大图
数据是存储在mongodb数据库中,打开mongodb,可以查看每一条数据,还可以做统计。
点击查看大图
从今天(2018-10-23)追溯到元兄第一篇专栏文章(2014-2-17),元兄总共发了1144篇文章。
点击查看大图
然后再看另外一个打赏的列表
点击查看大图
从最新的开始日期(2018-10-23),这位 金王山而 的用户似乎打赏的很多次,看了是元兄的忠实粉丝。
统计了下,元神共有4222次打赏。
点击查看大图
打赏总金额为:
24128.13
点击查看大图
好吧,太出乎意料了!!! 还以为会有几百万的打赏金额呀,最后算出来才只有24128,这点钱,元兄只够补仓5手东阿阿胶呀。
然后按照打赏金额排序:
点击查看大图
打赏最高金额的是唐史主任,金额为250元,200元的有十来个, 还看到之前梁大师打赏的200元,可以排在并列前10了。
其实大部分人都是拿小钱来打赏下,2元以下就有2621,占了50%了。
还是很支持元神每天坚持发帖,在当前的行情下或可以聊以慰藉,或娱乐大家,或引以为戒,让大家看到股市对散户生活造成的影响,避免重蹈覆辙。
原创文章
转载请注明出处:
http://30daydo.com/article/361
个人公众号:
下篇:
python数据分析入门 分析雪球元卫南每个月打赏收入 查看全部
今天重新爬了一下,元卫南今年的人气暴涨,在2019年开始到现在,已经获取了31851.6元的打赏金额,虽然金额也不是特别高,但是已经比他2019年前所有打赏金额之和还要高了。 具体分析过程见 http://30daydo.com/article/362
********* 2019-08-05 更新 ***********
文章是去年写的,没想到最近居然在雪球火了。 后续会更新下最新的数据,还有趴一趴释老毛的打赏金额。
雪球的元卫南每天坚持发帖,把一个股民的日常描述的栩栩如生,让人感叹股民的无助与悲哀。 同时也看到上了严重杠杆后,对生活造成的压力,靠着借债来给股票续命。
元卫南雪球链接:https://xueqiu.com/u/2227798650
而且不断有人质疑元卫南写文章,靠打赏金来消费粉丝。 刚开始我也这么觉得,毕竟不少人几十块,一百块的打赏,十几万的粉丝,那每天的收入都很客观呀。 于是抱着好奇心,把元卫南的所有专栏的文章都爬下来,获取每个文章的赏金金额,然后就知道元兄到底靠赏金拿了多少钱。
撸起袖子干。 代码不多,在python3的环境下运行,隐去了header的个人信息,如果在电脑上运行,把你个人的header和cookie加上即可
# -*-coding=utf-8-*-
# @Time : 2018/10/23 9:26
# @File : money_reward.py
import requests
from collections import OrderedDict
import time
import datetime
import pymongo
import config
session = requests.Session()
def get_proxy(retry=10):
proxyurl = 'http://{}:8081/dynamicIp/common/getDynamicIp.do'.format(config.PROXY)
count = 0
for i in range(retry):
try:
r = requests.get(proxyurl, timeout=10)
except Exception as e:
print(e)
count += 1
print('代理获取失败,重试' + str(count))
time.sleep(1)
else:
js = r.json()
proxyServer = 'http://{0}:{1}'.format(js.get('ip'), js.get('port'))
proxies_random = {
'http': proxyServer
}
return proxies_random
def get_content(url):
headers = {
# 此处添加个人的header信息
}
try:
proxy = get_proxy()
except Exception as e:
print(e)
proxy = get_proxy()
try:
r = session.get(url=url, headers=headers,proxies=proxy,timeout=10)
except Exception as e:
print(e)
proxy = get_proxy()
r = session.get(url=url, headers=headers,proxies=proxy,timeout=10)
return r
def parse_content(post_id):
url = 'https://xueqiu.com/statuses/reward/list_by_user.json?status_id={}&page=1&size=99999999'.format(post_id)
r = get_content(url)
print(r.text)
if r.status_code != 200:
print('status code != 200')
failed_doc.insert({'post_id':post_id,'status':0})
return None
try:
js_data = r.json()
except Exception as e:
print(e)
print('can not parse to json')
print(post_id)
failed_doc.insert({'post_id': post_id, 'status': 0})
return
ret =
been_reward_user = '元卫南'
for item in js_data.get('items'):
name = item.get('name')
amount = item.get('amount')
description = item.get('description')
user_id = item.get('user_id')
created_at = item.get('created_at')
if created_at:
created_at = datetime.datetime.fromtimestamp(int(created_at) / 1000).strftime('%Y-%m-%d %H:%M:%S')
d = OrderedDict()
d['name'] = name
d['user_id'] = user_id
d['amount'] = amount / 100
d['description'] = description
d['created_at'] = created_at
d['been_reward'] = been_reward_user
ret.append(d)
print(ret)
if ret:
doc.insert_many(ret)
failed_doc.insert({'post_id':post_id,'status':1})
def get_all_page_id(user_id):
doc = db['db_parker']['xueqiu_zhuanglan']
get_page_url = 'https://xueqiu.com/statuses/original/timeline.json?user_id={}&page=1'.format(user_id)
r = get_content(get_page_url)
max_page = int(r.json().get('maxPage'))
for i in range(1, max_page + 1):
url = 'https://xueqiu.com/statuses/original/timeline.json?user_id=2227798650&page={}'.format(i)
r = get_content(url)
js_data = r.json()
ret =
for item in js_data.get('list'):
d = OrderedDict()
d['article_id'] = item.get('id')
d['title'] = item.get('title')
d['description'] = item.get('description')
d['view_count'] = item.get('view_count')
d['target'] = 'https://xueqiu.com/' + item.get('target')
d['user_id']= item.get('user_id')
d['created_at'] = datetime.datetime.fromtimestamp(int(item.get('created_at')) / 1000).strftime(
'%Y-%m-%d %H:%M:%S')
ret.append(d)
print(d)
doc.insert_many(ret)
def loop_page_id():
doc = db['db_parker']['xueqiu_zhuanglan']
ret = doc.find({},{'article_id':1})
failed_doc = db['db_parker']['xueqiu_reward_status']
failed_ret = failed_doc.find({'status':1})
article_id_list =
for i in failed_ret:
article_id_list.append(i.get('article_id'))
for item in ret:
article_id = item.get('article_id')
print(article_id)
if article_id in article_id_list:
continue
else:
parse_content(article_id)
loop_page_id()
然后就是开始爬。
因为使用了代理,所有速度回有点慢,大概10分钟就把所有内容爬完了。

数据是存储在mongodb数据库中,打开mongodb,可以查看每一条数据,还可以做统计。

从今天(2018-10-23)追溯到元兄第一篇专栏文章(2014-2-17),元兄总共发了1144篇文章。

然后再看另外一个打赏的列表

从最新的开始日期(2018-10-23),这位 金王山而 的用户似乎打赏的很多次,看了是元兄的忠实粉丝。
统计了下,元神共有4222次打赏。

打赏总金额为:
24128.13

好吧,太出乎意料了!!! 还以为会有几百万的打赏金额呀,最后算出来才只有24128,这点钱,元兄只够补仓5手东阿阿胶呀。
然后按照打赏金额排序:

打赏最高金额的是唐史主任,金额为250元,200元的有十来个, 还看到之前梁大师打赏的200元,可以排在并列前10了。
其实大部分人都是拿小钱来打赏下,2元以下就有2621,占了50%了。
还是很支持元神每天坚持发帖,在当前的行情下或可以聊以慰藉,或娱乐大家,或引以为戒,让大家看到股市对散户生活造成的影响,避免重蹈覆辙。
原创文章
转载请注明出处:
http://30daydo.com/article/361
个人公众号:
下篇:
python数据分析入门 分析雪球元卫南每个月打赏收入
想写一个爬取开奖数据并预测下一期的py
python爬虫 • 李魔佛 回复了问题 • 2 人关注 • 1 个回复 • 7389 次浏览 • 2018-08-10 00:22
python量化分析: 股票涨停后该不该卖, 怕砸板还是怕卖飞 ?
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 1 个评论 • 9890 次浏览 • 2018-06-14 19:34
那么触及涨停板的个股我们应该继续持有,还是卖掉,还是卖掉做T接回来呢?
接下来用数据说话。【数据使用通联实验室的数据源】
首先获取当前市场上所有股票all_stocks = DataAPI.SecTypeRegionRelGet(secID=u"",ticker=u"",typeID=u"",field=u"",pandas="1")
然后获取每一个股票的日k线数据,可以设定一个时间段,我抓取了2012年到今天(2018-06-14)的所有数据,如果是次新股,那么数据就是上市当天到今天的数据。
抓取到的数据包含以下的字段:
点击查看大图
但是实际用到的字段只有几个, 开盘价,最高价,涨幅,昨天收盘价。
这里我排除了一字板开盘的个股,因为里面含有新股,会导致数据不精确,【后续我会统计,一字板开盘盘中被砸开的概率】,而且数据也排除了ST的个股,因为本人从来不买ST股,所以不会对ST进行统计。fbl =
for code in all_stocks['secID']:
df = DataAPI.MktEqudGet(secID=code,ticker=u"",tradeDate=u"",beginDate=u"20120101",endDate=u"",isOpen="",field=u"",pandas="1")
df['ztj']=map(lambda x:round(x,2),df['preClosePrice']*1.1)
df['chgPct']=df['chgPct']*100
# 非一字板
zt = df[(df['ztj']==df['highestPrice']) & (df['openPrice']!=df['highestPrice'])]
fz= df[(df['ztj']==df['highestPrice']) & (df['openPrice']!=df['highestPrice'])&(df['closePrice']==df['highestPrice'])]
try:
f = len(fz)*1.00/len(zt)*100
fbl.append((code,f))
except Exception,e:
print e
print code
fbl就是封板率的一个列表,包含了每只股票的触及涨停价后封板的概率。 然后对整体的数据取平均值:dx= dict(fbl)
x = np.array(dx.values())
print x.mean()
最后得到的结果是:
64.0866513726
所以保持住涨停的概率还是大一些。所以站在概率大的一边上,触及涨停的时候应该继续持有,会有62.5%会到收盘保持涨停价。
(待续)
原创文章,转载请注明出处:
http://30daydo.com/article/331
查看全部
那么触及涨停板的个股我们应该继续持有,还是卖掉,还是卖掉做T接回来呢?
接下来用数据说话。【数据使用通联实验室的数据源】
首先获取当前市场上所有股票
all_stocks = DataAPI.SecTypeRegionRelGet(secID=u"",ticker=u"",typeID=u"",field=u"",pandas="1")
然后获取每一个股票的日k线数据,可以设定一个时间段,我抓取了2012年到今天(2018-06-14)的所有数据,如果是次新股,那么数据就是上市当天到今天的数据。
抓取到的数据包含以下的字段:

点击查看大图
但是实际用到的字段只有几个, 开盘价,最高价,涨幅,昨天收盘价。
这里我排除了一字板开盘的个股,因为里面含有新股,会导致数据不精确,【后续我会统计,一字板开盘盘中被砸开的概率】,而且数据也排除了ST的个股,因为本人从来不买ST股,所以不会对ST进行统计。
fbl =
for code in all_stocks['secID']:
df = DataAPI.MktEqudGet(secID=code,ticker=u"",tradeDate=u"",beginDate=u"20120101",endDate=u"",isOpen="",field=u"",pandas="1")
df['ztj']=map(lambda x:round(x,2),df['preClosePrice']*1.1)
df['chgPct']=df['chgPct']*100
# 非一字板
zt = df[(df['ztj']==df['highestPrice']) & (df['openPrice']!=df['highestPrice'])]
fz= df[(df['ztj']==df['highestPrice']) & (df['openPrice']!=df['highestPrice'])&(df['closePrice']==df['highestPrice'])]
try:
f = len(fz)*1.00/len(zt)*100
fbl.append((code,f))
except Exception,e:
print e
print code
fbl就是封板率的一个列表,包含了每只股票的触及涨停价后封板的概率。 然后对整体的数据取平均值:
dx= dict(fbl)
x = np.array(dx.values())
print x.mean()
最后得到的结果是:
64.0866513726
所以保持住涨停的概率还是大一些。所以站在概率大的一边上,触及涨停的时候应该继续持有,会有62.5%会到收盘保持涨停价。
(待续)
原创文章,转载请注明出处:
http://30daydo.com/article/331
求港股数据获取PYTHON代码
股票 • 李魔佛 回复了问题 • 3 人关注 • 1 个回复 • 12322 次浏览 • 2018-06-07 16:09
python获取每天的涨停个股数据 和昨天涨停的今天表现
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 14 个评论 • 14853 次浏览 • 2018-06-02 10:47
(点击查看大图)
今日的涨停信息
(点击查看大图)
昨日涨停的今天信息
还有自动生成的K线图:
(点击查看大图)
有兴趣的朋友可以留言获取上述数据
原创文章
转载请注明出处:http://30daydo.com/article/316 查看全部

今日的涨停信息

昨日涨停的今天信息
还有自动生成的K线图:

有兴趣的朋友可以留言获取上述数据
原创文章
转载请注明出处:http://30daydo.com/article/316
正常退出tushare
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 1 个评论 • 5760 次浏览 • 2018-05-07 21:31
查看源码知道ts.get_api() 里面使用了多线程,程序一直在循环等待。 如果按ctrl + c,是无法正常终止tushare在后台的调用,需要使用ts.close_api(conn), 才能终止掉后台的多线程,这个时候程序才能正常退出,释放系统资源。
原创文章
转载请注明出处:http://30daydo.com/article/308
查看全部
查看源码知道ts.get_api() 里面使用了多线程,程序一直在循环等待。 如果按ctrl + c,是无法正常终止tushare在后台的调用,需要使用ts.close_api(conn), 才能终止掉后台的多线程,这个时候程序才能正常退出,释放系统资源。
原创文章
转载请注明出处:http://30daydo.com/article/308
使用优矿获取股市的基本数据 实例操作
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 1 个评论 • 7233 次浏览 • 2018-05-06 22:44
DataAPI.MktRANKInstTrGet
行业名称,如:传媒,电气设备等,可多值输入,以下为申万28个行业名称:休闲服务,房地产,商业贸易,综合,钢铁,农林牧渔,食品饮料,采掘,电子,国防军工,通信,公用事业,交通运输,轻工制造,计算机,电气设备,家用电器,医药生物,传媒,非银金融,汽车,有色金属,机械设备,建筑材料,化工,纺织服装,银行,建筑装饰,可以是列表,可空
实例
原创文章
转载请注明出处:http://30daydo.com/article/306
查看全部
DataAPI.MktRANKInstTrGet
行业名称,如:传媒,电气设备等,可多值输入,以下为申万28个行业名称:休闲服务,房地产,商业贸易,综合,钢铁,农林牧渔,食品饮料,采掘,电子,国防军工,通信,公用事业,交通运输,轻工制造,计算机,电气设备,家用电器,医药生物,传媒,非银金融,汽车,有色金属,机械设备,建筑材料,化工,纺织服装,银行,建筑装饰,可以是列表,可空
实例
原创文章
转载请注明出处:http://30daydo.com/article/306
原来这样的历史日线数据也可以拿来卖的呀
股票 • 李魔佛 发表了文章 • 3 个评论 • 4867 次浏览 • 2018-04-08 22:58
原来这样的数据都可以拿去卖的。 确切的体验到知识就是金钱哈。

原来这样的数据都可以拿去卖的。 确切的体验到知识就是金钱哈。
pandas中resample的how参数“ohlc”
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 2 个评论 • 18790 次浏览 • 2018-03-25 23:42
比如我获取得到了一个股票从14年到现在的开盘,收盘,最高,最低等价格,然后我想对数据中的收盘价重新采样,转换成月数据。可以使用resample函数,参数中的how配合 ohlc。
获取原始数据:
提取收盘价
重新采样:
重新采样后获得的新数据:
可以看到现在的index是每个月的结束,而多了几列,close,open,high,low,这4列就是根据每个月的close价格而提取出来的,比如统计一月份的时候,一月份的收盘价会有一个最低和最高,最开始open1月1号和结束close的1月31号的价格。
原创文章
转载请注明出处:http://30daydo.com/article/288
查看全部
比如我获取得到了一个股票从14年到现在的开盘,收盘,最高,最低等价格,然后我想对数据中的收盘价重新采样,转换成月数据。可以使用resample函数,参数中的how配合 ohlc。
获取原始数据:

