
通知设置 新通知
目前支持量化接口的万一免五的券商有哪些?
李魔佛 发表了文章 • 0 个评论 • 7524 次浏览 • 2023-07-04 22:52
支持量化交易的券商如下:
其中能够股票免五的有国金证券,国盛证券,国信证券,安信证券。
其中,国金证券,国盛证券支持QMT、MiniQMT、Ptrade。
国信证券,安信证券支持QMT。
东莞证券支持Ptrade
可转债默认免五。
开户后可加入量化技术交流群,可获得编程技术指导。
【提问者需要把问题描述清楚即可,PS: 有些人动不动就说:“Ptrade不行呀”,“QMT垃圾呀”,结果让他贴代码上来瞅瞅,是他本身代码写的拉垮,目前贴出来的已知的问题,90%是个人代码问题。】
扫码添加微信咨询开户:
查看全部
其中能够股票免五的有国金证券,国盛证券,国信证券,安信证券。
其中,国金证券,国盛证券支持QMT、MiniQMT、Ptrade。
国信证券,安信证券支持QMT。
东莞证券支持Ptrade
可转债默认免五。
开户后可加入量化技术交流群,可获得编程技术指导。
【提问者需要把问题描述清楚即可,PS: 有些人动不动就说:“Ptrade不行呀”,“QMT垃圾呀”,结果让他贴代码上来瞅瞅,是他本身代码写的拉垮,目前贴出来的已知的问题,90%是个人代码问题。】
扫码添加微信咨询开户:
查看全部
支持量化交易的券商如下:

其中能够股票免五的有国金证券,国盛证券,国信证券,安信证券。
其中,国金证券,国盛证券支持QMT、MiniQMT、Ptrade。
国信证券,安信证券支持QMT。
东莞证券支持Ptrade
可转债默认免五。

开户后可加入量化技术交流群,可获得编程技术指导。
【提问者需要把问题描述清楚即可,PS: 有些人动不动就说:“Ptrade不行呀”,“QMT垃圾呀”,结果让他贴代码上来瞅瞅,是他本身代码写的拉垮,目前贴出来的已知的问题,90%是个人代码问题。】
扫码添加微信咨询开户:

其中能够股票免五的有国金证券,国盛证券,国信证券,安信证券。
其中,国金证券,国盛证券支持QMT、MiniQMT、Ptrade。
国信证券,安信证券支持QMT。
东莞证券支持Ptrade
可转债默认免五。
开户后可加入量化技术交流群,可获得编程技术指导。
【提问者需要把问题描述清楚即可,PS: 有些人动不动就说:“Ptrade不行呀”,“QMT垃圾呀”,结果让他贴代码上来瞅瞅,是他本身代码写的拉垮,目前贴出来的已知的问题,90%是个人代码问题。】
扫码添加微信咨询开户:
不同券商的ptrade的异同
李魔佛 发表了文章 • 0 个评论 • 4438 次浏览 • 2022-06-17 16:36
国盛vs湘财
1. 湘财无法访问外网,国盛的可以
2.
get_cb_list 获取可转债列表 的 国盛没有
get_history 获取历史数据函数
get_history(5, frequency='1d', field='close', security_list=['123084.SZ'], fq=None, include=False, fill='nan')国盛是没有fill参数的。
持续更新。。。待续
Ptrade开户联系:
查看全部
1. 湘财无法访问外网,国盛的可以
2.
get_cb_list 获取可转债列表 的 国盛没有
get_history 获取历史数据函数
get_history(5, frequency='1d', field='close', security_list=['123084.SZ'], fq=None, include=False, fill='nan')国盛是没有fill参数的。
持续更新。。。待续
Ptrade开户联系:
查看全部
国盛vs湘财
1. 湘财无法访问外网,国盛的可以
2.

get_cb_list 获取可转债列表 的 国盛没有
get_history 获取历史数据函数
持续更新。。。待续
Ptrade开户联系:
1. 湘财无法访问外网,国盛的可以
2.
get_cb_list 获取可转债列表 的 国盛没有
get_history 获取历史数据函数
get_history(5, frequency='1d', field='close', security_list=['123084.SZ'], fq=None, include=False, fill='nan')国盛是没有fill参数的。持续更新。。。待续
Ptrade开户联系:
python识别股票K线形态,准确率回测(一)
李魔佛 发表了文章 • 1 个评论 • 13262 次浏览 • 2022-05-22 01:13
python识别股票K线形态,准确率回测(一)
对于一些做股票技术分析的投资者来说,对常见的k线形态应该都不陌生,比如十字星,红三兵,头肩顶(底),岛型反转,吊颈线,两只乌鸦,三只乌鸦,四只乌鸦(哈)
做价投的投资者可能会对这些划线的嗤之以鼻,而短线操盘者却有可能把它奉为圭臬,以之作为买卖标准。
海乃百川,兼听则明,笔者认为多吸收不同的观点与技术,可以更加全面的加深投资认知。你画的圆圈越大,圆圈外的未知空间也越大。
本文介绍使用python对A股市场的股票(转债也可以)的K线进行识别,然后回测某个形态出现后接下来的涨跌幅,还可以通过设定的形态进行选股。
举个例子,我们可以统计所有个股出现了“早晨之星“这一形态后,一周后甚至一个月后,个股是涨了还是跌了,从大量结果中统计出一些有意义的结果。
为了便于验证查看结果图形,我们先介绍如何使用python来画股票K线图。
有数据之后,剩下画图是很简单的,很多第三方的库已经封装好了各种蜡烛图绘制函数。我们要做只是传入每天开,收盘价,以及最高最低价。
获取股票的数据
市面有不少第三方的库可以获取股票和可转债的日线数据,比如tushare和akshare。本文以股票数据为例。
以akshare为例,代码如下所示:
# pip install akshare
import akshare as ak
def get_k_line(code="sz002241"): #
df = ak.stock_zh_a_daily(symbol=code, start_date="20220101", end_date="20220515",
adjust="qfq")
# 这个函数只适合取股票数据,转债会报错,转债的日线数据可以使用其他函数,这里选择股价前复权
df.to_excel("同和药业k.xlsx")
如上面代码所示,我们使用stock_zh_a_daily方法获取一段时间的数据,这里的日期可以根据你的需求进行调整,比如设置start_date=“20200101”,end_date=“20220515”,就可以获取一年时间段的股票数据。
而股票的代码有sh与sz之分,sz代表深市的股票,所有深市的股票前面都必须带上sz,比如这里的同和药业,就是sz002241。
同样的,sh是上证交易所的股票,所有上证的股票前面必须带上sh。
这里,我们来看看获取的同和药业股票数据格式,如下图所示:
date:交易日期
open:代表开盘价
high:当天最高价
low:当天最低价
close:当天收盘价
volume:当天成交量(元)
outstanding_share:流动股本(股)
turnover:换手率
既然已经拿到了数据,下面我们来绘制K线图。
绘制K线图
在python中,绘制K线图需要用到mpl_finance库,而这个库提供了4种方式绘制K线图,这里我们介绍其中的一种,代码如下所示:
import mpl_finance as mpf
import matplotlib.pyplot as plt
import pandas as pd
#创建绘图的基本参数
fig=plt.figure(figsize=(12, 8))
ax=fig.add_subplot(111)
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
#显示出来
plt.show()
运行此段代码后,会显示如下效果图:
和东财上的同和药业的k线图基本一致的。
不过,这个K线图有一个问题,就是X坐标轴并不是显示的时间,而是数字,这是因为我们绘制K线图的方法,并没有提供X轴的参数,那怎么让下面的数字替换为时间呢?