提取收盘价

重新采样:

重新采样后获得的新数据:

可以看到现在的index是每个月的结束,而多了几列,close,open,high,low,这4列就是根据每个月的close价格而提取出来的,比如统计一月份的时候,一月份的收盘价会有一个最低和最高,最开始open1月1号和结束close的1月31号的价格。
原创文章
转载请注明出处:http://30daydo.com/article/288
可转债套利【一】 python找出折价可转债个股
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 9 个评论 • 25938 次浏览 • 2018-03-16 17:17
下面的内容默认你对可转债已经有一定的了解。
可转债的价值=正股价格/转股价格 + 利息,忽略可转债的利息,直接用公式 可转债的价值=正股价格/转股价格 计算可转债的价值。
如果当前可转债的交易价格(在交易软件上显示的价格)如:
所以万信转债的价格是121.5元,然后万信转债的价值呢? 按照上面的公式,万信转债的正股是万达信息,今天万达信息 (2018-03-16)的股价是
以收盘价为例,17.25。
而万信转债的股转价格呢? 这个可以到万信转债F10页面的公告中找到,为13.11元。 所以万信转债的价值是
17.25/13.11 = 1.315 , 可转债单位是100, 所以万信转债的内在价值是1.315*100=131.5, 而当前的交易价格为 121.5
也就是你用121.5元买到一个价值 131.5的商品, 所以相当于打折买到了一个超值的商品,所以当前的万信转债是折价状态。
所以本次任务就是要找出可交易的可转债中折价状态的可转债。
然后直接上干货。上python代码。#-*-coding=utf-8
'''
可转债监控
'''
import tushare as ts
from setting import get_engine
engine = get_engine('db_bond')
import pandas as pd
import datetime
class ConvertBond():
def __init__(self):
self.conn=ts.get_apis()
self.allBonds=ts.new_cbonds(pause=2)
self.onSellBond=self.allBonds.dropna(subset=['marketprice'])
self.today=datetime.datetime.now().strftime('%Y-%m-%d %H:%M')
def stockPrice(self,code):
stock_df = ts.get_realtime_quotes(code)
price = float(stock_df['price'].values[0])
return price
def dataframe(self):
price_list=
for code in self.onSellBond['scode']:
price_list.append(self.stockPrice(code))
self.onSellBond['stock_price']=price_list
self.onSellBond['ratio'] = (
self.onSellBond['marketprice']
/(self.onSellBond['stock_price'] / self.onSellBond['convprice'])-1)*100
self.onSellBond['Updated']=self.today
self.onSellBond.to_sql('tb_bond',engine,if_exists='replace')
def closed(self):
ts.close_apis(self.conn)
def main():
bond=ConvertBond()
bond.dataframe()
bond.closed()
if __name__=='__main__':
main()
上面的setting库,把下面的*** 替换成你自己的Mysql用户和密码即可。import os
import MySQLdb
MYSQL_USER = *********
MYSQL_PASSWORD = ********
MYSQL_HOST = *********
MYSQL_PORT = *****
def get_engine(db):
engine = create_engine('mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8'.format(MYSQL_USER, MYSQL_PASSWORD, MYSQL_HOST, MYSQL_PORT, db))
return engine
上面的少于100行的代码就能够满足你的要求。
运行后会把结果保存在MySQL 数据库。如下图所示:
点击放大
2018-03-16 可转债表格
其中折价率是ratio列。按照ratio列进行排列,只有2个是正,也就是当前市场是只有2只可转债是处于折价状态的,其余的都是溢价状态(价格比内在价值要贵,忽略利息的前提下,如果把4~5%的利息也算进去的话,-3~4%的折价率其实也算小折价吧)
目前万信转债折价10个点,宝信转债折价5.8个点。 所以适合低风险投资者建仓。 因为可转债有兜底价格,所以出现亏损的概率很低(除非遇到黑天鹅,公司破产了,像遇到乐视这种PPT独角兽公司,欠债不还的。 但是A股上能够有资格发行可转债的,本身对公司的盈利,分红都有硬性要求)。
所以可以保存上面的代码,可以每天运行一次,可以很方便地找出折价的个股,当然也可以在盘中一直监测,因为可转债的价格是实时变化的,一旦遇到大跌,跌到折价状态,你也可以择时入手标的。
原文链接:
http://30daydo.com/article/286
转载请注明出处
可转债低费率,沪市百万分之二,深圳十万分之四,免五 开户
加微信开通
查看全部
下面的内容默认你对可转债已经有一定的了解。
可转债的价值=正股价格/转股价格 + 利息,忽略可转债的利息,直接用公式 可转债的价值=正股价格/转股价格 计算可转债的价值。
如果当前可转债的交易价格(在交易软件上显示的价格)如:

所以万信转债的价格是121.5元,然后万信转债的价值呢? 按照上面的公式,万信转债的正股是万达信息,今天万达信息 (2018-03-16)的股价是

以收盘价为例,17.25。
而万信转债的股转价格呢? 这个可以到万信转债F10页面的公告中找到,为13.11元。 所以万信转债的价值是
17.25/13.11 = 1.315 , 可转债单位是100, 所以万信转债的内在价值是1.315*100=131.5, 而当前的交易价格为 121.5
也就是你用121.5元买到一个价值 131.5的商品, 所以相当于打折买到了一个超值的商品,所以当前的万信转债是折价状态。
所以本次任务就是要找出可交易的可转债中折价状态的可转债。
然后直接上干货。上python代码。
#-*-coding=utf-8
'''
可转债监控
'''
import tushare as ts
from setting import get_engine
engine = get_engine('db_bond')
import pandas as pd
import datetime
class ConvertBond():
def __init__(self):
self.conn=ts.get_apis()
self.allBonds=ts.new_cbonds(pause=2)
self.onSellBond=self.allBonds.dropna(subset=['marketprice'])
self.today=datetime.datetime.now().strftime('%Y-%m-%d %H:%M')
def stockPrice(self,code):
stock_df = ts.get_realtime_quotes(code)
price = float(stock_df['price'].values[0])
return price
def dataframe(self):
price_list=
for code in self.onSellBond['scode']:
price_list.append(self.stockPrice(code))
self.onSellBond['stock_price']=price_list
self.onSellBond['ratio'] = (
self.onSellBond['marketprice']
/(self.onSellBond['stock_price'] / self.onSellBond['convprice'])-1)*100
self.onSellBond['Updated']=self.today
self.onSellBond.to_sql('tb_bond',engine,if_exists='replace')
def closed(self):
ts.close_apis(self.conn)
def main():
bond=ConvertBond()
bond.dataframe()
bond.closed()
if __name__=='__main__':
main()
上面的setting库,把下面的*** 替换成你自己的Mysql用户和密码即可。
import os
import MySQLdb
MYSQL_USER = *********
MYSQL_PASSWORD = ********
MYSQL_HOST = *********
MYSQL_PORT = *****
def get_engine(db):
engine = create_engine('mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8'.format(MYSQL_USER, MYSQL_PASSWORD, MYSQL_HOST, MYSQL_PORT, db))
return engine
上面的少于100行的代码就能够满足你的要求。
运行后会把结果保存在MySQL 数据库。如下图所示:

点击放大
2018-03-16 可转债表格
其中折价率是ratio列。按照ratio列进行排列,只有2个是正,也就是当前市场是只有2只可转债是处于折价状态的,其余的都是溢价状态(价格比内在价值要贵,忽略利息的前提下,如果把4~5%的利息也算进去的话,-3~4%的折价率其实也算小折价吧)
目前万信转债折价10个点,宝信转债折价5.8个点。 所以适合低风险投资者建仓。 因为可转债有兜底价格,所以出现亏损的概率很低(除非遇到黑天鹅,公司破产了,像遇到乐视这种PPT独角兽公司,欠债不还的。 但是A股上能够有资格发行可转债的,本身对公司的盈利,分红都有硬性要求)。
所以可以保存上面的代码,可以每天运行一次,可以很方便地找出折价的个股,当然也可以在盘中一直监测,因为可转债的价格是实时变化的,一旦遇到大跌,跌到折价状态,你也可以择时入手标的。
原文链接:
http://30daydo.com/article/286
转载请注明出处
可转债低费率,沪市百万分之二,深圳十万分之四,免五 开户
加微信开通

tushare 调用ts.get_apis() 后一直在运行无法退出
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 6072 次浏览 • 2018-03-16 00:47
conn=ts.get_apis()
......
在你的程序退出前,运行
ts.close_apis(conn)
这样你的程序就能够正常退出。 查看全部
conn=ts.get_apis()
......
在你的程序退出前,运行
ts.close_apis(conn)
这样你的程序就能够正常退出。
python监测股票出现的规律大单
股票 • 李魔佛 发表了文章 • 2 个评论 • 7038 次浏览 • 2018-02-27 12:03
首先获取当日的历史分笔数据
code='300527'
df = ts.get_today_ticks(code)
然后根据成交量进行排序:
df.sort_values(by='volume',ascending=False).head(100)显示前100的成交量。
从上面的表格可以看到,不断有1500手的卖盘,而且卖出价格比正常的药低3个点,所谓的砸盘。
但是每次砸完了价格又会正常的回来原来的地方。 从分时走势上也可以看到一个个凸起的大单成交量。
每次打压完,股价还会正常回到原来的位置。 个人觉得这个是有人在出货,但是不断有人在接货。是不同的两伙人。 查看全部
首先获取当日的历史分笔数据
code='300527'
df = ts.get_today_ticks(code)
然后根据成交量进行排序:
df.sort_values(by='volume',ascending=False).head(100)显示前100的成交量。

从上面的表格可以看到,不断有1500手的卖盘,而且卖出价格比正常的药低3个点,所谓的砸盘。
但是每次砸完了价格又会正常的回来原来的地方。 从分时走势上也可以看到一个个凸起的大单成交量。

每次打压完,股价还会正常回到原来的位置。 个人觉得这个是有人在出货,但是不断有人在接货。是不同的两伙人。
【量化选股】A股上有哪些东北股(排雷)?
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 4931 次浏览 • 2018-01-31 01:09
打开jupyter notebook。然后输入下面的代码:
上面可以获得A股上市公司所有区域的分布。果然刘士余上台后,浙江地区的企业一下子超越广东,成为A股最多公司的省份(当然,这里的广东是把深圳给单独分离出去了),浙江有418个上市公司。
然后根据条件筛选列area,选出辽宁,吉林,黑龙江的企业。
共有152家上市公司。截止2018-01-30日。
列表太长没有显示完整,贴在附件里面供大家参考(排雷)。
原文地址:http://30daydo.com/article/271
转载请注明出处 查看全部
打开jupyter notebook。然后输入下面的代码:

上面可以获得A股上市公司所有区域的分布。果然刘士余上台后,浙江地区的企业一下子超越广东,成为A股最多公司的省份(当然,这里的广东是把深圳给单独分离出去了),浙江有418个上市公司。
然后根据条件筛选列area,选出辽宁,吉林,黑龙江的企业。

共有152家上市公司。截止2018-01-30日。
列表太长没有显示完整,贴在附件里面供大家参考(排雷)。
原文地址:http://30daydo.com/article/271
转载请注明出处
可转债价格分布堆叠图 绘制 可视化 python+pyecharts
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 13208 次浏览 • 2019-01-30 10:59
即使你有很多数据,可是,你无法直观地看到数据的总体趋势。使用可视化的绘图,可以帮助我们看到数据背后看不到的数据。 比如我已经有每一个可转债的价格,评级。数据如下:
点击查看大图
如果我用下面的图形就可以看出规律:
点击查看大图
横坐标是价格,纵坐标是落在该价格的可转债数量,不同颜色代表不同评级的可转债。
可以看到大部分AA-评级(浅橙色)的可转债价格都在100元以下,而AA(浅蓝色)的可转债价格分布较为平均,从90到110都有。而AA+和AAA的一般都在100以上。
那么如何使用代码实现呢?from setting import get_mysql_conn,get_engine
import pandas as pd
import pymongo
from pyecharts import Geo,Style,Map
engine = get_engine('db_stock',local='local')
# 堆叠图
from pyecharts import Bar
df = pd.read_sql('tb_bond_jisilu',con=engine)
result ={}
for name,grades in df.groupby('评级'):
# print(name,grades[['可转债名称','可转债价格']])
for each in grades['可转债价格']:
result.setdefault(name,)
result[name].append(each)
# 确定价格的范围
value = [str(i) for i in range(85,140)]
ret = [0]*len(value)
ret1 = dict(zip(value,ret))
ret_A_add = ret1.copy()
for item in result['A+']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
ret_A_add[k]+=1
retAA_ = ret1.copy()
for item in result['']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
retAA_[k]+=1
retAA = ret1.copy()
for item in result['AA']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
retAA[k]+=1
retAA_add = ret1.copy()
for item in result['AA+']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
retAA_add[k]+=1
retAAA = ret1.copy()
for item in result['AAA']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
retAAA[k]+=1
bar = Bar('可转债价格分布')
bar.add('A+',value,list(ret_A_add.values()),is_stack=True,yaxis_max=11)
bar.add('',value,list(retAA_.values()),is_stack=True,yaxis_max=11)
bar.add('AA',value,list(retAA.values()),is_stack=True,yaxis_max=11)
bar.add('AA+',value,list(retAA_add.values()),is_stack=True,yaxis_max=11)
bar.add('AAA',value,list(retAAA.values()),is_stack=True,yaxis_max=11)
如果没有安装pyecharts,需要用pip安装即可。
原创文章
转载请注明出处:
http://30daydo.com/article/400
查看全部
即使你有很多数据,可是,你无法直观地看到数据的总体趋势。使用可视化的绘图,可以帮助我们看到数据背后看不到的数据。 比如我已经有每一个可转债的价格,评级。数据如下:
点击查看大图
如果我用下面的图形就可以看出规律:
点击查看大图
横坐标是价格,纵坐标是落在该价格的可转债数量,不同颜色代表不同评级的可转债。
可以看到大部分AA-评级(浅橙色)的可转债价格都在100元以下,而AA(浅蓝色)的可转债价格分布较为平均,从90到110都有。而AA+和AAA的一般都在100以上。
那么如何使用代码实现呢?
from setting import get_mysql_conn,get_engine
import pandas as pd
import pymongo
from pyecharts import Geo,Style,Map
engine = get_engine('db_stock',local='local')
# 堆叠图
from pyecharts import Bar
df = pd.read_sql('tb_bond_jisilu',con=engine)
result ={}
for name,grades in df.groupby('评级'):
# print(name,grades[['可转债名称','可转债价格']])
for each in grades['可转债价格']:
result.setdefault(name,)
result[name].append(each)
# 确定价格的范围
value = [str(i) for i in range(85,140)]
ret = [0]*len(value)
ret1 = dict(zip(value,ret))
ret_A_add = ret1.copy()
for item in result['A+']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
ret_A_add[k]+=1
retAA_ = ret1.copy()
for item in result['']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
retAA_[k]+=1
retAA = ret1.copy()
for item in result['AA']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
retAA[k]+=1
retAA_add = ret1.copy()
for item in result['AA+']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
retAA_add[k]+=1
retAAA = ret1.copy()
for item in result['AAA']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
retAAA[k]+=1
bar = Bar('可转债价格分布')
bar.add('A+',value,list(ret_A_add.values()),is_stack=True,yaxis_max=11)
bar.add('',value,list(retAA_.values()),is_stack=True,yaxis_max=11)
bar.add('AA',value,list(retAA.values()),is_stack=True,yaxis_max=11)
bar.add('AA+',value,list(retAA_add.values()),is_stack=True,yaxis_max=11)
bar.add('AAA',value,list(retAAA.values()),is_stack=True,yaxis_max=11)
如果没有安装pyecharts,需要用pip安装即可。
原创文章
转载请注明出处:
http://30daydo.com/article/400
可转债套利【一】 python找出折价可转债个股
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 9 个评论 • 25938 次浏览 • 2018-03-16 17:17
下面的内容默认你对可转债已经有一定的了解。
可转债的价值=正股价格/转股价格 + 利息,忽略可转债的利息,直接用公式 可转债的价值=正股价格/转股价格 计算可转债的价值。
如果当前可转债的交易价格(在交易软件上显示的价格)如:
所以万信转债的价格是121.5元,然后万信转债的价值呢? 按照上面的公式,万信转债的正股是万达信息,今天万达信息 (2018-03-16)的股价是
以收盘价为例,17.25。
而万信转债的股转价格呢? 这个可以到万信转债F10页面的公告中找到,为13.11元。 所以万信转债的价值是
17.25/13.11 = 1.315 , 可转债单位是100, 所以万信转债的内在价值是1.315*100=131.5, 而当前的交易价格为 121.5
也就是你用121.5元买到一个价值 131.5的商品, 所以相当于打折买到了一个超值的商品,所以当前的万信转债是折价状态。
所以本次任务就是要找出可交易的可转债中折价状态的可转债。
然后直接上干货。上python代码。#-*-coding=utf-8
'''
可转债监控
'''
import tushare as ts
from setting import get_engine
engine = get_engine('db_bond')
import pandas as pd
import datetime
class ConvertBond():
def __init__(self):
self.conn=ts.get_apis()
self.allBonds=ts.new_cbonds(pause=2)
self.onSellBond=self.allBonds.dropna(subset=['marketprice'])
self.today=datetime.datetime.now().strftime('%Y-%m-%d %H:%M')
def stockPrice(self,code):
stock_df = ts.get_realtime_quotes(code)
price = float(stock_df['price'].values[0])
return price
def dataframe(self):
price_list=
for code in self.onSellBond['scode']:
price_list.append(self.stockPrice(code))
self.onSellBond['stock_price']=price_list
self.onSellBond['ratio'] = (
self.onSellBond['marketprice']
/(self.onSellBond['stock_price'] / self.onSellBond['convprice'])-1)*100
self.onSellBond['Updated']=self.today
self.onSellBond.to_sql('tb_bond',engine,if_exists='replace')
def closed(self):
ts.close_apis(self.conn)
def main():
bond=ConvertBond()
bond.dataframe()
bond.closed()
if __name__=='__main__':
main()
上面的setting库,把下面的*** 替换成你自己的Mysql用户和密码即可。import os
import MySQLdb
MYSQL_USER = *********
MYSQL_PASSWORD = ********
MYSQL_HOST = *********
MYSQL_PORT = *****
def get_engine(db):
engine = create_engine('mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8'.format(MYSQL_USER, MYSQL_PASSWORD, MYSQL_HOST, MYSQL_PORT, db))
return engine
上面的少于100行的代码就能够满足你的要求。
运行后会把结果保存在MySQL 数据库。如下图所示:
点击放大
2018-03-16 可转债表格
其中折价率是ratio列。按照ratio列进行排列,只有2个是正,也就是当前市场是只有2只可转债是处于折价状态的,其余的都是溢价状态(价格比内在价值要贵,忽略利息的前提下,如果把4~5%的利息也算进去的话,-3~4%的折价率其实也算小折价吧)
目前万信转债折价10个点,宝信转债折价5.8个点。 所以适合低风险投资者建仓。 因为可转债有兜底价格,所以出现亏损的概率很低(除非遇到黑天鹅,公司破产了,像遇到乐视这种PPT独角兽公司,欠债不还的。 但是A股上能够有资格发行可转债的,本身对公司的盈利,分红都有硬性要求)。
所以可以保存上面的代码,可以每天运行一次,可以很方便地找出折价的个股,当然也可以在盘中一直监测,因为可转债的价格是实时变化的,一旦遇到大跌,跌到折价状态,你也可以择时入手标的。
原文链接:
http://30daydo.com/article/286
转载请注明出处
可转债低费率,沪市百万分之二,深圳十万分之四,免五 开户
加微信开通
查看全部
下面的内容默认你对可转债已经有一定的了解。
可转债的价值=正股价格/转股价格 + 利息,忽略可转债的利息,直接用公式 可转债的价值=正股价格/转股价格 计算可转债的价值。
如果当前可转债的交易价格(在交易软件上显示的价格)如:
所以万信转债的价格是121.5元,然后万信转债的价值呢? 按照上面的公式,万信转债的正股是万达信息,今天万达信息 (2018-03-16)的股价是
以收盘价为例,17.25。
而万信转债的股转价格呢? 这个可以到万信转债F10页面的公告中找到,为13.11元。 所以万信转债的价值是
17.25/13.11 = 1.315 , 可转债单位是100, 所以万信转债的内在价值是1.315*100=131.5, 而当前的交易价格为 121.5
也就是你用121.5元买到一个价值 131.5的商品, 所以相当于打折买到了一个超值的商品,所以当前的万信转债是折价状态。
所以本次任务就是要找出可交易的可转债中折价状态的可转债。
然后直接上干货。上python代码。
#-*-coding=utf-8
'''
可转债监控
'''
import tushare as ts
from setting import get_engine
engine = get_engine('db_bond')
import pandas as pd
import datetime
class ConvertBond():
def __init__(self):
self.conn=ts.get_apis()
self.allBonds=ts.new_cbonds(pause=2)
self.onSellBond=self.allBonds.dropna(subset=['marketprice'])
self.today=datetime.datetime.now().strftime('%Y-%m-%d %H:%M')
def stockPrice(self,code):
stock_df = ts.get_realtime_quotes(code)
price = float(stock_df['price'].values[0])
return price
def dataframe(self):
price_list=
for code in self.onSellBond['scode']:
price_list.append(self.stockPrice(code))
self.onSellBond['stock_price']=price_list
self.onSellBond['ratio'] = (
self.onSellBond['marketprice']
/(self.onSellBond['stock_price'] / self.onSellBond['convprice'])-1)*100
self.onSellBond['Updated']=self.today
self.onSellBond.to_sql('tb_bond',engine,if_exists='replace')
def closed(self):
ts.close_apis(self.conn)
def main():
bond=ConvertBond()
bond.dataframe()
bond.closed()
if __name__=='__main__':
main()
上面的setting库,把下面的*** 替换成你自己的Mysql用户和密码即可。
import os
import MySQLdb
MYSQL_USER = *********
MYSQL_PASSWORD = ********
MYSQL_HOST = *********
MYSQL_PORT = *****
def get_engine(db):
engine = create_engine('mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8'.format(MYSQL_USER, MYSQL_PASSWORD, MYSQL_HOST, MYSQL_PORT, db))
return engine
上面的少于100行的代码就能够满足你的要求。
运行后会把结果保存在MySQL 数据库。如下图所示:
点击放大
2018-03-16 可转债表格
其中折价率是ratio列。按照ratio列进行排列,只有2个是正,也就是当前市场是只有2只可转债是处于折价状态的,其余的都是溢价状态(价格比内在价值要贵,忽略利息的前提下,如果把4~5%的利息也算进去的话,-3~4%的折价率其实也算小折价吧)
目前万信转债折价10个点,宝信转债折价5.8个点。 所以适合低风险投资者建仓。 因为可转债有兜底价格,所以出现亏损的概率很低(除非遇到黑天鹅,公司破产了,像遇到乐视这种PPT独角兽公司,欠债不还的。 但是A股上能够有资格发行可转债的,本身对公司的盈利,分红都有硬性要求)。
所以可以保存上面的代码,可以每天运行一次,可以很方便地找出折价的个股,当然也可以在盘中一直监测,因为可转债的价格是实时变化的,一旦遇到大跌,跌到折价状态,你也可以择时入手标的。
原文链接:
http://30daydo.com/article/286
转载请注明出处
可转债低费率,沪市百万分之二,深圳十万分之四,免五 开户
加微信开通
dataframe reindex和reset_index区别
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 90383 次浏览 • 2017-12-30 15:58
df2 = pd.DataFrame({'A': [6], 'B': [60]})
print('df', df)
print('df2', df2)
df_x = [df, df2]
result = pd.concat(df_x)
print('first result ', result)
上面代码把df和df2合并为一个result,但是result的index是乱的。
那么执行result2= result.reset_index()
得到如下的result2: (默认只是返回一个copy,原来的result没有发生改变,所以需要副本赋值给result2)
可以看到,原来的一列index现在变成了columns之一,新的index为[0,1,2,3,4,5]
如果添加参数 reset_index(drop=True) 那么原index会被丢弃,不会显示为一个新列。result2 = result.reset_index(drop=True)
reindex的作用是按照原有的列进行重新生成一个新的df。
还是使用上面的代码
result目前是df和df2的合并序列。
如下:
可以看到index为[0,1,2,3,4,0]
执行 result3 = result.reindex(columns=['A','C'])
可以看到,原index并没有发生改变,而列变成了A和C,因为C是不存在的,所以使用了NaB填充,这个值的内容可以自己填充,可以改为默认填充0或者任意你想要的数据。reindex(columns=..)的作用类似于重新把列的顺序整理一遍, 而使用reindex(index=....) 则按照行重新整理一遍。
原文链接:http://30daydo.com/article/257
欢迎转载,注明出处
查看全部
df = pd.DataFrame({'A': [1, 2, 3, 4, 5], 'B': [10, 20, 30, 40, 50]})
df2 = pd.DataFrame({'A': [6], 'B': [60]})
print('df', df)
print('df2', df2)
df_x = [df, df2]
result = pd.concat(df_x)
print('first result ', result) 上面代码把df和df2合并为一个result,但是result的index是乱的。

那么执行
result2= result.reset_index()
得到如下的result2: (默认只是返回一个copy,原来的result没有发生改变,所以需要副本赋值给result2)

可以看到,原来的一列index现在变成了columns之一,新的index为[0,1,2,3,4,5]
如果添加参数 reset_index(drop=True) 那么原index会被丢弃,不会显示为一个新列。
result2 = result.reset_index(drop=True)

reindex的作用是按照原有的列进行重新生成一个新的df。
还是使用上面的代码
result目前是df和df2的合并序列。
如下:

可以看到index为[0,1,2,3,4,0]
执行
result3 = result.reindex(columns=['A','C'])
可以看到,原index并没有发生改变,而列变成了A和C,因为C是不存在的,所以使用了NaB填充,这个值的内容可以自己填充,可以改为默认填充0或者任意你想要的数据。reindex(columns=..)的作用类似于重新把列的顺序整理一遍, 而使用reindex(index=....) 则按照行重新整理一遍。
原文链接:http://30daydo.com/article/257
欢迎转载,注明出处
如何使用pandas把某些行的数据进行算术处理?
回复量化交易-Ptrade-QMT • 李魔佛 发起了问题 • 1 人关注 • 0 个回复 • 8300 次浏览 • 2016-07-28 15:35
6行python代码 获取通达信的可转债分时数据
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 4161 次浏览 • 2022-08-27 14:33
api = TdxHq_API()
with api.connect('119.147.212.81', 7709):
data = api.get_security_bars(7, 0, '123045', 0, 240) # 123045 为转债代码 ,240 为获取 240个转债数据
df = api.to_df(data)
df=df.sort_values('datetime')
点击查看大图
如果需要遍历当前最新可转债代码(集思录),需要结合前面的文章。
公众号:
查看全部
from pytdx.hq import TdxHq_API
api = TdxHq_API()
with api.connect('119.147.212.81', 7709):
data = api.get_security_bars(7, 0, '123045', 0, 240) # 123045 为转债代码 ,240 为获取 240个转债数据
df = api.to_df(data)
df=df.sort_values('datetime')
如果需要遍历当前最新可转债代码(集思录),需要结合前面的文章。
公众号:
ptrade如何以指定价格下单?
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 4234 次浏览 • 2022-07-30 19:27
order函数:order-按数量买卖
order(security, amount, limit_price=None)
买卖标的。
注意:
由于下述原因,回测中实际买入或者卖出的股票数量有时候可能与委托设置的不一样,针对上述内容调整,系统会在日志中增加警告信息:
根据委托买入数量与价格经计算后的资金数量,大于当前可用资金;
委托卖出数量大于当前可用持仓数量;
每次交易数量只能是100的整数倍,但是卖出所有股票时不受此限制;
股票停牌、股票未上市或者退市、股票不存在;
回测中每天结束时会取消所有未完成交易;
order_target - 函数order_target(security, amount, limit_price=None)
买卖股票,直到股票最终数量达到指定的amount。
注意:该函数在委托股票时取整100股,委托可转债时取整100张。
参数
security: 股票代码(str);
amount: 期望的最终数量(int);
limit_price:买卖限价(float);
返回
Order对象中的id或者None。如果创建订单成功,则返回Order对象的id,失败则返回None(str)。
order_value 函数order_value - 指定目标价值买卖
order_value(security, value, limit_price=None)
买卖指定价值为value的股票。
注意:该函数在委托股票时取整100股,委托可转债时取整100张。
order_target_value - 函数order_target_value - 指定持仓市值买卖
order_target_value(security, value, limit_price=None)
调整股票仓位到value价值
注意:该函数在委托股票时取整100股,委托可转债时取整100张。
order_market 函数order_market - 按市价进行委托
order_market(security, amount, market_type=None, limit_price=None)
可以使用多种市价类型进行委托。
注意:该函数仅在股票交易模块可用。
上面几个在handle_data中使用的下单函数,都是无法指定价格的,limit_price 只是用于限价,比如你要卖1000股,limit_price的作用是不要把价格卖出你的目标,至于多少卖,是无法控制的。
但是有一个tick_data函数,专门用于行情交易的,里面可调用的函数也很少。tick_data(可选)
tick_data(context, data)
该函数会每隔3秒执行一次。
注意 :
该函数仅在交易模块可用。
该函数在9:30之后才能执行。
该函数中只能使用order_tick进行对应的下单操作。里面下单,用的下单函数是
order_tick - tick行情触发买卖
order_tick(sid, amount, priceGear='1', limit_price=None)
买卖股票下单,可设定价格档位进行委托
注意:该函数仅在交易模块可用。
参数
sid:股票代码(str);
amount:交易数量,正数表示买入,负数表示卖出(int)
priceGear:盘口档位,level1:1~5买档/-1~-5卖档,level2:1~10买档/-1~-10卖档(str)
limit_price:买卖限价,当输入参数中也包含priceGear时,下单价格以limit_price为主(float);
注意到里面:
limit_price:买卖限价,当输入参数中也包含priceGear时,下单价格以limit_price为主
发现这里面居然可以定义价格下单,所以如果一定要指定价格,就需要使用tick_data 触发。
使用代码:
def initialize(context):
g.security = "600570.SS"
set_universe(g.security)
def tick_data(context,data):
security = g.security
current_price = eval(data[security]['tick']['bid_grp'][0])[1][0]
if current_price > 56 and current_price < 57:
# 以买一档下单
order_tick(g.security, -100, "1")
# 以卖二档下单
order_tick(g.security, 100, "-2")
# 以指定价格下单
order_tick(g.security, 100, limit_price=56.5)
def handle_data(context, data):
pass 查看全部
order函数:
order-按数量买卖
order(security, amount, limit_price=None)
买卖标的。
注意:
由于下述原因,回测中实际买入或者卖出的股票数量有时候可能与委托设置的不一样,针对上述内容调整,系统会在日志中增加警告信息:
根据委托买入数量与价格经计算后的资金数量,大于当前可用资金;
委托卖出数量大于当前可用持仓数量;
每次交易数量只能是100的整数倍,但是卖出所有股票时不受此限制;
股票停牌、股票未上市或者退市、股票不存在;
回测中每天结束时会取消所有未完成交易;
order_target - 函数
order_target(security, amount, limit_price=None)
买卖股票,直到股票最终数量达到指定的amount。
注意:该函数在委托股票时取整100股,委托可转债时取整100张。
参数
security: 股票代码(str);
amount: 期望的最终数量(int);
limit_price:买卖限价(float);
返回
Order对象中的id或者None。如果创建订单成功,则返回Order对象的id,失败则返回None(str)。
order_value 函数
order_value - 指定目标价值买卖
order_value(security, value, limit_price=None)
买卖指定价值为value的股票。
注意:该函数在委托股票时取整100股,委托可转债时取整100张。
order_target_value - 函数
order_target_value - 指定持仓市值买卖
order_target_value(security, value, limit_price=None)
调整股票仓位到value价值
注意:该函数在委托股票时取整100股,委托可转债时取整100张。
order_market 函数
order_market - 按市价进行委托
order_market(security, amount, market_type=None, limit_price=None)
可以使用多种市价类型进行委托。
注意:该函数仅在股票交易模块可用。
上面几个在handle_data中使用的下单函数,都是无法指定价格的,limit_price 只是用于限价,比如你要卖1000股,limit_price的作用是不要把价格卖出你的目标,至于多少卖,是无法控制的。
但是有一个tick_data函数,专门用于行情交易的,里面可调用的函数也很少。
tick_data(可选)里面下单,用的下单函数是
tick_data(context, data)
该函数会每隔3秒执行一次。
注意 :
该函数仅在交易模块可用。
该函数在9:30之后才能执行。
该函数中只能使用order_tick进行对应的下单操作。
order_tick - tick行情触发买卖
order_tick(sid, amount, priceGear='1', limit_price=None)
买卖股票下单,可设定价格档位进行委托
注意:该函数仅在交易模块可用。
参数
sid:股票代码(str);
amount:交易数量,正数表示买入,负数表示卖出(int)
priceGear:盘口档位,level1:1~5买档/-1~-5卖档,level2:1~10买档/-1~-10卖档(str)
limit_price:买卖限价,当输入参数中也包含priceGear时,下单价格以limit_price为主(float);
注意到里面:
limit_price:买卖限价,当输入参数中也包含priceGear时,下单价格以limit_price为主
发现这里面居然可以定义价格下单,所以如果一定要指定价格,就需要使用tick_data 触发。
使用代码:
def initialize(context):
g.security = "600570.SS"
set_universe(g.security)
def tick_data(context,data):
security = g.security
current_price = eval(data[security]['tick']['bid_grp'][0])[1][0]
if current_price > 56 and current_price < 57:
# 以买一档下单
order_tick(g.security, -100, "1")
# 以卖二档下单
order_tick(g.security, 100, "-2")
# 以指定价格下单
order_tick(g.security, 100, limit_price=56.5)
def handle_data(context, data):
pass
国盛证券qmt mini模式 xtquant
券商万一免五 • 李魔佛 发表了文章 • 0 个评论 • 14383 次浏览 • 2022-07-29 01:00
【国盛QMT支持 xtquant qmt mini模式】
mini模式可以在外部运行,同时可以下载历史tick数据。xtdata是xtquant库中提供行情相关数据的模块,本模块旨在提供精简直接的数据满足量化交易者的数
据需求,作为python库的形式可以被灵活添加到各种策略脚本中。
主要提供行情数据(历史和实时的K线和分笔)、财务数据、合约基础信息、板块和行业分类信息等通
用的行情数据
可以直接获取level2的数据
使用python代码直接运行,不用在qmt软件里面憋屈地写代码,可直接使用pycharm,vscode编写,且有代码提示,补全,好用多了。
附一个完整的策略例子。
保存为: demo.py
命令行下运行:
python demo.py# 创建策略
#coding=utf-8
from xtquant.xttrader import XtQuantTrader, XtQuantTraderCallback
from xtquant.xtquant import StockAccount
from xtquant import xtconstant
class MyXtQuantTraderCallback(XtQuantTraderCallback):
def on_disconnected(self):
"""
连接断开
:return:
"""
print("connection lost")
def on_stock_order(self, order):
"""
委托回报推送
:param order: XtOrder对象
:return:
"""
print("on order callback:")
print(order.stock_code, order.order_status, order.order_sysid)
def on_stock_asset(self, asset):
"""
资金变动推送
:param asset: XtAsset对象
:return:
"""
print("on asset callback")
print(asset.account_id, asset.cash, asset.total_asset)
def on_stock_trade(self, trade):
"""
成交变动推送
:param trade: XtTrade对象
:return:
"""
print("on trade callback")
print(trade.account_id, trade.stock_code, trade.order_id)
def on_stock_position(self, position):
"""
持仓变动推送
:param position: XtPosition对象
:return:
"""
print("on position callback")
print(position.stock_code, position.volume)
def on_order_error(self, order_error):
"""
委托失败推送
:param order_error:XtOrderError 对象
:return:
"""
print("on order_error callback")
print(order_error.order_id, order_error.error_id, order_error.error_msg)
def on_cancel_error(self, cancel_error):
"""
撤单失败推送
:param cancel_error: XtCancelError 对象
:return:
"""
print("on cancel_error callback")
print(cancel_error.order_id, cancel_error.error_id,
cancel_error.error_msg)
def on_order_stock_async_response(self, response):
"""
异步下单回报推送
:param response: XtOrderResponse 对象
:return:
"""
print("on_order_stock_async_response")
print(response.account_id, response.order_id, response.seq)
if __name__ == "__main__":
print("demo test")
# path为mini qmt客户端安装目录下userdata_mini路径
path = 'D:\\迅投极速交易终端 睿智融科版\\userdata_mini'
# session_id为会话编号,策略使用方对于不同的Python策略需要使用不同的会话编号
session_id = 123456
xt_trader = XtQuantTrader(path, session_id)
# 创建资金账号为1000000365的证券账号对象
acc = StockAccount('1000000365')
# 创建交易回调类对象,并声明接收回调
callback = MyXtQuantTraderCallback()
xt_trader.register_callback(callback)
# 启动交易线程
xt_trader.start()
# 建立交易连接,返回0表示连接成功
connect_result = xt_trader.connect()
print(connect_result)
# 对交易回调进行订阅,订阅后可以收到交易主推,返回0表示订阅成功
subscribe_result = xt_trader.subscribe(acc)
print(subscribe_result)
stock_code = '600000.SH'
# 使用指定价下单,接口返回订单编号,后续可以用于撤单操作以及查询委托状态
print("order using the fix price:")
fix_result_order_id = xt_trader.order_stock(acc, stock_code,
xtconstant.STOCK_BUY, 200, xtconstant.FIX_PRICE, 10.5, 'strategy_name',
'remark')
print(fix_result_order_id)
# 使用订单编号撤单
print("cancel order:")
cancel_order_result = xt_trader.cancel_order_stock(acc, fix_result_order_id)
print(cancel_order_result)
# 使用异步下单接口,接口返回下单请求序号seq,seq可以和on_order_stock_async_response
的委托反馈response对应起来
print("order using async api:")
async_seq = xt_trader.order_stock(acc, stock_code, xtconstant.STOCK_BUY,
200, xtconstant.FIX_PRICE, 10.5, 'strategy_name', 'remark')
print(async_seq)
# 查询证券资产
print("query asset:")
asset = xt_trader.query_stock_asset(acc)
if asset:
print("asset:")
print("cash {0}".format(asset.cash))
# 根据订单编号查询委托
print("query order:")
order = xt_trader.query_stock_order(acc, fix_result_order_id)
if order:
print("order:")
print("order {0}".format(order.order_id))
# 查询当日所有的委托
print("query orders:")
orders = xt_trader.query_stock_orders(acc)
print("orders:", len(orders))
if len(orders) != 0:
print("last order:")
print("{0} {1} {2}".format(orders[-1].stock_code,
orders[-1].order_volume, orders[-1].price))
# 查询当日所有的成交
print("query trade:")
trades = xt_trader.query_stock_trades(acc)
print("trades:", len(trades))
if len(trades) != 0:
print("last trade:")
print("{0} {1} {2}".format(trades[-1].stock_code,
trades[-1].traded_volume, trades[-1].traded_price))
# 查询当日所有的持仓
print("query positions:")
positions = xt_trader.query_stock_positions(acc)
print("positions:", len(positions))
if len(positions) != 0:
print("last position:")
print("{0} {1} {2}".format(positions[-1].account_id,
positions[-1].stock_code, positions[-1].volume))
# 根据股票代码查询对应持仓
print("query position:")
position = xt_trader.query_stock_position(acc, stock_code)
if position:
print("position:")
print("{0} {1} {2}".format(position.account_id, position.stock_code,
position.volume))
# 阻塞线程,接收交易推送
xt_trader.run_forever()
开通xtquant的方式可以咨询。
目前开户费率低,门槛低,提供技术支持与交流。
需要的朋友,可以扫码咨询:
备注开户 查看全部
【国盛QMT支持 xtquant qmt mini模式】
mini模式可以在外部运行,同时可以下载历史tick数据。
xtdata是xtquant库中提供行情相关数据的模块,本模块旨在提供精简直接的数据满足量化交易者的数
据需求,作为python库的形式可以被灵活添加到各种策略脚本中。
主要提供行情数据(历史和实时的K线和分笔)、财务数据、合约基础信息、板块和行业分类信息等通
用的行情数据
可以直接获取level2的数据
使用python代码直接运行,不用在qmt软件里面憋屈地写代码,可直接使用pycharm,vscode编写,且有代码提示,补全,好用多了。
附一个完整的策略例子。
保存为: demo.py
命令行下运行:
python demo.py
# 创建策略
#coding=utf-8
from xtquant.xttrader import XtQuantTrader, XtQuantTraderCallback
from xtquant.xtquant import StockAccount
from xtquant import xtconstant
class MyXtQuantTraderCallback(XtQuantTraderCallback):
def on_disconnected(self):
"""
连接断开
:return:
"""
print("connection lost")
def on_stock_order(self, order):
"""
委托回报推送
:param order: XtOrder对象
:return:
"""
print("on order callback:")
print(order.stock_code, order.order_status, order.order_sysid)
def on_stock_asset(self, asset):
"""
资金变动推送
:param asset: XtAsset对象
:return:
"""
print("on asset callback")
print(asset.account_id, asset.cash, asset.total_asset)
def on_stock_trade(self, trade):
"""
成交变动推送
:param trade: XtTrade对象
:return:
"""
print("on trade callback")
print(trade.account_id, trade.stock_code, trade.order_id)
def on_stock_position(self, position):
"""
持仓变动推送
:param position: XtPosition对象
:return:
"""
print("on position callback")
print(position.stock_code, position.volume)
def on_order_error(self, order_error):
"""
委托失败推送
:param order_error:XtOrderError 对象
:return:
"""
print("on order_error callback")
print(order_error.order_id, order_error.error_id, order_error.error_msg)
def on_cancel_error(self, cancel_error):
"""
撤单失败推送
:param cancel_error: XtCancelError 对象
:return:
"""
print("on cancel_error callback")
print(cancel_error.order_id, cancel_error.error_id,
cancel_error.error_msg)
def on_order_stock_async_response(self, response):
"""
异步下单回报推送
:param response: XtOrderResponse 对象
:return:
"""
print("on_order_stock_async_response")
print(response.account_id, response.order_id, response.seq)
if __name__ == "__main__":
print("demo test")
# path为mini qmt客户端安装目录下userdata_mini路径
path = 'D:\\迅投极速交易终端 睿智融科版\\userdata_mini'
# session_id为会话编号,策略使用方对于不同的Python策略需要使用不同的会话编号
session_id = 123456
xt_trader = XtQuantTrader(path, session_id)
# 创建资金账号为1000000365的证券账号对象
acc = StockAccount('1000000365')
# 创建交易回调类对象,并声明接收回调
callback = MyXtQuantTraderCallback()
xt_trader.register_callback(callback)
# 启动交易线程
xt_trader.start()
# 建立交易连接,返回0表示连接成功
connect_result = xt_trader.connect()
print(connect_result)
# 对交易回调进行订阅,订阅后可以收到交易主推,返回0表示订阅成功
subscribe_result = xt_trader.subscribe(acc)
print(subscribe_result)
stock_code = '600000.SH'
# 使用指定价下单,接口返回订单编号,后续可以用于撤单操作以及查询委托状态
print("order using the fix price:")
fix_result_order_id = xt_trader.order_stock(acc, stock_code,
xtconstant.STOCK_BUY, 200, xtconstant.FIX_PRICE, 10.5, 'strategy_name',
'remark')
print(fix_result_order_id)
# 使用订单编号撤单
print("cancel order:")
cancel_order_result = xt_trader.cancel_order_stock(acc, fix_result_order_id)
print(cancel_order_result)