我们先来看一段代码:
import matplotlib.ticker as ticker
#将股票时间转换为标准时间,不带时分秒的数据
def date_to_num(dates):
num_time = []
for date in dates:
date_time = datetime.strptime(date, '%Y-%m-%d')
num_date = date2num(date_time)
num_time.append(num_date)
return num_time
#创建绘图的基本参数
fig=plt.figure(figsize=(12, 8))
ax=fig.add_subplot(111)
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
df['date'] = pd.to_datetime(df['date'])
df['date'] = df['date'].apply(lambda x: x.strftime('%Y-%m-%d'))
def format_date(x, pos=None):
if x < 0 or x > len(df['date']) - 1:
return ''
return df['date'][int(x)]
ax.xaxis.set_major_formatter(ticker.FuncFormatter(format_date))
plt.setp(plt.gca().get_xticklabels(), rotation=45, horizontalalignment='right')
#显示出来
plt.show()
这里,我们定义了2个方法:第1个方法date_to_num主要的作用就是将获取的时间数据转换为标准的日期数据;第2个方法,就是根据X的数值替换时间值。
其中,set_major_formatter方法是将数值替换为时间值的操作库,而plt.setup的功能就是设置X轴的标签倾斜45度以及右对齐。运行之后,我们的K线图就显示的非常完美了,如下图所示:
均线图
虽然我们实现了K线图,但是有没有发现,其实大多数的股票交易软件K线图上面其实还标记有均线,比如常用的有5日均线,10日均线,30均线。
所以,我们需要将均线一起添加到我们的K线图之上。
计算均线的方式如下:
df["SMA5"] = df["close"].rolling(5).mean()
df["SMA10"] = df["close"].rolling(10).mean()
df["SMA30"] = df["close"].rolling(30).mean()
3行代码就可以获取到股票的均线值。
接着,我们可以使用上面的ax进行绘制均线了,
添加的代码如下所示:
ax.plot(np.arange(0, len(df)), df['SMA5']) # 绘制5日均线
ax.plot(np.arange(0, len(df)), df['SMA10']) # 绘制10日均线
ax.plot(np.arange(0, len(df)), df['SMA30']) # 绘制30日均线
这里,同样将X轴设置为数字,将这两段代码添加到上面的K线图代码中,自然也会将X轴替换为时间。运行之后,显示效果如下图所示:
这里5日均线为蓝色,10日均线为橙色,30日均线为绿色,如果需要自己设置颜色,可以在每条均线的的绘制方法中加入color参数。
细心的读者肯定发现30日均线只有最后一小段,这是因为前29日不够30日是算不出均线的,同样的5,10日均线也是如此。
成交量
最后,我们还需要绘制成交量。在多数的股票交易软件中,上面是K线图,一般下面对应的就是成交量,这样对比起来看,往往能直观的看到数据的变化。
但是,因为上面有个K线图,那么同一个画布中就有了2个图片,且它们共用一个X轴,那么我们需要更改一下基本的参数,
代码如下所示:
import mpl_finance as mpf
import matplotlib.pyplot as plt
import pandas as pd
import matplotlib.ticker as ticker
import numpy as np
#创建绘图的基本参数
fig, axes = plt.subplots(2, 1, sharex=True, figsize=(15, 10))
ax1, ax2 = axes.flatten()
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax1, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
df['date'] = pd.to_datetime(df['date'])
df['date'] = df['date'].apply(lambda x: x.strftime('%Y-%m-%d'))
def format_date(x, pos=None):
if x < 0 or x > len(df['date']) - 1:
return ''
return df['date'][int(x)]
df["SMA5"] = df["close"].rolling(5).mean()
df["SMA10"] = df["close"].rolling(10).mean()
df["SMA30"] = df["close"].rolling(30).mean()
ax1.plot(np.arange(0, len(df)), df['SMA5']) # 绘制5日均线
ax1.plot(np.arange(0, len(df)), df['SMA10']) # 绘制10日均线
ax1.plot(np.arange(0, len(df)), df['SMA30']) # 绘制30日均线
ax1.xaxis.set_major_formatter(ticker.FuncFormatter(format_date))
plt.setp(plt.gca().get_xticklabels(), rotation=45, horizontalalignment='right')
#显示出来
plt.show()
这里,我们将绘图的画布设置为2行1列。同时,将上面绘制的所有数据都更改为ax1,这样均线与K线图会绘制到第一个子图中。
接着,我们需要绘制成交量,但是我们知道,一般股票交易软件都将上涨的那天成交量设置为红色,而将下跌的成交量绘制成绿色。所以,首先我们要做的是将获取的股票数据根据当天的涨跌情况进行分类。
具体代码如下:
red_pred = np.where(df["close"] > df["open"], df["volume"], 0)
blue_pred = np.where(df["close"] < df["open"], df["volume"], 0)
如上面代码所示,我们通过np.where(condition, x, y)筛选数据。这里满足条件condition,输出X,不满足条件输出Y,这样我们就将涨跌的成交量数据进行了分类。