# 使用异步下单接口,接口返回下单请求序号seq,seq可以和on_order_stock_async_response
的委托反馈response对应起来
print("order using async api:")
async_seq = xt_trader.order_stock(acc, stock_code, xtconstant.STOCK_BUY,
200, xtconstant.FIX_PRICE, 10.5, 'strategy_name', 'remark')
print(async_seq)
# 查询证券资产
print("query asset:")
asset = xt_trader.query_stock_asset(acc)
if asset:
print("asset:")
print("cash {0}".format(asset.cash))
# 根据订单编号查询委托
print("query order:")
order = xt_trader.query_stock_order(acc, fix_result_order_id)
if order:
print("order:")
print("order {0}".format(order.order_id))
# 查询当日所有的委托
print("query orders:")
orders = xt_trader.query_stock_orders(acc)
print("orders:", len(orders))
if len(orders) != 0:
print("last order:")
print("{0} {1} {2}".format(orders[-1].stock_code,
orders[-1].order_volume, orders[-1].price))
# 查询当日所有的成交
print("query trade:")
trades = xt_trader.query_stock_trades(acc)
print("trades:", len(trades))
if len(trades) != 0:
print("last trade:")
print("{0} {1} {2}".format(trades[-1].stock_code,
trades[-1].traded_volume, trades[-1].traded_price))
# 查询当日所有的持仓
print("query positions:")
positions = xt_trader.query_stock_positions(acc)
print("positions:", len(positions))
if len(positions) != 0:
print("last position:")
print("{0} {1} {2}".format(positions[-1].account_id,
positions[-1].stock_code, positions[-1].volume))
# 根据股票代码查询对应持仓
print("query position:")
position = xt_trader.query_stock_position(acc, stock_code)
if position:
print("position:")
print("{0} {1} {2}".format(position.account_id, position.stock_code,
position.volume))
# 阻塞线程,接收交易推送
xt_trader.run_forever()
开通xtquant的方式可以咨询。
目前开户费率低,门槛低,提供技术支持与交流。
需要的朋友,可以扫码咨询:
备注开户
ptrade每天自动打新 (新股和可转债)附python代码
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 5710 次浏览 • 2022-07-28 11:10
def initialize(context):
g.flag = False
log.info("initialize g.flag=" + str(g.flag) )
def before_trading_start(context, data):
g.flag = False
log.info("before_trading_start g.flag=" + str(g.flag) )
def handle_data(context, data):
if not g.flag and time.strftime("%H:%M:%S", time.localtime()) > '09:35:00':
# 自动打新
log.info("自动打新")
ipo_stocks_order()
g.flag = True
def on_order_response(context, order_list):
# 该函数会在委托回报返回时响应
log.info(order_list)
交易页面
程序运行返回代码:
点击查看大图
【如果没有打新额度或者没有开通对应的权限,会显示可收购为0】
底下的成功的是可转债申购成功。
然后可以到券商app上看看是否已经有自动申购成功的记录。 查看全部
import time
def initialize(context):
g.flag = False
log.info("initialize g.flag=" + str(g.flag) )
def before_trading_start(context, data):
g.flag = False
log.info("before_trading_start g.flag=" + str(g.flag) )
def handle_data(context, data):
if not g.flag and time.strftime("%H:%M:%S", time.localtime()) > '09:35:00':
# 自动打新
log.info("自动打新")
ipo_stocks_order()
g.flag = True
def on_order_response(context, order_list):
# 该函数会在委托回报返回时响应
log.info(order_list)
交易页面
程序运行返回代码:
【如果没有打新额度或者没有开通对应的权限,会显示可收购为0】
底下的成功的是可转债申购成功。
然后可以到券商app上看看是否已经有自动申购成功的记录。
优矿接口的日期定义真让人蛋疼
股票 • 李魔佛 发表了文章 • 0 个评论 • 2872 次浏览 • 2021-07-17 20:24
然后接口查询结果返回的是YYYY-MM-DD
难道统一一下这么难吗?
然后接口查询结果返回的是YYYY-MM-DD
难道统一一下这么难吗?
优矿数据导出
股票 • 李魔佛 发表了文章 • 0 个评论 • 7862 次浏览 • 2020-12-04 09:11
比如有一个所有股票的dataframe ->df
df.to_csv('all_stock.csv')
然后到左边的数据栏里面,可以在里面看到自己刚刚导出的数据,然后可以选择你刚刚导出的文件,有个选项可以下载,一天可以下载100MB的文件。 查看全部
比如有一个所有股票的dataframe ->df
df.to_csv('all_stock.csv')
然后到左边的数据栏里面,可以在里面看到自己刚刚导出的数据,然后可以选择你刚刚导出的文件,有个选项可以下载,一天可以下载100MB的文件。
基于文本及符号密度的网页正文提取方法 python实现
python • 李魔佛 发表了文章 • 0 个评论 • 6048 次浏览 • 2019-09-10 15:19
项目路径https://github.com/Rockyzsu/CodePool/tree/master/GeneralNewsExtractor
完成后在本文详细介绍,
请密切关注。 查看全部
项目路径https://github.com/Rockyzsu/CodePool/tree/master/GeneralNewsExtractor
完成后在本文详细介绍,
请密切关注。
根据东财股吧爬虫数据进行自然语言分析,展示股市热度
股票 • 李魔佛 发表了文章 • 0 个评论 • 7135 次浏览 • 2019-09-10 09:27
项目开展中.....
https://github.com/Rockyzsu/StockPredict
完工后会把代码搬上来并加注释。
### 2019-11-17 更新 ######
股市舆情情感分类可视化系统
此Web基于Django+Bootstrap+Echarts等框架,个股交易行情数据调用了Tushare接口。对于舆情文本数据采取先爬取东方财富网股吧论坛标题词语设置机器学习训练集,在此基础上运用scikit-learn机器学习朴素贝叶斯方法构建文本分类器。通过Django Web框架,将所得数据传递到前端经过Bootstrap渲染过的html,对数据使用Echarts进行图表可视化处理
不足之处或交流学习欢迎通过邮箱联系我
目前的功能:
个股历史交易行情
个股相关词云展示
情感字典舆情预测
朴素贝叶斯舆情预测
Quick Start
在项目当前目录下: $ python manage.py runserver
浏览器打开127.0.0.1:8000
查看全部
项目开展中.....
https://github.com/Rockyzsu/StockPredict
完工后会把代码搬上来并加注释。
### 2019-11-17 更新 ######
股市舆情情感分类可视化系统
此Web基于Django+Bootstrap+Echarts等框架,个股交易行情数据调用了Tushare接口。对于舆情文本数据采取先爬取东方财富网股吧论坛标题词语设置机器学习训练集,在此基础上运用scikit-learn机器学习朴素贝叶斯方法构建文本分类器。通过Django Web框架,将所得数据传递到前端经过Bootstrap渲染过的html,对数据使用Echarts进行图表可视化处理
不足之处或交流学习欢迎通过邮箱联系我
目前的功能:
个股历史交易行情
个股相关词云展示
情感字典舆情预测
朴素贝叶斯舆情预测
Quick Start
在项目当前目录下: $ python manage.py runserver
浏览器打开127.0.0.1:8000
python分析目前为止科创板企业省份分布
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 6334 次浏览 • 2019-08-26 00:45
首先获取行情数据,借助tushare这个框架:
在python3环境下,pip install tushare --upgrade ,记得要更新,因为用的旧版本会获取不到科创板的数据。
安装成功后试试import tushare as ts,看看有没有报错。没有就是安装成功了。
接下来抓取全市场的行情.
(点击查看大图)
查看前5条数据
现在行情数据存储在df中,然后分析数据。
因为提取的是全市场的数据,然后获取科创板的企业:
(点击查看大图)
使用的是正则表达式,匹配688开头的代码。
接下来就是分析企业归属地:
(点击查看大图)
使用value_counts函数,统计该列每个值出现的次数。
搞定了! 是不是很简单?
而且企业地区分布和自己的构想也差不多,江浙沪一带占了一半,加上北京地区,占了80%以上的科创板企业了。
每周会定期更新一篇python数据分析股票的文章。
原创文章,欢迎转载
请注明出处:
http://30daydo.com/article/528
查看全部
首先获取行情数据,借助tushare这个框架:
在python3环境下,pip install tushare --upgrade ,记得要更新,因为用的旧版本会获取不到科创板的数据。
安装成功后试试import tushare as ts,看看有没有报错。没有就是安装成功了。
接下来抓取全市场的行情.
查看前5条数据
现在行情数据存储在df中,然后分析数据。
因为提取的是全市场的数据,然后获取科创板的企业:
使用的是正则表达式,匹配688开头的代码。
接下来就是分析企业归属地:
使用value_counts函数,统计该列每个值出现的次数。
搞定了! 是不是很简单?
而且企业地区分布和自己的构想也差不多,江浙沪一带占了一半,加上北京地区,占了80%以上的科创板企业了。
每周会定期更新一篇python数据分析股票的文章。
原创文章,欢迎转载
请注明出处:
http://30daydo.com/article/528
截止今天(2019-05-14)银行股今年的涨幅排名
股票 • 李魔佛 发表了文章 • 0 个评论 • 6669 次浏览 • 2019-05-14 23:59
31 601288 农业银行 中国农业银行股份有限公司 -0.341178
11 600015 华夏银行 华夏银行股份有限公司 1.856174
45 601988 中国银行 中国银行股份有限公司 2.248533
32 601328 交通银行 交通银行股份有限公司 3.532657
30 601229 上海银行 上海银行股份有限公司 3.725781
35 601398 工商银行 中国工商银行股份有限公司 4.771403
40 601818 光大银行 中国光大银行股份有限公司 5.643119
27 601169 北京银行 北京银行股份有限公司 6.205580
14 600016 民生银行 中国民生银行股份有限公司 7.092815
5 002936 郑州银行 郑州银行股份有限公司 7.551112
49 601998 中信银行 中信银行股份有限公司 8.181956
43 601939 建设银行 中国建设银行股份有限公司 9.402651
41 601838 成都银行 成都银行股份有限公司 9.424554
52 603323 苏农银行 江苏苏州农村商业银行股份有限公司 12.375732
20 600926 杭州银行 杭州银行股份有限公司 12.933645
8 600000 浦发银行 上海浦东发展银行股份有限公司 14.752244
39 601577 长沙银行 长沙银行股份有限公司 14.792683
18 600908 无锡银行 无锡农村商业银行股份有限公司 16.181704
3 002807 江阴银行 江苏江阴农村商业银行股份有限公司 19.274586
48 601997 贵阳银行 贵阳银行股份有限公司 20.489563
4 002839 张家港行 江苏张家港农村商业银行股份有限公司 20.599511
25 601166 兴业银行 兴业银行股份有限公司 21.206503
24 601128 常熟银行 江苏常熟农村商业银行股份有限公司 21.571187
19 600919 江苏银行 江苏银行股份有限公司 23.218299
22 601009 南京银行 南京银行股份有限公司 26.297500
16 600036 招商银行 招商银行股份有限公司 27.518708
0 000001 平安银行 平安银行股份有限公司 31.624747
2 002142 宁波银行 宁波银行股份有限公司 31.729062
6 002948 青岛银行 青岛银行股份有限公司 48.602573
7 002958 青农商行 青岛农村商业银行股份有限公司 108.983776
42 601860 紫金银行 江苏紫金农村商业银行股份有限公司 115.147347
21 600928 西安银行 西安银行股份有限公司 128.496683 查看全部
ticker secShortName secFullName y_chgPct
31 601288 农业银行 中国农业银行股份有限公司 -0.341178
11 600015 华夏银行 华夏银行股份有限公司 1.856174
45 601988 中国银行 中国银行股份有限公司 2.248533
32 601328 交通银行 交通银行股份有限公司 3.532657
30 601229 上海银行 上海银行股份有限公司 3.725781
35 601398 工商银行 中国工商银行股份有限公司 4.771403
40 601818 光大银行 中国光大银行股份有限公司 5.643119
27 601169 北京银行 北京银行股份有限公司 6.205580
14 600016 民生银行 中国民生银行股份有限公司 7.092815
5 002936 郑州银行 郑州银行股份有限公司 7.551112
49 601998 中信银行 中信银行股份有限公司 8.181956
43 601939 建设银行 中国建设银行股份有限公司 9.402651
41 601838 成都银行 成都银行股份有限公司 9.424554
52 603323 苏农银行 江苏苏州农村商业银行股份有限公司 12.375732
20 600926 杭州银行 杭州银行股份有限公司 12.933645
8 600000 浦发银行 上海浦东发展银行股份有限公司 14.752244
39 601577 长沙银行 长沙银行股份有限公司 14.792683
18 600908 无锡银行 无锡农村商业银行股份有限公司 16.181704
3 002807 江阴银行 江苏江阴农村商业银行股份有限公司 19.274586
48 601997 贵阳银行 贵阳银行股份有限公司 20.489563
4 002839 张家港行 江苏张家港农村商业银行股份有限公司 20.599511
25 601166 兴业银行 兴业银行股份有限公司 21.206503
24 601128 常熟银行 江苏常熟农村商业银行股份有限公司 21.571187
19 600919 江苏银行 江苏银行股份有限公司 23.218299
22 601009 南京银行 南京银行股份有限公司 26.297500
16 600036 招商银行 招商银行股份有限公司 27.518708
0 000001 平安银行 平安银行股份有限公司 31.624747
2 002142 宁波银行 宁波银行股份有限公司 31.729062
6 002948 青岛银行 青岛银行股份有限公司 48.602573
7 002958 青农商行 青岛农村商业银行股份有限公司 108.983776
42 601860 紫金银行 江苏紫金农村商业银行股份有限公司 115.147347
21 600928 西安银行 西安银行股份有限公司 128.496683
【可转债剩余转股比例数据排序】【2019-05-06】
股票 • 李魔佛 发表了文章 • 0 个评论 • 7387 次浏览 • 2019-05-06 15:28
剩余的比例越少,上市公司下调转股价的欲望就越少。 也就是会任由可转债在那里晾着,不会积极拉正股。
数据定期更新。
原创文章,
转载请注明出处:
http://30daydo.com/article/472
查看全部
剩余的比例越少,上市公司下调转股价的欲望就越少。 也就是会任由可转债在那里晾着,不会积极拉正股。
数据定期更新。
原创文章,
转载请注明出处:
http://30daydo.com/article/472
可转债价格分布堆叠图 绘制 可视化 python+pyecharts
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 13208 次浏览 • 2019-01-30 10:59
即使你有很多数据,可是,你无法直观地看到数据的总体趋势。使用可视化的绘图,可以帮助我们看到数据背后看不到的数据。 比如我已经有每一个可转债的价格,评级。数据如下:
点击查看大图
如果我用下面的图形就可以看出规律:
点击查看大图
横坐标是价格,纵坐标是落在该价格的可转债数量,不同颜色代表不同评级的可转债。
可以看到大部分AA-评级(浅橙色)的可转债价格都在100元以下,而AA(浅蓝色)的可转债价格分布较为平均,从90到110都有。而AA+和AAA的一般都在100以上。
那么如何使用代码实现呢?from setting import get_mysql_conn,get_engine
import pandas as pd
import pymongo
from pyecharts import Geo,Style,Map
engine = get_engine('db_stock',local='local')
# 堆叠图
from pyecharts import Bar
df = pd.read_sql('tb_bond_jisilu',con=engine)
result ={}
for name,grades in df.groupby('评级'):
# print(name,grades[['可转债名称','可转债价格']])
for each in grades['可转债价格']:
result.setdefault(name,)
result[name].append(each)
# 确定价格的范围
value = [str(i) for i in range(85,140)]
ret = [0]*len(value)
ret1 = dict(zip(value,ret))
ret_A_add = ret1.copy()
for item in result['A+']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
ret_A_add[k]+=1
retAA_ = ret1.copy()
for item in result['']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
retAA_[k]+=1
retAA = ret1.copy()
for item in result['AA']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
retAA[k]+=1
retAA_add = ret1.copy()
for item in result['AA+']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
retAA_add[k]+=1
retAAA = ret1.copy()
for item in result['AAA']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
retAAA[k]+=1
bar = Bar('可转债价格分布')
bar.add('A+',value,list(ret_A_add.values()),is_stack=True,yaxis_max=11)
bar.add('',value,list(retAA_.values()),is_stack=True,yaxis_max=11)
bar.add('AA',value,list(retAA.values()),is_stack=True,yaxis_max=11)
bar.add('AA+',value,list(retAA_add.values()),is_stack=True,yaxis_max=11)
bar.add('AAA',value,list(retAAA.values()),is_stack=True,yaxis_max=11)
如果没有安装pyecharts,需要用pip安装即可。
原创文章
转载请注明出处:
http://30daydo.com/article/400
查看全部
即使你有很多数据,可是,你无法直观地看到数据的总体趋势。使用可视化的绘图,可以帮助我们看到数据背后看不到的数据。 比如我已经有每一个可转债的价格,评级。数据如下:
点击查看大图
如果我用下面的图形就可以看出规律:
点击查看大图
横坐标是价格,纵坐标是落在该价格的可转债数量,不同颜色代表不同评级的可转债。
可以看到大部分AA-评级(浅橙色)的可转债价格都在100元以下,而AA(浅蓝色)的可转债价格分布较为平均,从90到110都有。而AA+和AAA的一般都在100以上。
那么如何使用代码实现呢?
from setting import get_mysql_conn,get_engine
import pandas as pd
import pymongo
from pyecharts import Geo,Style,Map
engine = get_engine('db_stock',local='local')
# 堆叠图
from pyecharts import Bar
df = pd.read_sql('tb_bond_jisilu',con=engine)
result ={}
for name,grades in df.groupby('评级'):
# print(name,grades[['可转债名称','可转债价格']])
for each in grades['可转债价格']:
result.setdefault(name,)
result[name].append(each)
# 确定价格的范围
value = [str(i) for i in range(85,140)]
ret = [0]*len(value)
ret1 = dict(zip(value,ret))
ret_A_add = ret1.copy()
for item in result['A+']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
ret_A_add[k]+=1
retAA_ = ret1.copy()
for item in result['']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
retAA_[k]+=1
retAA = ret1.copy()
for item in result['AA']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
retAA[k]+=1
retAA_add = ret1.copy()
for item in result['AA+']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
retAA_add[k]+=1
retAAA = ret1.copy()
for item in result['AAA']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
retAAA[k]+=1
bar = Bar('可转债价格分布')
bar.add('A+',value,list(ret_A_add.values()),is_stack=True,yaxis_max=11)
bar.add('',value,list(retAA_.values()),is_stack=True,yaxis_max=11)
bar.add('AA',value,list(retAA.values()),is_stack=True,yaxis_max=11)
bar.add('AA+',value,list(retAA_add.values()),is_stack=True,yaxis_max=11)
bar.add('AAA',value,list(retAAA.values()),is_stack=True,yaxis_max=11)
如果没有安装pyecharts,需要用pip安装即可。
原创文章
转载请注明出处:
http://30daydo.com/article/400
numpy logspace的用法
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 9046 次浏览 • 2018-10-28 17:54
numpy.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None)[source]
Return numbers spaced evenly on a log scale.
In linear space, the sequence starts at base ** start (base to the power of start) and ends with base ** stop (see endpoint below).
Parameters:
start : float
base ** start is the starting value of the sequence.
stop : float
base ** stop is the final value of the sequence, unless endpoint is False. In that case, num + 1 values are spaced over the interval in log-space, of which all but the last (a sequence of length num) are returned.
num : integer, optional
Number of samples to generate. Default is 50.
endpoint : boolean, optional
If true, stop is the last sample. Otherwise, it is not included. Default is True.
base : float, optional
The base of the log space. The step size between the elements in ln(samples) / ln(base) (or log_base(samples)) is uniform. Default is 10.0.
dtype : dtype
The type of the output array. If dtype is not given, infer the data type from the other input arguments.
Returns:
samples : ndarray
num samples, equally spaced on a log scale
上面是官方的文档,英文说的很明白,但网上尤其是csdn的解释,(其实都是你抄我,我抄你),实在让人看的一头雾水
numpy.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None)
比如 np.logspace(0,10,9)
那么会有结果是:
array([1.00000000e+00, 1.77827941e+01, 3.16227766e+02, 5.62341325e+03,
1.00000000e+05, 1.77827941e+06, 3.16227766e+07, 5.62341325e+08,
1.00000000e+10])
第一位是开始值0,第二位是结束值10,然后在这0-10之间产生9个值,这9个值是均匀分布的,默认包括最后一个结束点,就是0到10的9个等产数列,那么根据等差数列的公式,a1+(n-1)*d=an,算出,d=1.25,那么a1=0,接着a2=1.25,a3=2.5,。。。。。a9=10,然后再对这9个值做已10为底的指数运算,也就是10^0, 10^1.25 , 10^2.5 这样的结果 查看全部
numpy.logspace
numpy.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None)[source]
Return numbers spaced evenly on a log scale.
In linear space, the sequence starts at base ** start (base to the power of start) and ends with base ** stop (see endpoint below).
Parameters:
start : float
base ** start is the starting value of the sequence.
stop : float
base ** stop is the final value of the sequence, unless endpoint is False. In that case, num + 1 values are spaced over the interval in log-space, of which all but the last (a sequence of length num) are returned.
num : integer, optional
Number of samples to generate. Default is 50.
endpoint : boolean, optional
If true, stop is the last sample. Otherwise, it is not included. Default is True.
base : float, optional
The base of the log space. The step size between the elements in ln(samples) / ln(base) (or log_base(samples)) is uniform. Default is 10.0.
dtype : dtype
The type of the output array. If dtype is not given, infer the data type from the other input arguments.
Returns:
samples : ndarray
num samples, equally spaced on a log scale
上面是官方的文档,英文说的很明白,但网上尤其是csdn的解释,(其实都是你抄我,我抄你),实在让人看的一头雾水
numpy.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None)
比如 np.logspace(0,10,9)
那么会有结果是:
array([1.00000000e+00, 1.77827941e+01, 3.16227766e+02, 5.62341325e+03,
1.00000000e+05, 1.77827941e+06, 3.16227766e+07, 5.62341325e+08,
1.00000000e+10])
第一位是开始值0,第二位是结束值10,然后在这0-10之间产生9个值,这9个值是均匀分布的,默认包括最后一个结束点,就是0到10的9个等产数列,那么根据等差数列的公式,a1+(n-1)*d=an,算出,d=1.25,那么a1=0,接着a2=1.25,a3=2.5,。。。。。a9=10,然后再对这9个值做已10为底的指数运算,也就是10^0, 10^1.25 , 10^2.5 这样的结果
python数据分析入门 --分析雪球元卫南每个月打赏收入
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 2 个评论 • 10506 次浏览 • 2018-10-24 14:34
最近居然被元神拉黑了。因为帖子不知道被哪位挖坟,估计被元神看到了。
重新跑了下原来的代码,还能跑通,看来雪球并没有改动什么代码。但是雪球经历了一波app下架风波,2019年前的帖子全部无法见到了。
重新获取数据:
点击查看大图
统计数据:
点击查看大图
2019年1月到现在(8月),元神收到的赏金为31851.6,数额比他2019年前所有的金额都要多,虽然总额不高,但是说明了元神这一年影响力大增了。
************************* 写于 2018-11 *******************************
在上一篇 雪球的元卫南靠打赏收割了多少钱 ? python爬虫实例 中,统计出来元卫南所有打赏收入为 24128.13 ,这个数字出乎不少人的意料。因为不少人看到元卫南最近收到的打赏都很多,不少都是100,200的。 那么接下来我就顺便带大家学一下,如何用python做数据分析。
数据来源于上一篇文章中获取到的数据。
首先,从数据库mongodb中读取数据
(点击查看大图)
上面显示数据的前10条,确保数据被正常载入。
观察到列 created_at 是打赏的时间, 导入的数据是字符类型,那么对列 created_at 进行换算, 转化为dataframe中的datetime类型。重新定义一列 pub_date 为打赏时间,设为index,因为dataframe可以对时间index做很多丰富的操作。
(点击查看大图)
可以看到转换后的时间精确到小时,分,秒,而我们需要统计的是每个月(或者每周,每季度,每年都可以)的数据,那么我们就需要重新采样, pandas提供了很好的resample函数,可以对数据按照时间频次进行重新采样。
(点击查看大图)
现在可以看到获取到2018年9月的所有打赏金额的数据。
那么现在就对所有数据进行重采样,并打赏金额进行求和
(点击查看大图)
现在可以看到,每个月得到的打赏金额的总和都可以看到了。从2016年7月到现在2018年10月,最多的月份是这个月,共1.4万,占了所有金额的60%多,所以才让大家造成一个错觉,元兄靠打赏赚了不少粉丝的打赏钱,其实只是最近才多起来的。
还可以绘制条形图。
(点击查看大图)
不过因为月份金额差距过大,导致部分月份的条形显示很短。
不过对于赏金的分布也一目了然了吧。
原创文章
转载请注明出处:
http://30daydo.com/article/362
个人公众号: 查看全部
最近居然被元神拉黑了。因为帖子不知道被哪位挖坟,估计被元神看到了。
重新跑了下原来的代码,还能跑通,看来雪球并没有改动什么代码。但是雪球经历了一波app下架风波,2019年前的帖子全部无法见到了。
重新获取数据:
点击查看大图
统计数据:
点击查看大图
2019年1月到现在(8月),元神收到的赏金为31851.6,数额比他2019年前所有的金额都要多,虽然总额不高,但是说明了元神这一年影响力大增了。
************************* 写于 2018-11 *******************************
在上一篇 雪球的元卫南靠打赏收割了多少钱 ? python爬虫实例 中,统计出来元卫南所有打赏收入为 24128.13 ,这个数字出乎不少人的意料。因为不少人看到元卫南最近收到的打赏都很多,不少都是100,200的。 那么接下来我就顺便带大家学一下,如何用python做数据分析。
数据来源于上一篇文章中获取到的数据。
首先,从数据库mongodb中读取数据
(点击查看大图)
上面显示数据的前10条,确保数据被正常载入。
观察到列 created_at 是打赏的时间, 导入的数据是字符类型,那么对列 created_at 进行换算, 转化为dataframe中的datetime类型。重新定义一列 pub_date 为打赏时间,设为index,因为dataframe可以对时间index做很多丰富的操作。
(点击查看大图)
可以看到转换后的时间精确到小时,分,秒,而我们需要统计的是每个月(或者每周,每季度,每年都可以)的数据,那么我们就需要重新采样, pandas提供了很好的resample函数,可以对数据按照时间频次进行重新采样。
(点击查看大图)
现在可以看到获取到2018年9月的所有打赏金额的数据。
那么现在就对所有数据进行重采样,并打赏金额进行求和
(点击查看大图)
现在可以看到,每个月得到的打赏金额的总和都可以看到了。从2016年7月到现在2018年10月,最多的月份是这个月,共1.4万,占了所有金额的60%多,所以才让大家造成一个错觉,元兄靠打赏赚了不少粉丝的打赏钱,其实只是最近才多起来的。
还可以绘制条形图。
(点击查看大图)
不过因为月份金额差距过大,导致部分月份的条形显示很短。
不过对于赏金的分布也一目了然了吧。
原创文章
转载请注明出处:
http://30daydo.com/article/362
个人公众号:
雪球的元卫南靠打赏收割了多少钱 ? python爬虫实例
python爬虫 • 李魔佛 发表了文章 • 7 个评论 • 33682 次浏览 • 2018-10-23 18:37
今天重新爬了一下,元卫南今年的人气暴涨,在2019年开始到现在,已经获取了31851.6元的打赏金额,虽然金额也不是特别高,但是已经比他2019年前所有打赏金额之和还要高了。 具体分析过程见 http://30daydo.com/article/362
********* 2019-08-05 更新 ***********
文章是去年写的,没想到最近居然在雪球火了。 后续会更新下最新的数据,还有趴一趴释老毛的打赏金额。
雪球的元卫南每天坚持发帖,把一个股民的日常描述的栩栩如生,让人感叹股民的无助与悲哀。 同时也看到上了严重杠杆后,对生活造成的压力,靠着借债来给股票续命。
元卫南雪球链接:https://xueqiu.com/u/2227798650
而且不断有人质疑元卫南写文章,靠打赏金来消费粉丝。 刚开始我也这么觉得,毕竟不少人几十块,一百块的打赏,十几万的粉丝,那每天的收入都很客观呀。 于是抱着好奇心,把元卫南的所有专栏的文章都爬下来,获取每个文章的赏金金额,然后就知道元兄到底靠赏金拿了多少钱。
撸起袖子干。 代码不多,在python3的环境下运行,隐去了header的个人信息,如果在电脑上运行,把你个人的header和cookie加上即可# -*-coding=utf-8-*-
# @Time : 2018/10/23 9:26
# @File : money_reward.py
import requests
from collections import OrderedDict
import time
import datetime
import pymongo
import config
session = requests.Session()
def get_proxy(retry=10):
proxyurl = 'http://{}:8081/dynamicIp/common/getDynamicIp.do'.format(config.PROXY)
count = 0
for i in range(retry):
try:
r = requests.get(proxyurl, timeout=10)
except Exception as e:
print(e)
count += 1
print('代理获取失败,重试' + str(count))
time.sleep(1)
else:
js = r.json()
proxyServer = 'http://{0}:{1}'.format(js.get('ip'), js.get('port'))
proxies_random = {
'http': proxyServer
}
return proxies_random
def get_content(url):
headers = {
# 此处添加个人的header信息
}
try:
proxy = get_proxy()
except Exception as e:
print(e)
proxy = get_proxy()
try:
r = session.get(url=url, headers=headers,proxies=proxy,timeout=10)
except Exception as e:
print(e)
proxy = get_proxy()
r = session.get(url=url, headers=headers,proxies=proxy,timeout=10)
return r
def parse_content(post_id):
url = 'https://xueqiu.com/statuses/reward/list_by_user.json?status_id={}&page=1&size=99999999'.format(post_id)
r = get_content(url)
print(r.text)
if r.status_code != 200:
print('status code != 200')
failed_doc.insert({'post_id':post_id,'status':0})
return None
try:
js_data = r.json()
except Exception as e:
print(e)
print('can not parse to json')
print(post_id)
failed_doc.insert({'post_id': post_id, 'status': 0})
return
ret =
been_reward_user = '元卫南'
for item in js_data.get('items'):
name = item.get('name')
amount = item.get('amount')
description = item.get('description')
user_id = item.get('user_id')
created_at = item.get('created_at')
if created_at:
created_at = datetime.datetime.fromtimestamp(int(created_at) / 1000).strftime('%Y-%m-%d %H:%M:%S')
d = OrderedDict()
d['name'] = name
d['user_id'] = user_id
d['amount'] = amount / 100
d['description'] = description
d['created_at'] = created_at
d['been_reward'] = been_reward_user
ret.append(d)
print(ret)
if ret:
doc.insert_many(ret)
failed_doc.insert({'post_id':post_id,'status':1})
def get_all_page_id(user_id):
doc = db['db_parker']['xueqiu_zhuanglan']
get_page_url = 'https://xueqiu.com/statuses/original/timeline.json?user_id={}&page=1'.format(user_id)
r = get_content(get_page_url)
max_page = int(r.json().get('maxPage'))
for i in range(1, max_page + 1):
url = 'https://xueqiu.com/statuses/original/timeline.json?user_id=2227798650&page={}'.format(i)
r = get_content(url)
js_data = r.json()
ret =
for item in js_data.get('list'):
d = OrderedDict()
d['article_id'] = item.get('id')
d['title'] = item.get('title')
d['description'] = item.get('description')
d['view_count'] = item.get('view_count')
d['target'] = 'https://xueqiu.com/' + item.get('target')
d['user_id']= item.get('user_id')
d['created_at'] = datetime.datetime.fromtimestamp(int(item.get('created_at')) / 1000).strftime(
'%Y-%m-%d %H:%M:%S')
ret.append(d)
print(d)
doc.insert_many(ret)
def loop_page_id():
doc = db['db_parker']['xueqiu_zhuanglan']
ret = doc.find({},{'article_id':1})
failed_doc = db['db_parker']['xueqiu_reward_status']
failed_ret = failed_doc.find({'status':1})
article_id_list =
for i in failed_ret:
article_id_list.append(i.get('article_id'))
for item in ret:
article_id = item.get('article_id')
print(article_id)
if article_id in article_id_list:
continue
else:
parse_content(article_id)
loop_page_id()
然后就是开始爬。
因为使用了代理,所有速度回有点慢,大概10分钟就把所有内容爬完了。
点击查看大图
数据是存储在mongodb数据库中,打开mongodb,可以查看每一条数据,还可以做统计。
点击查看大图
从今天(2018-10-23)追溯到元兄第一篇专栏文章(2014-2-17),元兄总共发了1144篇文章。
点击查看大图
然后再看另外一个打赏的列表
点击查看大图
从最新的开始日期(2018-10-23),这位 金王山而 的用户似乎打赏的很多次,看了是元兄的忠实粉丝。
统计了下,元神共有4222次打赏。
点击查看大图
打赏总金额为:
24128.13
点击查看大图
好吧,太出乎意料了!!! 还以为会有几百万的打赏金额呀,最后算出来才只有24128,这点钱,元兄只够补仓5手东阿阿胶呀。
然后按照打赏金额排序:
点击查看大图
打赏最高金额的是唐史主任,金额为250元,200元的有十来个, 还看到之前梁大师打赏的200元,可以排在并列前10了。
其实大部分人都是拿小钱来打赏下,2元以下就有2621,占了50%了。
还是很支持元神每天坚持发帖,在当前的行情下或可以聊以慰藉,或娱乐大家,或引以为戒,让大家看到股市对散户生活造成的影响,避免重蹈覆辙。
原创文章
转载请注明出处:
http://30daydo.com/article/361
个人公众号:
下篇:
python数据分析入门 分析雪球元卫南每个月打赏收入 查看全部
今天重新爬了一下,元卫南今年的人气暴涨,在2019年开始到现在,已经获取了31851.6元的打赏金额,虽然金额也不是特别高,但是已经比他2019年前所有打赏金额之和还要高了。 具体分析过程见 http://30daydo.com/article/362
********* 2019-08-05 更新 ***********
文章是去年写的,没想到最近居然在雪球火了。 后续会更新下最新的数据,还有趴一趴释老毛的打赏金额。
雪球的元卫南每天坚持发帖,把一个股民的日常描述的栩栩如生,让人感叹股民的无助与悲哀。 同时也看到上了严重杠杆后,对生活造成的压力,靠着借债来给股票续命。
元卫南雪球链接:https://xueqiu.com/u/2227798650
而且不断有人质疑元卫南写文章,靠打赏金来消费粉丝。 刚开始我也这么觉得,毕竟不少人几十块,一百块的打赏,十几万的粉丝,那每天的收入都很客观呀。 于是抱着好奇心,把元卫南的所有专栏的文章都爬下来,获取每个文章的赏金金额,然后就知道元兄到底靠赏金拿了多少钱。
撸起袖子干。 代码不多,在python3的环境下运行,隐去了header的个人信息,如果在电脑上运行,把你个人的header和cookie加上即可
# -*-coding=utf-8-*-
# @Time : 2018/10/23 9:26
# @File : money_reward.py
import requests
from collections import OrderedDict
import time
import datetime
import pymongo
import config
session = requests.Session()
def get_proxy(retry=10):
proxyurl = 'http://{}:8081/dynamicIp/common/getDynamicIp.do'.format(config.PROXY)
count = 0
for i in range(retry):
try:
r = requests.get(proxyurl, timeout=10)
except Exception as e:
print(e)
count += 1
print('代理获取失败,重试' + str(count))
time.sleep(1)
else:
js = r.json()
proxyServer = 'http://{0}:{1}'.format(js.get('ip'), js.get('port'))
proxies_random = {
'http': proxyServer
}
return proxies_random
def get_content(url):
headers = {
# 此处添加个人的header信息
}
try:
proxy = get_proxy()
except Exception as e:
print(e)
proxy = get_proxy()
try:
r = session.get(url=url, headers=headers,proxies=proxy,timeout=10)
except Exception as e:
print(e)
proxy = get_proxy()
r = session.get(url=url, headers=headers,proxies=proxy,timeout=10)
return r
def parse_content(post_id):
url = 'https://xueqiu.com/statuses/reward/list_by_user.json?status_id={}&page=1&size=99999999'.format(post_id)
r = get_content(url)
print(r.text)
if r.status_code != 200:
print('status code != 200')
failed_doc.insert({'post_id':post_id,'status':0})
return None
try:
js_data = r.json()
except Exception as e:
print(e)
print('can not parse to json')
print(post_id)
failed_doc.insert({'post_id': post_id, 'status': 0})
return
ret =
been_reward_user = '元卫南'
for item in js_data.get('items'):
name = item.get('name')
amount = item.get('amount')
description = item.get('description')
user_id = item.get('user_id')
created_at = item.get('created_at')
if created_at:
created_at = datetime.datetime.fromtimestamp(int(created_at) / 1000).strftime('%Y-%m-%d %H:%M:%S')
d = OrderedDict()
d['name'] = name
d['user_id'] = user_id
d['amount'] = amount / 100
d['description'] = description
d['created_at'] = created_at
d['been_reward'] = been_reward_user
ret.append(d)
print(ret)
if ret:
doc.insert_many(ret)
failed_doc.insert({'post_id':post_id,'status':1})
def get_all_page_id(user_id):
doc = db['db_parker']['xueqiu_zhuanglan']
get_page_url = 'https://xueqiu.com/statuses/original/timeline.json?user_id={}&page=1'.format(user_id)
r = get_content(get_page_url)
max_page = int(r.json().get('maxPage'))
for i in range(1, max_page + 1):
url = 'https://xueqiu.com/statuses/original/timeline.json?user_id=2227798650&page={}'.format(i)
r = get_content(url)
js_data = r.json()
ret =
for item in js_data.get('list'):
d = OrderedDict()
d['article_id'] = item.get('id')
d['title'] = item.get('title')
d['description'] = item.get('description')
d['view_count'] = item.get('view_count')
d['target'] = 'https://xueqiu.com/' + item.get('target')
d['user_id']= item.get('user_id')
d['created_at'] = datetime.datetime.fromtimestamp(int(item.get('created_at')) / 1000).strftime(
'%Y-%m-%d %H:%M:%S')
ret.append(d)
print(d)
doc.insert_many(ret)
def loop_page_id():
doc = db['db_parker']['xueqiu_zhuanglan']