最后,我们直接通过柱状图方法绘制成交量,
具体代码如下所示:
ax2.bar(np.arange(0, len(df)), red_pred, facecolor="red")
ax2.bar(np.arange(0, len(df)), blue_pred, facecolor="blue")
将这4行代码,全部加入到plt.show()代码的前面即可。
运行之后,输出的效果图如下:
根据定义编写形态
接下来,我们根据定义来构造一个简单的形态函数,比如长上影线。
上影线
根据网络上的定义:
⑤上影阳线:开盘后价格冲高回落,涨势受阻,虽然收盘价仍高于开盘价,但上方有阻力,可视为弱势。
⑥上影阴线:开盘后价格冲高受阻,涨势受阻,收盘价低于开盘价,上方有阻力,可视为弱势。
那么简单定义为:(high - close)/close > 7%,(high - open)/open > 7% ,可能不是太精确,这里只是为了演示,忽略一些具体细节。
简单理解就是,当天最高价比收盘价,开盘价高得多。
长上影匹配函数,简单,只有一行就搞定。
def long_up_shadow(o,c,h,l):
return True if (h-c)/c >=0.07 and (h-o)/o>=0.07 else False
然后把这个长上影函数应用到上面的同和药业。
得到的效果:
df = pd.read_excel("同和药业k.xlsx")
count_num = []
for row,item in df.iterrows():
if long_up_shadow(item['open'],item['close'],item['high'],item['low']):
count_num.append(row)
plot_image(df,count_num)
图里面的4个箭头长上影是python自动标上去的,然后对着数据到同花顺核对一下,都是满足长度大于7%的。
可以看到在3月18日和28日的两根长上影之后,同和药业的股价走了一波趋势下跌。【PS:选这个股票并没有刻意去挑选,在集思录默认排名,找了一个跌幅第一个转债的正股就把代码拷贝过来测试】
那么,有这么多的形态,难道每一个都要自己写代码筛选形态吗? 不用哈,因为已经有人写了第三方的库,你只需要调用就可以了。
截取的部分函数名与说明
比如,像两只乌鸦,描述起来都感觉有点复杂,自己手撸代码都会搞出一堆bug。而用taLib这个库,你只需要一行调用代码,就可以完成这些复杂的形态筛选工作。
示例代码:
df['tow_crows'] = talib.CDL2CROWS(df['open'].values, df['high'].values, df['low'].values, df['close'].values)
pattern = df[(df['tow_crows'] == 100) | (df['tow_crows'] == -100)]
上面得到的pattern就是满足要求的形态,如CDL2CROWS 两只乌鸦。测试的个股是歌尔股份2020的日K线。
虽然我不知道两只乌鸦是什么玩意,但是可以通过遍历某个长周期(5-10年)下的全部A股数据,通过数据证伪,统计这个形态过后的一周或一个月(个人随意设定)涨跌幅,来证伪这个形态的有效性。
如果得到的是一个50%概率涨跌概况,那说明这个指标形态只是个游走在随机概率的指标,并不能作为一个有效指标参考。
(未完待续) 查看全部
对于一些做股票技术分析的投资者来说,对常见的k线形态应该都不陌生,比如十字星,红三兵,头肩顶(底),岛型反转,吊颈线,两只乌鸦,三只乌鸦,四只乌鸦(哈)
做价投的投资者可能会对这些划线的嗤之以鼻,而短线操盘者却有可能把它奉为圭臬,以之作为买卖标准。
海乃百川,兼听则明,笔者认为多吸收不同的观点与技术,可以更加全面的加深投资认知。你画的圆圈越大,圆圈外的未知空间也越大。
本文介绍使用python对A股市场的股票(转债也可以)的K线进行识别,然后回测某个形态出现后接下来的涨跌幅,还可以通过设定的形态进行选股。
举个例子,我们可以统计所有个股出现了“早晨之星“这一形态后,一周后甚至一个月后,个股是涨了还是跌了,从大量结果中统计出一些有意义的结果。
为了便于验证查看结果图形,我们先介绍如何使用python来画股票K线图。
有数据之后,剩下画图是很简单的,很多第三方的库已经封装好了各种蜡烛图绘制函数。我们要做只是传入每天开,收盘价,以及最高最低价。
获取股票的数据
市面有不少第三方的库可以获取股票和可转债的日线数据,比如tushare和akshare。本文以股票数据为例。
以akshare为例,代码如下所示:
# pip install akshare
import akshare as ak
def get_k_line(code="sz002241"): #
df = ak.stock_zh_a_daily(symbol=code, start_date="20220101", end_date="20220515",
adjust="qfq")
# 这个函数只适合取股票数据,转债会报错,转债的日线数据可以使用其他函数,这里选择股价前复权
df.to_excel("同和药业k.xlsx")
如上面代码所示,我们使用stock_zh_a_daily方法获取一段时间的数据,这里的日期可以根据你的需求进行调整,比如设置start_date=“20200101”,end_date=“20220515”,就可以获取一年时间段的股票数据。
而股票的代码有sh与sz之分,sz代表深市的股票,所有深市的股票前面都必须带上sz,比如这里的同和药业,就是sz002241。
同样的,sh是上证交易所的股票,所有上证的股票前面必须带上sh。
这里,我们来看看获取的同和药业股票数据格式,如下图所示:
date:交易日期
open:代表开盘价
high:当天最高价
low:当天最低价
close:当天收盘价
volume:当天成交量(元)
outstanding_share:流动股本(股)
turnover:换手率
既然已经拿到了数据,下面我们来绘制K线图。
绘制K线图
在python中,绘制K线图需要用到mpl_finance库,而这个库提供了4种方式绘制K线图,这里我们介绍其中的一种,代码如下所示:
import mpl_finance as mpf
import matplotlib.pyplot as plt
import pandas as pd
#创建绘图的基本参数
fig=plt.figure(figsize=(12, 8))
ax=fig.add_subplot(111)
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
#显示出来
plt.show()
运行此段代码后,会显示如下效果图:
和东财上的同和药业的k线图基本一致的。
不过,这个K线图有一个问题,就是X坐标轴并不是显示的时间,而是数字,这是因为我们绘制K线图的方法,并没有提供X轴的参数,那怎么让下面的数字替换为时间呢?
我们先来看一段代码:
import matplotlib.ticker as ticker
#将股票时间转换为标准时间,不带时分秒的数据
def date_to_num(dates):
num_time = []
for date in dates:
date_time = datetime.strptime(date, '%Y-%m-%d')
num_date = date2num(date_time)
num_time.append(num_date)
return num_time
#创建绘图的基本参数
fig=plt.figure(figsize=(12, 8))
ax=fig.add_subplot(111)
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
df['date'] = pd.to_datetime(df['date'])
df['date'] = df['date'].apply(lambda x: x.strftime('%Y-%m-%d'))
def format_date(x, pos=None):
if x < 0 or x > len(df['date']) - 1:
return ''
return df['date'][int(x)]
ax.xaxis.set_major_formatter(ticker.FuncFormatter(format_date))
plt.setp(plt.gca().get_xticklabels(), rotation=45, horizontalalignment='right')
#显示出来
plt.show()
这里,我们定义了2个方法:第1个方法date_to_num主要的作用就是将获取的时间数据转换为标准的日期数据;第2个方法,就是根据X的数值替换时间值。
其中,set_major_formatter方法是将数值替换为时间值的操作库,而plt.setup的功能就是设置X轴的标签倾斜45度以及右对齐。运行之后,我们的K线图就显示的非常完美了,如下图所示:
均线图
虽然我们实现了K线图,但是有没有发现,其实大多数的股票交易软件K线图上面其实还标记有均线,比如常用的有5日均线,10日均线,30均线。
所以,我们需要将均线一起添加到我们的K线图之上。
计算均线的方式如下:
df["SMA5"] = df["close"].rolling(5).mean()
df["SMA10"] = df["close"].rolling(10).mean()
df["SMA30"] = df["close"].rolling(30).mean()
3行代码就可以获取到股票的均线值。
接着,我们可以使用上面的ax进行绘制均线了,
添加的代码如下所示:
ax.plot(np.arange(0, len(df)), df['SMA5']) # 绘制5日均线
ax.plot(np.arange(0, len(df)), df['SMA10']) # 绘制10日均线
ax.plot(np.arange(0, len(df)), df['SMA30']) # 绘制30日均线
这里,同样将X轴设置为数字,将这两段代码添加到上面的K线图代码中,自然也会将X轴替换为时间。运行之后,显示效果如下图所示:
这里5日均线为蓝色,10日均线为橙色,30日均线为绿色,如果需要自己设置颜色,可以在每条均线的的绘制方法中加入color参数。
细心的读者肯定发现30日均线只有最后一小段,这是因为前29日不够30日是算不出均线的,同样的5,10日均线也是如此。
成交量
最后,我们还需要绘制成交量。在多数的股票交易软件中,上面是K线图,一般下面对应的就是成交量,这样对比起来看,往往能直观的看到数据的变化。
但是,因为上面有个K线图,那么同一个画布中就有了2个图片,且它们共用一个X轴,那么我们需要更改一下基本的参数,
代码如下所示:
import mpl_finance as mpf
import matplotlib.pyplot as plt
import pandas as pd
import matplotlib.ticker as ticker
import numpy as np
#创建绘图的基本参数
fig, axes = plt.subplots(2, 1, sharex=True, figsize=(15, 10))
ax1, ax2 = axes.flatten()
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax1, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
df['date'] = pd.to_datetime(df['date'])
df['date'] = df['date'].apply(lambda x: x.strftime('%Y-%m-%d'))
def format_date(x, pos=None):
if x < 0 or x > len(df['date']) - 1:
return ''
return df['date'][int(x)]
df["SMA5"] = df["close"].rolling(5).mean()
df["SMA10"] = df["close"].rolling(10).mean()
df["SMA30"] = df["close"].rolling(30).mean()
ax1.plot(np.arange(0, len(df)), df['SMA5']) # 绘制5日均线
ax1.plot(np.arange(0, len(df)), df['SMA10']) # 绘制10日均线
ax1.plot(np.arange(0, len(df)), df['SMA30']) # 绘制30日均线
ax1.xaxis.set_major_formatter(ticker.FuncFormatter(format_date))
plt.setp(plt.gca().get_xticklabels(), rotation=45, horizontalalignment='right')
#显示出来
plt.show()
这里,我们将绘图的画布设置为2行1列。同时,将上面绘制的所有数据都更改为ax1,这样均线与K线图会绘制到第一个子图中。
接着,我们需要绘制成交量,但是我们知道,一般股票交易软件都将上涨的那天成交量设置为红色,而将下跌的成交量绘制成绿色。所以,首先我们要做的是将获取的股票数据根据当天的涨跌情况进行分类。