ret = doc.find({},{'article_id':1})
failed_doc = db['db_parker']['xueqiu_reward_status']
failed_ret = failed_doc.find({'status':1})
article_id_list =
for i in failed_ret:
article_id_list.append(i.get('article_id'))
for item in ret:
article_id = item.get('article_id')
print(article_id)
if article_id in article_id_list:
continue
else:
parse_content(article_id)
loop_page_id()
然后就是开始爬。
因为使用了代理,所有速度回有点慢,大概10分钟就把所有内容爬完了。
数据是存储在mongodb数据库中,打开mongodb,可以查看每一条数据,还可以做统计。
从今天(2018-10-23)追溯到元兄第一篇专栏文章(2014-2-17),元兄总共发了1144篇文章。
然后再看另外一个打赏的列表
从最新的开始日期(2018-10-23),这位 金王山而 的用户似乎打赏的很多次,看了是元兄的忠实粉丝。
统计了下,元神共有4222次打赏。
打赏总金额为:
24128.13
好吧,太出乎意料了!!! 还以为会有几百万的打赏金额呀,最后算出来才只有24128,这点钱,元兄只够补仓5手东阿阿胶呀。
然后按照打赏金额排序:
打赏最高金额的是唐史主任,金额为250元,200元的有十来个, 还看到之前梁大师打赏的200元,可以排在并列前10了。
其实大部分人都是拿小钱来打赏下,2元以下就有2621,占了50%了。
还是很支持元神每天坚持发帖,在当前的行情下或可以聊以慰藉,或娱乐大家,或引以为戒,让大家看到股市对散户生活造成的影响,避免重蹈覆辙。
原创文章
转载请注明出处:
http://30daydo.com/article/361
个人公众号:
下篇:
python数据分析入门 分析雪球元卫南每个月打赏收入
python量化分析: 股票涨停后该不该卖, 怕砸板还是怕卖飞 ?
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 1 个评论 • 9890 次浏览 • 2018-06-14 19:34
那么触及涨停板的个股我们应该继续持有,还是卖掉,还是卖掉做T接回来呢?
接下来用数据说话。【数据使用通联实验室的数据源】
首先获取当前市场上所有股票all_stocks = DataAPI.SecTypeRegionRelGet(secID=u"",ticker=u"",typeID=u"",field=u"",pandas="1")
然后获取每一个股票的日k线数据,可以设定一个时间段,我抓取了2012年到今天(2018-06-14)的所有数据,如果是次新股,那么数据就是上市当天到今天的数据。
抓取到的数据包含以下的字段:
点击查看大图
但是实际用到的字段只有几个, 开盘价,最高价,涨幅,昨天收盘价。
这里我排除了一字板开盘的个股,因为里面含有新股,会导致数据不精确,【后续我会统计,一字板开盘盘中被砸开的概率】,而且数据也排除了ST的个股,因为本人从来不买ST股,所以不会对ST进行统计。fbl =
for code in all_stocks['secID']:
df = DataAPI.MktEqudGet(secID=code,ticker=u"",tradeDate=u"",beginDate=u"20120101",endDate=u"",isOpen="",field=u"",pandas="1")
df['ztj']=map(lambda x:round(x,2),df['preClosePrice']*1.1)
df['chgPct']=df['chgPct']*100
# 非一字板
zt = df[(df['ztj']==df['highestPrice']) & (df['openPrice']!=df['highestPrice'])]
fz= df[(df['ztj']==df['highestPrice']) & (df['openPrice']!=df['highestPrice'])&(df['closePrice']==df['highestPrice'])]
try:
f = len(fz)*1.00/len(zt)*100
fbl.append((code,f))
except Exception,e:
print e
print code
fbl就是封板率的一个列表,包含了每只股票的触及涨停价后封板的概率。 然后对整体的数据取平均值:dx= dict(fbl)
x = np.array(dx.values())
print x.mean()
最后得到的结果是:
64.0866513726
所以保持住涨停的概率还是大一些。所以站在概率大的一边上,触及涨停的时候应该继续持有,会有62.5%会到收盘保持涨停价。
(待续)
原创文章,转载请注明出处:
http://30daydo.com/article/331
查看全部
那么触及涨停板的个股我们应该继续持有,还是卖掉,还是卖掉做T接回来呢?
接下来用数据说话。【数据使用通联实验室的数据源】
首先获取当前市场上所有股票
all_stocks = DataAPI.SecTypeRegionRelGet(secID=u"",ticker=u"",typeID=u"",field=u"",pandas="1")
然后获取每一个股票的日k线数据,可以设定一个时间段,我抓取了2012年到今天(2018-06-14)的所有数据,如果是次新股,那么数据就是上市当天到今天的数据。
抓取到的数据包含以下的字段:
点击查看大图
但是实际用到的字段只有几个, 开盘价,最高价,涨幅,昨天收盘价。
这里我排除了一字板开盘的个股,因为里面含有新股,会导致数据不精确,【后续我会统计,一字板开盘盘中被砸开的概率】,而且数据也排除了ST的个股,因为本人从来不买ST股,所以不会对ST进行统计。
fbl =
for code in all_stocks['secID']:
df = DataAPI.MktEqudGet(secID=code,ticker=u"",tradeDate=u"",beginDate=u"20120101",endDate=u"",isOpen="",field=u"",pandas="1")
df['ztj']=map(lambda x:round(x,2),df['preClosePrice']*1.1)
df['chgPct']=df['chgPct']*100
# 非一字板
zt = df[(df['ztj']==df['highestPrice']) & (df['openPrice']!=df['highestPrice'])]
fz= df[(df['ztj']==df['highestPrice']) & (df['openPrice']!=df['highestPrice'])&(df['closePrice']==df['highestPrice'])]
try:
f = len(fz)*1.00/len(zt)*100
fbl.append((code,f))
except Exception,e:
print e
print code
fbl就是封板率的一个列表,包含了每只股票的触及涨停价后封板的概率。 然后对整体的数据取平均值:
dx= dict(fbl)
x = np.array(dx.values())
print x.mean()
最后得到的结果是:
64.0866513726
所以保持住涨停的概率还是大一些。所以站在概率大的一边上,触及涨停的时候应该继续持有,会有62.5%会到收盘保持涨停价。
(待续)
原创文章,转载请注明出处:
http://30daydo.com/article/331
python获取每天的涨停个股数据 和昨天涨停的今天表现
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 14 个评论 • 14853 次浏览 • 2018-06-02 10:47
(点击查看大图)
今日的涨停信息
(点击查看大图)
昨日涨停的今天信息
还有自动生成的K线图:
(点击查看大图)
有兴趣的朋友可以留言获取上述数据
原创文章
转载请注明出处:http://30daydo.com/article/316 查看全部
今日的涨停信息
昨日涨停的今天信息
还有自动生成的K线图:
有兴趣的朋友可以留言获取上述数据
原创文章
转载请注明出处:http://30daydo.com/article/316
正常退出tushare
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 1 个评论 • 5760 次浏览 • 2018-05-07 21:31
查看源码知道ts.get_api() 里面使用了多线程,程序一直在循环等待。 如果按ctrl + c,是无法正常终止tushare在后台的调用,需要使用ts.close_api(conn), 才能终止掉后台的多线程,这个时候程序才能正常退出,释放系统资源。
原创文章
转载请注明出处:http://30daydo.com/article/308
查看全部
查看源码知道ts.get_api() 里面使用了多线程,程序一直在循环等待。 如果按ctrl + c,是无法正常终止tushare在后台的调用,需要使用ts.close_api(conn), 才能终止掉后台的多线程,这个时候程序才能正常退出,释放系统资源。
原创文章
转载请注明出处:http://30daydo.com/article/308
使用优矿获取股市的基本数据 实例操作
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 1 个评论 • 7233 次浏览 • 2018-05-06 22:44
DataAPI.MktRANKInstTrGet
行业名称,如:传媒,电气设备等,可多值输入,以下为申万28个行业名称:休闲服务,房地产,商业贸易,综合,钢铁,农林牧渔,食品饮料,采掘,电子,国防军工,通信,公用事业,交通运输,轻工制造,计算机,电气设备,家用电器,医药生物,传媒,非银金融,汽车,有色金属,机械设备,建筑材料,化工,纺织服装,银行,建筑装饰,可以是列表,可空
实例
原创文章
转载请注明出处:http://30daydo.com/article/306
查看全部
DataAPI.MktRANKInstTrGet
行业名称,如:传媒,电气设备等,可多值输入,以下为申万28个行业名称:休闲服务,房地产,商业贸易,综合,钢铁,农林牧渔,食品饮料,采掘,电子,国防军工,通信,公用事业,交通运输,轻工制造,计算机,电气设备,家用电器,医药生物,传媒,非银金融,汽车,有色金属,机械设备,建筑材料,化工,纺织服装,银行,建筑装饰,可以是列表,可空
实例
原创文章
转载请注明出处:http://30daydo.com/article/306
原来这样的历史日线数据也可以拿来卖的呀
股票 • 李魔佛 发表了文章 • 3 个评论 • 4867 次浏览 • 2018-04-08 22:58
原来这样的数据都可以拿去卖的。 确切的体验到知识就是金钱哈。
原来这样的数据都可以拿去卖的。 确切的体验到知识就是金钱哈。
pandas中resample的how参数“ohlc”
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 2 个评论 • 18790 次浏览 • 2018-03-25 23:42
比如我获取得到了一个股票从14年到现在的开盘,收盘,最高,最低等价格,然后我想对数据中的收盘价重新采样,转换成月数据。可以使用resample函数,参数中的how配合 ohlc。
获取原始数据:
提取收盘价
重新采样:
重新采样后获得的新数据:
可以看到现在的index是每个月的结束,而多了几列,close,open,high,low,这4列就是根据每个月的close价格而提取出来的,比如统计一月份的时候,一月份的收盘价会有一个最低和最高,最开始open1月1号和结束close的1月31号的价格。
原创文章
转载请注明出处:http://30daydo.com/article/288
查看全部
比如我获取得到了一个股票从14年到现在的开盘,收盘,最高,最低等价格,然后我想对数据中的收盘价重新采样,转换成月数据。可以使用resample函数,参数中的how配合 ohlc。
获取原始数据:
提取收盘价
重新采样:
重新采样后获得的新数据:
可以看到现在的index是每个月的结束,而多了几列,close,open,high,low,这4列就是根据每个月的close价格而提取出来的,比如统计一月份的时候,一月份的收盘价会有一个最低和最高,最开始open1月1号和结束close的1月31号的价格。
原创文章
转载请注明出处:http://30daydo.com/article/288
可转债套利【一】 python找出折价可转债个股
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 9 个评论 • 25938 次浏览 • 2018-03-16 17:17
下面的内容默认你对可转债已经有一定的了解。
可转债的价值=正股价格/转股价格 + 利息,忽略可转债的利息,直接用公式 可转债的价值=正股价格/转股价格 计算可转债的价值。
如果当前可转债的交易价格(在交易软件上显示的价格)如:
所以万信转债的价格是121.5元,然后万信转债的价值呢? 按照上面的公式,万信转债的正股是万达信息,今天万达信息 (2018-03-16)的股价是
以收盘价为例,17.25。
而万信转债的股转价格呢? 这个可以到万信转债F10页面的公告中找到,为13.11元。 所以万信转债的价值是
17.25/13.11 = 1.315 , 可转债单位是100, 所以万信转债的内在价值是1.315*100=131.5, 而当前的交易价格为 121.5
也就是你用121.5元买到一个价值 131.5的商品, 所以相当于打折买到了一个超值的商品,所以当前的万信转债是折价状态。
所以本次任务就是要找出可交易的可转债中折价状态的可转债。
然后直接上干货。上python代码。#-*-coding=utf-8
'''
可转债监控
'''
import tushare as ts
from setting import get_engine
engine = get_engine('db_bond')
import pandas as pd
import datetime
class ConvertBond():
def __init__(self):
self.conn=ts.get_apis()
self.allBonds=ts.new_cbonds(pause=2)
self.onSellBond=self.allBonds.dropna(subset=['marketprice'])
self.today=datetime.datetime.now().strftime('%Y-%m-%d %H:%M')
def stockPrice(self,code):
stock_df = ts.get_realtime_quotes(code)
price = float(stock_df['price'].values[0])
return price
def dataframe(self):
price_list=
for code in self.onSellBond['scode']:
price_list.append(self.stockPrice(code))
self.onSellBond['stock_price']=price_list
self.onSellBond['ratio'] = (
self.onSellBond['marketprice']
/(self.onSellBond['stock_price'] / self.onSellBond['convprice'])-1)*100
self.onSellBond['Updated']=self.today
self.onSellBond.to_sql('tb_bond',engine,if_exists='replace')
def closed(self):
ts.close_apis(self.conn)
def main():
bond=ConvertBond()
bond.dataframe()
bond.closed()
if __name__=='__main__':
main()
上面的setting库,把下面的*** 替换成你自己的Mysql用户和密码即可。import os
import MySQLdb
MYSQL_USER = *********
MYSQL_PASSWORD = ********
MYSQL_HOST = *********
MYSQL_PORT = *****
def get_engine(db):
engine = create_engine('mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8'.format(MYSQL_USER, MYSQL_PASSWORD, MYSQL_HOST, MYSQL_PORT, db))
return engine
上面的少于100行的代码就能够满足你的要求。
运行后会把结果保存在MySQL 数据库。如下图所示:
点击放大
2018-03-16 可转债表格
其中折价率是ratio列。按照ratio列进行排列,只有2个是正,也就是当前市场是只有2只可转债是处于折价状态的,其余的都是溢价状态(价格比内在价值要贵,忽略利息的前提下,如果把4~5%的利息也算进去的话,-3~4%的折价率其实也算小折价吧)
目前万信转债折价10个点,宝信转债折价5.8个点。 所以适合低风险投资者建仓。 因为可转债有兜底价格,所以出现亏损的概率很低(除非遇到黑天鹅,公司破产了,像遇到乐视这种PPT独角兽公司,欠债不还的。 但是A股上能够有资格发行可转债的,本身对公司的盈利,分红都有硬性要求)。
所以可以保存上面的代码,可以每天运行一次,可以很方便地找出折价的个股,当然也可以在盘中一直监测,因为可转债的价格是实时变化的,一旦遇到大跌,跌到折价状态,你也可以择时入手标的。
原文链接:
http://30daydo.com/article/286
转载请注明出处
可转债低费率,沪市百万分之二,深圳十万分之四,免五 开户
加微信开通
查看全部
下面的内容默认你对可转债已经有一定的了解。
可转债的价值=正股价格/转股价格 + 利息,忽略可转债的利息,直接用公式 可转债的价值=正股价格/转股价格 计算可转债的价值。
如果当前可转债的交易价格(在交易软件上显示的价格)如:
所以万信转债的价格是121.5元,然后万信转债的价值呢? 按照上面的公式,万信转债的正股是万达信息,今天万达信息 (2018-03-16)的股价是
以收盘价为例,17.25。
而万信转债的股转价格呢? 这个可以到万信转债F10页面的公告中找到,为13.11元。 所以万信转债的价值是
17.25/13.11 = 1.315 , 可转债单位是100, 所以万信转债的内在价值是1.315*100=131.5, 而当前的交易价格为 121.5
也就是你用121.5元买到一个价值 131.5的商品, 所以相当于打折买到了一个超值的商品,所以当前的万信转债是折价状态。
所以本次任务就是要找出可交易的可转债中折价状态的可转债。
然后直接上干货。上python代码。
#-*-coding=utf-8
'''
可转债监控
'''
import tushare as ts
from setting import get_engine
engine = get_engine('db_bond')
import pandas as pd
import datetime
class ConvertBond():
def __init__(self):
self.conn=ts.get_apis()
self.allBonds=ts.new_cbonds(pause=2)
self.onSellBond=self.allBonds.dropna(subset=['marketprice'])
self.today=datetime.datetime.now().strftime('%Y-%m-%d %H:%M')
def stockPrice(self,code):
stock_df = ts.get_realtime_quotes(code)
price = float(stock_df['price'].values[0])
return price
def dataframe(self):
price_list=
for code in self.onSellBond['scode']:
price_list.append(self.stockPrice(code))
self.onSellBond['stock_price']=price_list
self.onSellBond['ratio'] = (
self.onSellBond['marketprice']
/(self.onSellBond['stock_price'] / self.onSellBond['convprice'])-1)*100
self.onSellBond['Updated']=self.today
self.onSellBond.to_sql('tb_bond',engine,if_exists='replace')
def closed(self):
ts.close_apis(self.conn)
def main():
bond=ConvertBond()
bond.dataframe()
bond.closed()
if __name__=='__main__':
main()
上面的setting库,把下面的*** 替换成你自己的Mysql用户和密码即可。
import os
import MySQLdb
MYSQL_USER = *********
MYSQL_PASSWORD = ********
MYSQL_HOST = *********
MYSQL_PORT = *****
def get_engine(db):
engine = create_engine('mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8'.format(MYSQL_USER, MYSQL_PASSWORD, MYSQL_HOST, MYSQL_PORT, db))
return engine
上面的少于100行的代码就能够满足你的要求。
运行后会把结果保存在MySQL 数据库。如下图所示:
点击放大
2018-03-16 可转债表格
其中折价率是ratio列。按照ratio列进行排列,只有2个是正,也就是当前市场是只有2只可转债是处于折价状态的,其余的都是溢价状态(价格比内在价值要贵,忽略利息的前提下,如果把4~5%的利息也算进去的话,-3~4%的折价率其实也算小折价吧)
目前万信转债折价10个点,宝信转债折价5.8个点。 所以适合低风险投资者建仓。 因为可转债有兜底价格,所以出现亏损的概率很低(除非遇到黑天鹅,公司破产了,像遇到乐视这种PPT独角兽公司,欠债不还的。 但是A股上能够有资格发行可转债的,本身对公司的盈利,分红都有硬性要求)。
所以可以保存上面的代码,可以每天运行一次,可以很方便地找出折价的个股,当然也可以在盘中一直监测,因为可转债的价格是实时变化的,一旦遇到大跌,跌到折价状态,你也可以择时入手标的。
原文链接:
http://30daydo.com/article/286
转载请注明出处
可转债低费率,沪市百万分之二,深圳十万分之四,免五 开户
加微信开通
tushare 调用ts.get_apis() 后一直在运行无法退出
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 6072 次浏览 • 2018-03-16 00:47
conn=ts.get_apis()
......
在你的程序退出前,运行
ts.close_apis(conn)
这样你的程序就能够正常退出。 查看全部
conn=ts.get_apis()
......
在你的程序退出前,运行
ts.close_apis(conn)
这样你的程序就能够正常退出。
python监测股票出现的规律大单
股票 • 李魔佛 发表了文章 • 2 个评论 • 7038 次浏览 • 2018-02-27 12:03
首先获取当日的历史分笔数据
code='300527'
df = ts.get_today_ticks(code)
然后根据成交量进行排序:
df.sort_values(by='volume',ascending=False).head(100)显示前100的成交量。
从上面的表格可以看到,不断有1500手的卖盘,而且卖出价格比正常的药低3个点,所谓的砸盘。
但是每次砸完了价格又会正常的回来原来的地方。 从分时走势上也可以看到一个个凸起的大单成交量。
每次打压完,股价还会正常回到原来的位置。 个人觉得这个是有人在出货,但是不断有人在接货。是不同的两伙人。 查看全部
首先获取当日的历史分笔数据
code='300527'
df = ts.get_today_ticks(code)
然后根据成交量进行排序:
df.sort_values(by='volume',ascending=False).head(100)显示前100的成交量。
从上面的表格可以看到,不断有1500手的卖盘,而且卖出价格比正常的药低3个点,所谓的砸盘。
但是每次砸完了价格又会正常的回来原来的地方。 从分时走势上也可以看到一个个凸起的大单成交量。
每次打压完,股价还会正常回到原来的位置。 个人觉得这个是有人在出货,但是不断有人在接货。是不同的两伙人。
【量化选股】A股上有哪些东北股(排雷)?
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 4931 次浏览 • 2018-01-31 01:09
打开jupyter notebook。然后输入下面的代码:
上面可以获得A股上市公司所有区域的分布。果然刘士余上台后,浙江地区的企业一下子超越广东,成为A股最多公司的省份(当然,这里的广东是把深圳给单独分离出去了),浙江有418个上市公司。
然后根据条件筛选列area,选出辽宁,吉林,黑龙江的企业。
共有152家上市公司。截止2018-01-30日。
列表太长没有显示完整,贴在附件里面供大家参考(排雷)。
原文地址:http://30daydo.com/article/271
转载请注明出处 查看全部
打开jupyter notebook。然后输入下面的代码:
上面可以获得A股上市公司所有区域的分布。果然刘士余上台后,浙江地区的企业一下子超越广东,成为A股最多公司的省份(当然,这里的广东是把深圳给单独分离出去了),浙江有418个上市公司。
然后根据条件筛选列area,选出辽宁,吉林,黑龙江的企业。
共有152家上市公司。截止2018-01-30日。
列表太长没有显示完整,贴在附件里面供大家参考(排雷)。
原文地址:http://30daydo.com/article/271
转载请注明出处
【量化分析】到底谁在买乐视网?2018年1月26日
股票 • 李魔佛 发表了文章 • 2 个评论 • 5341 次浏览 • 2018-01-26 17:02
本来没有持有这一只股票,不过雪球上不时地出现一些文章,根据龙虎榜推测到底谁在接盘。 于是今天收盘,打开jupyter notebook来简单地分析一下。 大家也可以跟着学习一些分析的思路。因为今天的龙虎榜还没出来,等待会龙虎榜出来了可以再比较一下。
首先导入今天的分时数据
volume列就是我们感兴趣的成交量。单位是手(100股)
先计算一下今天的总成交量:
1021800股,额,比不少中小创的小股的成交量还大呢,瘦死的骆驼比马大。
去对比一下雪球或者东财的数据,看看数据是否准确。
嗯,1.02万手,数据一致。
接着我们来看看排序,按照成交量的大小排序,可以看到最大和最小的差别:
大单都集中在开盘和收盘阶段(其实开盘和收盘严格来说不算大单,因为同一时刻太多人一起买,所以掺杂在一起,如果把收盘和开盘的数据拿掉,其实真的没多少大单。。。)
然后剩下的都是些零零散散的1手的成交:
可以统计一下每个单数出现的频率:
出现最多的是1手,2手。这个很正常,如果出现较多的是超过100手的大单,那么也说明跌停很快被打开(后续如果有打算冒风险去撸一把乐视翘班的,可以自己写一个检测程序)
接着做一些统计:
定义大于100手的为大单。
然后计算100手大单占成交的比例:
嗯,有28%的比例呢。
然后计算一下小于10手的占成交比例。
有30%的比例。
再统计一下中位数和各分位数:
中位数是3,说明整个交易中,一半的成交是在等于或小于3手的,而分位数看到,1手的可以排到25%的位置,而8手则排到了75%的位置。
结论:
其实在买的都是小散,不知道是乐粉还是赌徒了。
原文地址:
http://30daydo.com/article/267
源码:https://github.com/Rockyzsu/stock/blob/master/levt_notebook.ipynb
查看全部