具体代码如下:
red_pred = np.where(df["close"] > df["open"], df["volume"], 0)
blue_pred = np.where(df["close"] < df["open"], df["volume"], 0)
如上面代码所示,我们通过np.where(condition, x, y)筛选数据。这里满足条件condition,输出X,不满足条件输出Y,这样我们就将涨跌的成交量数据进行了分类。
最后,我们直接通过柱状图方法绘制成交量,
具体代码如下所示:
ax2.bar(np.arange(0, len(df)), red_pred, facecolor="red")
ax2.bar(np.arange(0, len(df)), blue_pred, facecolor="blue")
将这4行代码,全部加入到plt.show()代码的前面即可。
运行之后,输出的效果图如下:
根据定义编写形态
接下来,我们根据定义来构造一个简单的形态函数,比如长上影线。
上影线
根据网络上的定义:
⑤上影阳线:开盘后价格冲高回落,涨势受阻,虽然收盘价仍高于开盘价,但上方有阻力,可视为弱势。
⑥上影阴线:开盘后价格冲高受阻,涨势受阻,收盘价低于开盘价,上方有阻力,可视为弱势。
那么简单定义为:(high - close)/close > 7%,(high - open)/open > 7% ,可能不是太精确,这里只是为了演示,忽略一些具体细节。
简单理解就是,当天最高价比收盘价,开盘价高得多。
长上影匹配函数,简单,只有一行就搞定。
def long_up_shadow(o,c,h,l):
return True if (h-c)/c >=0.07 and (h-o)/o>=0.07 else False
然后把这个长上影函数应用到上面的同和药业。
得到的效果:
df = pd.read_excel("同和药业k.xlsx")
count_num = []
for row,item in df.iterrows():
if long_up_shadow(item['open'],item['close'],item['high'],item['low']):
count_num.append(row)
plot_image(df,count_num)
图里面的4个箭头长上影是python自动标上去的,然后对着数据到同花顺核对一下,都是满足长度大于7%的。
可以看到在3月18日和28日的两根长上影之后,同和药业的股价走了一波趋势下跌。【PS:选这个股票并没有刻意去挑选,在集思录默认排名,找了一个跌幅第一个转债的正股就把代码拷贝过来测试】
那么,有这么多的形态,难道每一个都要自己写代码筛选形态吗? 不用哈,因为已经有人写了第三方的库,你只需要调用就可以了。
截取的部分函数名与说明
比如,像两只乌鸦,描述起来都感觉有点复杂,自己手撸代码都会搞出一堆bug。而用taLib这个库,你只需要一行调用代码,就可以完成这些复杂的形态筛选工作。
示例代码:
df['tow_crows'] = talib.CDL2CROWS(df['open'].values, df['high'].values, df['low'].values, df['close'].values)
pattern = df[(df['tow_crows'] == 100) | (df['tow_crows'] == -100)]
上面得到的pattern就是满足要求的形态,如CDL2CROWS 两只乌鸦。测试的个股是歌尔股份2020的日K线。
虽然我不知道两只乌鸦是什么玩意,但是可以通过遍历某个长周期(5-10年)下的全部A股数据,通过数据证伪,统计这个形态过后的一周或一个月(个人随意设定)涨跌幅,来证伪这个形态的有效性。
如果得到的是一个50%概率涨跌概况,那说明这个指标形态只是个游走在随机概率的指标,并不能作为一个有效指标参考。
(未完待续) 查看全部
python识别股票K线形态,准确率回测(一)
对于一些做股票技术分析的投资者来说,对常见的k线形态应该都不陌生,比如十字星,红三兵,头肩顶(底),岛型反转,吊颈线,两只乌鸦,三只乌鸦,四只乌鸦(哈)

做价投的投资者可能会对这些划线的嗤之以鼻,而短线操盘者却有可能把它奉为圭臬,以之作为买卖标准。
海乃百川,兼听则明,笔者认为多吸收不同的观点与技术,可以更加全面的加深投资认知。你画的圆圈越大,圆圈外的未知空间也越大。
本文介绍使用python对A股市场的股票(转债也可以)的K线进行识别,然后回测某个形态出现后接下来的涨跌幅,还可以通过设定的形态进行选股。
举个例子,我们可以统计所有个股出现了“早晨之星“这一形态后,一周后甚至一个月后,个股是涨了还是跌了,从大量结果中统计出一些有意义的结果。
为了便于验证查看结果图形,我们先介绍如何使用python来画股票K线图。
有数据之后,剩下画图是很简单的,很多第三方的库已经封装好了各种蜡烛图绘制函数。我们要做只是传入每天开,收盘价,以及最高最低价。
获取股票的数据
市面有不少第三方的库可以获取股票和可转债的日线数据,比如tushare和akshare。本文以股票数据为例。
以akshare为例,代码如下所示:
如上面代码所示,我们使用stock_zh_a_daily方法获取一段时间的数据,这里的日期可以根据你的需求进行调整,比如设置start_date=“20200101”,end_date=“20220515”,就可以获取一年时间段的股票数据。
而股票的代码有sh与sz之分,sz代表深市的股票,所有深市的股票前面都必须带上sz,比如这里的同和药业,就是sz002241。
同样的,sh是上证交易所的股票,所有上证的股票前面必须带上sh。
这里,我们来看看获取的同和药业股票数据格式,如下图所示:
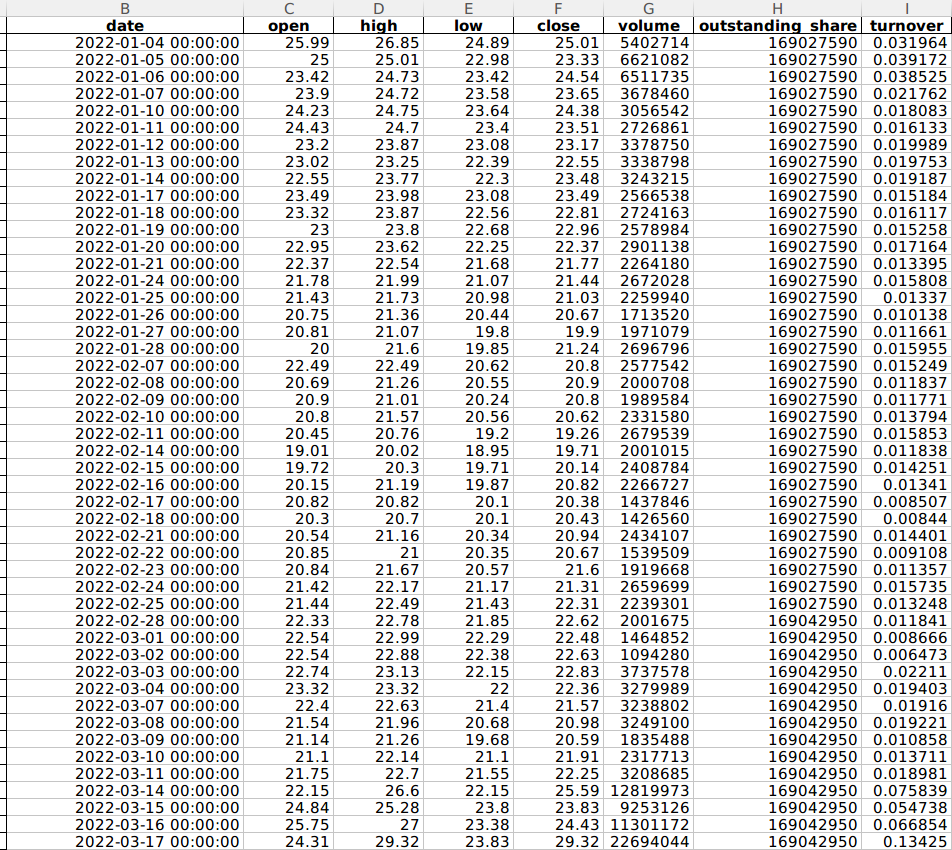
既然已经拿到了数据,下面我们来绘制K线图。
绘制K线图
在python中,绘制K线图需要用到mpl_finance库,而这个库提供了4种方式绘制K线图,这里我们介绍其中的一种,代码如下所示:
运行此段代码后,会显示如下效果图:
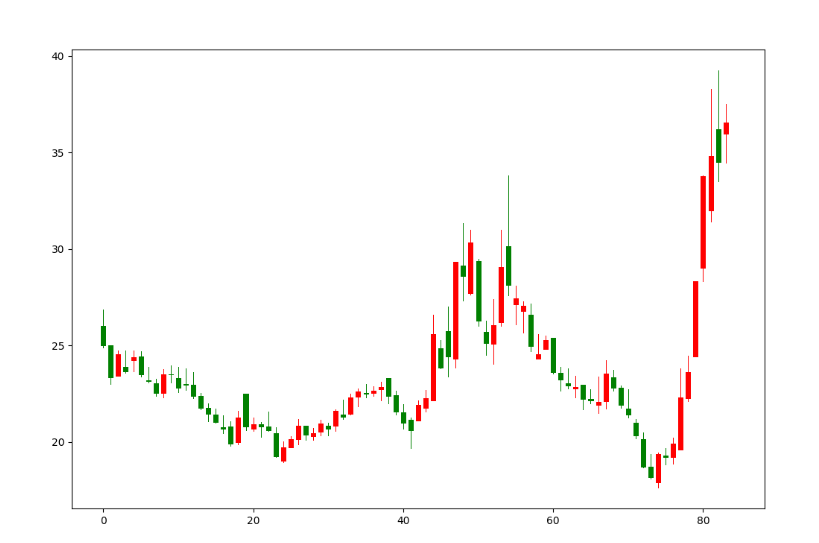
和东财上的同和药业的k线图基本一致的。
不过,这个K线图有一个问题,就是X坐标轴并不是显示的时间,而是数字,这是因为我们绘制K线图的方法,并没有提供X轴的参数,那怎么让下面的数字替换为时间呢?
我们先来看一段代码:
这里,我们定义了2个方法:第1个方法date_to_num主要的作用就是将获取的时间数据转换为标准的日期数据;第2个方法,就是根据X的数值替换时间值。
其中,set_major_formatter方法是将数值替换为时间值的操作库,而plt.setup的功能就是设置X轴的标签倾斜45度以及右对齐。运行之后,我们的K线图就显示的非常完美了,如下图所示:
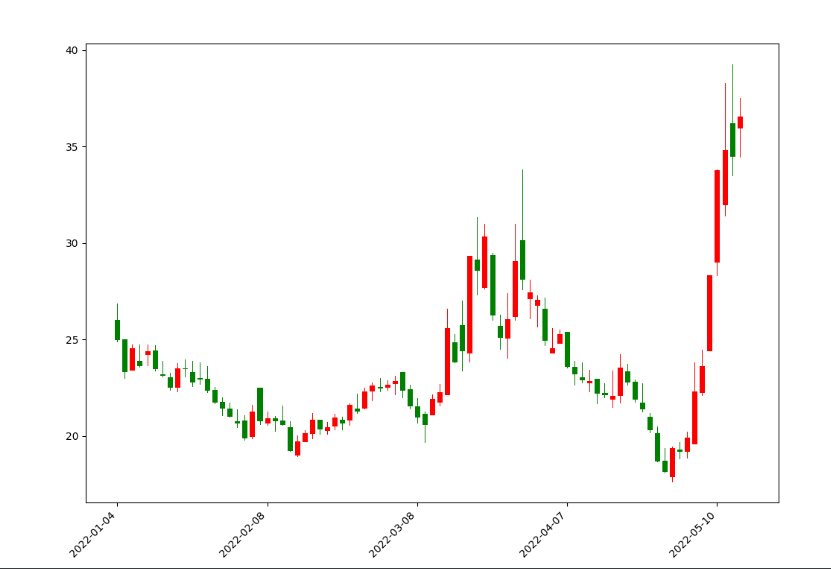
均线图
虽然我们实现了K线图,但是有没有发现,其实大多数的股票交易软件K线图上面其实还标记有均线,比如常用的有5日均线,10日均线,30均线。
所以,我们需要将均线一起添加到我们的K线图之上。
计算均线的方式如下:
3行代码就可以获取到股票的均线值。
接着,我们可以使用上面的ax进行绘制均线了,
添加的代码如下所示:
这里,同样将X轴设置为数字,将这两段代码添加到上面的K线图代码中,自然也会将X轴替换为时间。运行之后,显示效果如下图所示:
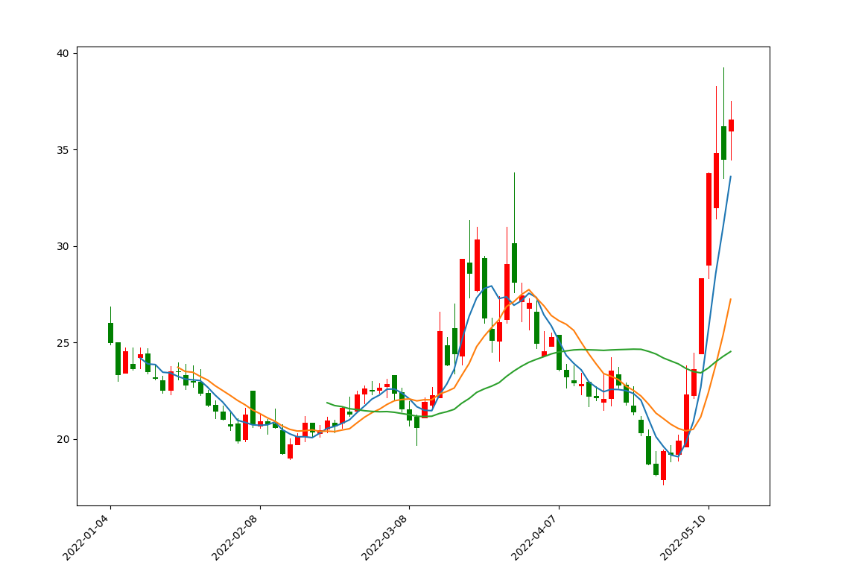
这里5日均线为蓝色,10日均线为橙色,30日均线为绿色,如果需要自己设置颜色,可以在每条均线的的绘制方法中加入color参数。
细心的读者肯定发现30日均线只有最后一小段,这是因为前29日不够30日是算不出均线的,同样的5,10日均线也是如此。
成交量
最后,我们还需要绘制成交量。在多数的股票交易软件中,上面是K线图,一般下面对应的就是成交量,这样对比起来看,往往能直观的看到数据的变化。
但是,因为上面有个K线图,那么同一个画布中就有了2个图片,且它们共用一个X轴,那么我们需要更改一下基本的参数,
代码如下所示:
这里,我们将绘图的画布设置为2行1列。同时,将上面绘制的所有数据都更改为ax1,这样均线与K线图会绘制到第一个子图中。
接着,我们需要绘制成交量,但是我们知道,一般股票交易软件都将上涨的那天成交量设置为红色,而将下跌的成交量绘制成绿色。所以,首先我们要做的是将获取的股票数据根据当天的涨跌情况进行分类。
具体代码如下:
如上面代码所示,我们通过np.where(condition, x, y)筛选数据。这里满足条件condition,输出X,不满足条件输出Y,这样我们就将涨跌的成交量数据进行了分类。
最后,我们直接通过柱状图方法绘制成交量,
具体代码如下所示:
将这4行代码,全部加入到plt.show()代码的前面即可。
运行之后,输出的效果图如下:
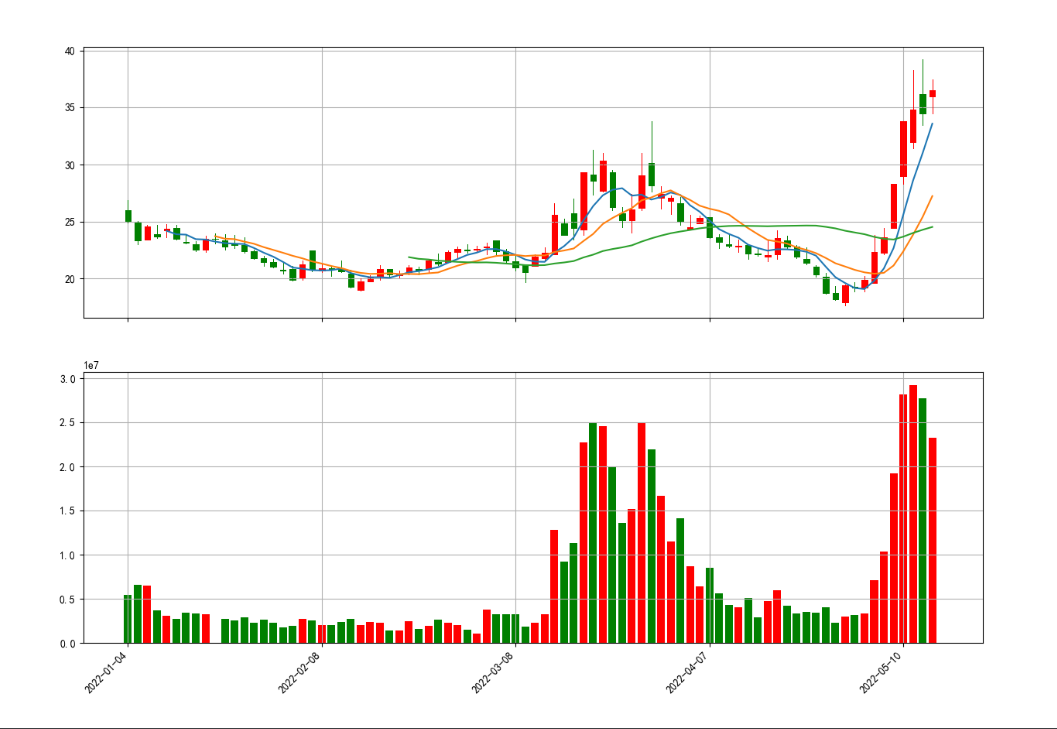
根据定义编写形态
接下来,我们根据定义来构造一个简单的形态函数,比如长上影线。
上影线

根据网络上的定义:
⑤上影阳线:开盘后价格冲高回落,涨势受阻,虽然收盘价仍高于开盘价,但上方有阻力,可视为弱势。
⑥上影阴线:开盘后价格冲高受阻,涨势受阻,收盘价低于开盘价,上方有阻力,可视为弱势。

那么简单定义为:(high - close)/close > 7%,(high - open)/open > 7% ,可能不是太精确,这里只是为了演示,忽略一些具体细节。
简单理解就是,当天最高价比收盘价,开盘价高得多。
长上影匹配函数,简单,只有一行就搞定。
然后把这个长上影函数应用到上面的同和药业。
得到的效果:
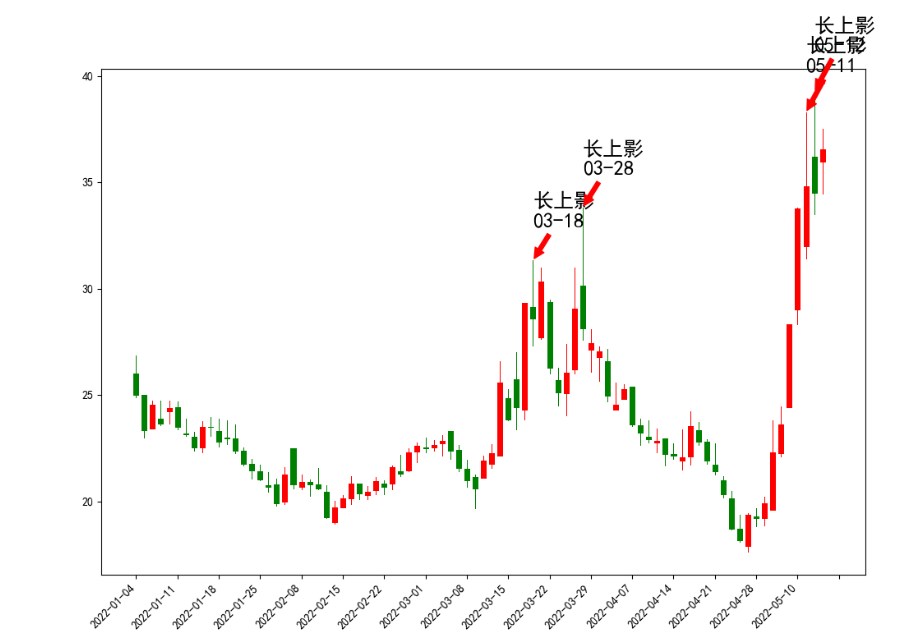
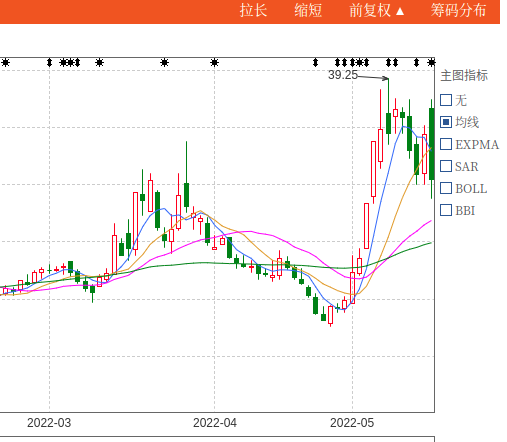
图里面的4个箭头长上影是python自动标上去的,然后对着数据到同花顺核对一下,都是满足长度大于7%的。
可以看到在3月18日和28日的两根长上影之后,同和药业的股价走了一波趋势下跌。【PS:选这个股票并没有刻意去挑选,在集思录默认排名,找了一个跌幅第一个转债的正股就把代码拷贝过来测试】
那么,有这么多的形态,难道每一个都要自己写代码筛选形态吗? 不用哈,因为已经有人写了第三方的库,你只需要调用就可以了。

截取的部分函数名与说明
比如,像两只乌鸦,描述起来都感觉有点复杂,自己手撸代码都会搞出一堆bug。而用taLib这个库,你只需要一行调用代码,就可以完成这些复杂的形态筛选工作。