本来没有持有这一只股票,不过雪球上不时地出现一些文章,根据龙虎榜推测到底谁在接盘。 于是今天收盘,打开jupyter notebook来简单地分析一下。 大家也可以跟着学习一些分析的思路。因为今天的龙虎榜还没出来,等待会龙虎榜出来了可以再比较一下。
首先导入今天的分时数据

volume列就是我们感兴趣的成交量。单位是手(100股)
先计算一下今天的总成交量:

1021800股,额,比不少中小创的小股的成交量还大呢,瘦死的骆驼比马大。
去对比一下雪球或者东财的数据,看看数据是否准确。

嗯,1.02万手,数据一致。
接着我们来看看排序,按照成交量的大小排序,可以看到最大和最小的差别:

大单都集中在开盘和收盘阶段(其实开盘和收盘严格来说不算大单,因为同一时刻太多人一起买,所以掺杂在一起,如果把收盘和开盘的数据拿掉,其实真的没多少大单。。。)

然后剩下的都是些零零散散的1手的成交:
可以统计一下每个单数出现的频率:

出现最多的是1手,2手。这个很正常,如果出现较多的是超过100手的大单,那么也说明跌停很快被打开(后续如果有打算冒风险去撸一把乐视翘班的,可以自己写一个检测程序)
接着做一些统计:
定义大于100手的为大单。
然后计算100手大单占成交的比例:

嗯,有28%的比例呢。
然后计算一下小于10手的占成交比例。

有30%的比例。
再统计一下中位数和各分位数:

中位数是3,说明整个交易中,一半的成交是在等于或小于3手的,而分位数看到,1手的可以排到25%的位置,而8手则排到了75%的位置。
结论:
其实在买的都是小散,不知道是乐粉还是赌徒了。
原文地址:
http://30daydo.com/article/267
源码:https://github.com/Rockyzsu/stock/blob/master/levt_notebook.ipynb
python获取A股上市公司的盈利能力
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 8218 次浏览 • 2018-01-04 16:09
比如企业的盈利能力。
import tushare as ts
#获取2017年第3季度的盈利能力数据
ts.get_profit_data(2017,3)返回的结果:
按年度、季度获取盈利能力数据,结果返回的数据属性说明如下:
code,代码
name,名称
roe,净资产收益率(%)
net_profit_ratio,净利率(%)
gross_profit_rate,毛利率(%)
net_profits,净利润(百万元) #这里的官网信息有误,单位应该是百万
esp,每股收益
business_income,营业收入(百万元)
bips,每股主营业务收入(元)
例如返回如下结果:
code name roe net_profit_ratio gross_profit_rate net_profits \
000717 韶钢松山 79.22 9.44 14.1042 1750.2624
600793 宜宾纸业 65.40 13.31 7.9084 100.6484
600306 商业城 63.19 18.55 17.8601 114.9175
000526 *ST紫学 61.03 2.78 31.1212 63.6477
600768 宁波富邦 57.83 14.95 2.7349 88.3171
原创,转载请注明:
http://30daydo.com/article/260
查看全部
比如企业的盈利能力。
import tushare as ts返回的结果:
#获取2017年第3季度的盈利能力数据
ts.get_profit_data(2017,3)
按年度、季度获取盈利能力数据,结果返回的数据属性说明如下:
code,代码
name,名称
roe,净资产收益率(%)
net_profit_ratio,净利率(%)
gross_profit_rate,毛利率(%)
net_profits,净利润(百万元) #这里的官网信息有误,单位应该是百万
esp,每股收益
business_income,营业收入(百万元)
bips,每股主营业务收入(元)
例如返回如下结果:
code name roe net_profit_ratio gross_profit_rate net_profits \
000717 韶钢松山 79.22 9.44 14.1042 1750.2624
600793 宜宾纸业 65.40 13.31 7.9084 100.6484
600306 商业城 63.19 18.55 17.8601 114.9175
000526 *ST紫学 61.03 2.78 31.1212 63.6477
600768 宁波富邦 57.83 14.95 2.7349 88.3171
原创,转载请注明:
http://30daydo.com/article/260
python获取股票年涨跌幅排名
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 4 个评论 • 11668 次浏览 • 2017-12-30 23:11
作为年终回顾,首先看看A股市场2017的总体涨跌幅排名。
下面函数是用来获取个股某个时间段的涨跌幅。code是股票代码,start为开始时间段,end为结束时间段。def profit(code,start,end):
try:
df=ts.get_k_data(code,start=start,end=end)
except Exception,e:
print e
return None
try:
p=(df['close'].iloc[-1]-df['close'].iloc[0])/df['close'].iloc[0]*100.00
except Exception,e:
print e
return None
return round(p,2)
如果要获取华大基因的2017年涨幅,可以使用profit('300678','2016-12-31','2017-12-31')
需要注意的是,需要添加一个except的异常处理,因为部分个股停牌时间超过一年,所以该股的收盘价都是空的,这种情况就返回一个None值,在dataframe里就是NaN。
剩下了的就是枚举所有A股的个股代码了,然后把遍历所有代码,调用profit函数即可。def price_change():
basic=ts.get_stock_basics()
pro=
for code in basic.index.values:
print code
p=profit(code,'2016-12-31','2017-12-31')
pro.append(p)
basic['price_change']=pro
basic.to_csv('2017_all_price_change.xls',encoding='gbk')
df=pd.read_csv('2017_all_price_change.xls',encoding='gbk')
df.to_excel('2017_all_price_change.xls',encoding='gbk')
结果保存到2017_all_price_change.xls中,里面有个股的基本信息,还追加了一列2017年的涨跌幅,price_change
最后我们把price_change按照从高到低进行排序。 看看哪些个股排名靠前。def analysis():
df=pd.read_excel('2017_all_price_change.xls',encoding='gbk')
df=df.sort_values(by='price_change',ascending=False)
df.to_excel('2017-year.xls',encoding='gbk')
最终保存的文件为2017-year.xls,当然你也可以保存到mysql的数据库当中。engine=get_engine('stock')
df.to_sql('2017years',engine)
其中get_engine() 函数如下定义:def get_engine(db):
engine = create_engine('mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8'.format(MYSQL_USER, MYSQL_PASSWORD, MYSQL_HOST, MYSQL_PORT, db))
return engine
只需要把你的mysql数据库的用户名密码等变量加上去就可以了。
最终的结果如下:
点击查看大图
附件是导出来的excel格式的数据,你们可以拿去参考。
下一篇我们来学习统计个股的信息,比如哪类股涨得好,哪类股具有相关性,哪类股和大盘走向类似等等。
原文链接:http://30daydo.com/article/258
转载请注明出处
附件
2017-year.zip
查看全部
作为年终回顾,首先看看A股市场2017的总体涨跌幅排名。
下面函数是用来获取个股某个时间段的涨跌幅。code是股票代码,start为开始时间段,end为结束时间段。
def profit(code,start,end):
try:
df=ts.get_k_data(code,start=start,end=end)
except Exception,e:
print e
return None
try:
p=(df['close'].iloc[-1]-df['close'].iloc[0])/df['close'].iloc[0]*100.00
except Exception,e:
print e
return None
return round(p,2)
如果要获取华大基因的2017年涨幅,可以使用
profit('300678','2016-12-31','2017-12-31')需要注意的是,需要添加一个except的异常处理,因为部分个股停牌时间超过一年,所以该股的收盘价都是空的,这种情况就返回一个None值,在dataframe里就是NaN。
剩下了的就是枚举所有A股的个股代码了,然后把遍历所有代码,调用profit函数即可。
def price_change():
basic=ts.get_stock_basics()
pro=
for code in basic.index.values:
print code
p=profit(code,'2016-12-31','2017-12-31')
pro.append(p)
basic['price_change']=pro
basic.to_csv('2017_all_price_change.xls',encoding='gbk')
df=pd.read_csv('2017_all_price_change.xls',encoding='gbk')
df.to_excel('2017_all_price_change.xls',encoding='gbk')
结果保存到2017_all_price_change.xls中,里面有个股的基本信息,还追加了一列2017年的涨跌幅,price_change
最后我们把price_change按照从高到低进行排序。 看看哪些个股排名靠前。
def analysis():
df=pd.read_excel('2017_all_price_change.xls',encoding='gbk')
df=df.sort_values(by='price_change',ascending=False)
df.to_excel('2017-year.xls',encoding='gbk')
最终保存的文件为2017-year.xls,当然你也可以保存到mysql的数据库当中。
engine=get_engine('stock')
df.to_sql('2017years',engine)
其中get_engine() 函数如下定义:
def get_engine(db):
engine = create_engine('mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8'.format(MYSQL_USER, MYSQL_PASSWORD, MYSQL_HOST, MYSQL_PORT, db))
return engine
只需要把你的mysql数据库的用户名密码等变量加上去就可以了。
最终的结果如下:

点击查看大图
附件是导出来的excel格式的数据,你们可以拿去参考。
下一篇我们来学习统计个股的信息,比如哪类股涨得好,哪类股具有相关性,哪类股和大盘走向类似等等。
原文链接:http://30daydo.com/article/258
转载请注明出处
附件