示例代码:
上面得到的pattern就是满足要求的形态,如CDL2CROWS 两只乌鸦。测试的个股是歌尔股份2020的日K线。
虽然我不知道两只乌鸦是什么玩意,但是可以通过遍历某个长周期(5-10年)下的全部A股数据,通过数据证伪,统计这个形态过后的一周或一个月(个人随意设定)涨跌幅,来证伪这个形态的有效性。
如果得到的是一个50%概率涨跌概况,那说明这个指标形态只是个游走在随机概率的指标,并不能作为一个有效指标参考。
(未完待续)
对于一些做股票技术分析的投资者来说,对常见的k线形态应该都不陌生,比如十字星,红三兵,头肩顶(底),岛型反转,吊颈线,两只乌鸦,三只乌鸦,四只乌鸦(哈)
做价投的投资者可能会对这些划线的嗤之以鼻,而短线操盘者却有可能把它奉为圭臬,以之作为买卖标准。
海乃百川,兼听则明,笔者认为多吸收不同的观点与技术,可以更加全面的加深投资认知。你画的圆圈越大,圆圈外的未知空间也越大。
本文介绍使用python对A股市场的股票(转债也可以)的K线进行识别,然后回测某个形态出现后接下来的涨跌幅,还可以通过设定的形态进行选股。
举个例子,我们可以统计所有个股出现了“早晨之星“这一形态后,一周后甚至一个月后,个股是涨了还是跌了,从大量结果中统计出一些有意义的结果。
为了便于验证查看结果图形,我们先介绍如何使用python来画股票K线图。
有数据之后,剩下画图是很简单的,很多第三方的库已经封装好了各种蜡烛图绘制函数。我们要做只是传入每天开,收盘价,以及最高最低价。
获取股票的数据
市面有不少第三方的库可以获取股票和可转债的日线数据,比如tushare和akshare。本文以股票数据为例。
以akshare为例,代码如下所示:
# pip install akshare
import akshare as ak
def get_k_line(code="sz002241"): #
df = ak.stock_zh_a_daily(symbol=code, start_date="20220101", end_date="20220515",
adjust="qfq")
# 这个函数只适合取股票数据,转债会报错,转债的日线数据可以使用其他函数,这里选择股价前复权
df.to_excel("同和药业k.xlsx")
如上面代码所示,我们使用stock_zh_a_daily方法获取一段时间的数据,这里的日期可以根据你的需求进行调整,比如设置start_date=“20200101”,end_date=“20220515”,就可以获取一年时间段的股票数据。
而股票的代码有sh与sz之分,sz代表深市的股票,所有深市的股票前面都必须带上sz,比如这里的同和药业,就是sz002241。
同样的,sh是上证交易所的股票,所有上证的股票前面必须带上sh。
这里,我们来看看获取的同和药业股票数据格式,如下图所示:
date:交易日期
open:代表开盘价
high:当天最高价
low:当天最低价
close:当天收盘价
volume:当天成交量(元)
outstanding_share:流动股本(股)
turnover:换手率
既然已经拿到了数据,下面我们来绘制K线图。
绘制K线图
在python中,绘制K线图需要用到mpl_finance库,而这个库提供了4种方式绘制K线图,这里我们介绍其中的一种,代码如下所示:
import mpl_finance as mpf
import matplotlib.pyplot as plt
import pandas as pd
#创建绘图的基本参数
fig=plt.figure(figsize=(12, 8))
ax=fig.add_subplot(111)
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
#显示出来
plt.show()
运行此段代码后,会显示如下效果图:
和东财上的同和药业的k线图基本一致的。
不过,这个K线图有一个问题,就是X坐标轴并不是显示的时间,而是数字,这是因为我们绘制K线图的方法,并没有提供X轴的参数,那怎么让下面的数字替换为时间呢?
我们先来看一段代码:
import matplotlib.ticker as ticker
#将股票时间转换为标准时间,不带时分秒的数据
def date_to_num(dates):
num_time = []
for date in dates:
date_time = datetime.strptime(date, '%Y-%m-%d')
num_date = date2num(date_time)
num_time.append(num_date)
return num_time
#创建绘图的基本参数
fig=plt.figure(figsize=(12, 8))
ax=fig.add_subplot(111)
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
df['date'] = pd.to_datetime(df['date'])
df['date'] = df['date'].apply(lambda x: x.strftime('%Y-%m-%d'))
def format_date(x, pos=None):
if x < 0 or x > len(df['date']) - 1:
return ''
return df['date'][int(x)]
ax.xaxis.set_major_formatter(ticker.FuncFormatter(format_date))
plt.setp(plt.gca().get_xticklabels(), rotation=45, horizontalalignment='right')
#显示出来
plt.show()
这里,我们定义了2个方法:第1个方法date_to_num主要的作用就是将获取的时间数据转换为标准的日期数据;第2个方法,就是根据X的数值替换时间值。
其中,set_major_formatter方法是将数值替换为时间值的操作库,而plt.setup的功能就是设置X轴的标签倾斜45度以及右对齐。运行之后,我们的K线图就显示的非常完美了,如下图所示:
均线图
虽然我们实现了K线图,但是有没有发现,其实大多数的股票交易软件K线图上面其实还标记有均线,比如常用的有5日均线,10日均线,30均线。
所以,我们需要将均线一起添加到我们的K线图之上。
计算均线的方式如下:
df["SMA5"] = df["close"].rolling(5).mean()
df["SMA10"] = df["close"].rolling(10).mean()
df["SMA30"] = df["close"].rolling(30).mean()
3行代码就可以获取到股票的均线值。
接着,我们可以使用上面的ax进行绘制均线了,
添加的代码如下所示:
ax.plot(np.arange(0, len(df)), df['SMA5']) # 绘制5日均线
ax.plot(np.arange(0, len(df)), df['SMA10']) # 绘制10日均线
ax.plot(np.arange(0, len(df)), df['SMA30']) # 绘制30日均线
这里,同样将X轴设置为数字,将这两段代码添加到上面的K线图代码中,自然也会将X轴替换为时间。运行之后,显示效果如下图所示:
这里5日均线为蓝色,10日均线为橙色,30日均线为绿色,如果需要自己设置颜色,可以在每条均线的的绘制方法中加入color参数。
细心的读者肯定发现30日均线只有最后一小段,这是因为前29日不够30日是算不出均线的,同样的5,10日均线也是如此。
成交量
最后,我们还需要绘制成交量。在多数的股票交易软件中,上面是K线图,一般下面对应的就是成交量,这样对比起来看,往往能直观的看到数据的变化。
但是,因为上面有个K线图,那么同一个画布中就有了2个图片,且它们共用一个X轴,那么我们需要更改一下基本的参数,
代码如下所示:
import mpl_finance as mpf
import matplotlib.pyplot as plt
import pandas as pd
import matplotlib.ticker as ticker
import numpy as np
#创建绘图的基本参数
fig, axes = plt.subplots(2, 1, sharex=True, figsize=(15, 10))
ax1, ax2 = axes.flatten()
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax1, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
df['date'] = pd.to_datetime(df['date'])
df['date'] = df['date'].apply(lambda x: x.strftime('%Y-%m-%d'))
def format_date(x, pos=None):
if x < 0 or x > len(df['date']) - 1:
return ''
return df['date'][int(x)]
df["SMA5"] = df["close"].rolling(5).mean()
df["SMA10"] = df["close"].rolling(10).mean()
df["SMA30"] = df["close"].rolling(30).mean()
ax1.plot(np.arange(0, len(df)), df['SMA5']) # 绘制5日均线
ax1.plot(np.arange(0, len(df)), df['SMA10']) # 绘制10日均线
ax1.plot(np.arange(0, len(df)), df['SMA30']) # 绘制30日均线
ax1.xaxis.set_major_formatter(ticker.FuncFormatter(format_date))
plt.setp(plt.gca().get_xticklabels(), rotation=45, horizontalalignment='right')
#显示出来
plt.show()
这里,我们将绘图的画布设置为2行1列。同时,将上面绘制的所有数据都更改为ax1,这样均线与K线图会绘制到第一个子图中。
接着,我们需要绘制成交量,但是我们知道,一般股票交易软件都将上涨的那天成交量设置为红色,而将下跌的成交量绘制成绿色。所以,首先我们要做的是将获取的股票数据根据当天的涨跌情况进行分类。
具体代码如下:
red_pred = np.where(df["close"] > df["open"], df["volume"], 0)
blue_pred = np.where(df["close"] < df["open"], df["volume"], 0)
如上面代码所示,我们通过np.where(condition, x, y)筛选数据。这里满足条件condition,输出X,不满足条件输出Y,这样我们就将涨跌的成交量数据进行了分类。
最后,我们直接通过柱状图方法绘制成交量,
具体代码如下所示:
ax2.bar(np.arange(0, len(df)), red_pred, facecolor="red")
ax2.bar(np.arange(0, len(df)), blue_pred, facecolor="blue")
将这4行代码,全部加入到plt.show()代码的前面即可。
运行之后,输出的效果图如下:
根据定义编写形态
接下来,我们根据定义来构造一个简单的形态函数,比如长上影线。
上影线
根据网络上的定义:
⑤上影阳线:开盘后价格冲高回落,涨势受阻,虽然收盘价仍高于开盘价,但上方有阻力,可视为弱势。
⑥上影阴线:开盘后价格冲高受阻,涨势受阻,收盘价低于开盘价,上方有阻力,可视为弱势。
那么简单定义为:(high - close)/close > 7%,(high - open)/open > 7% ,可能不是太精确,这里只是为了演示,忽略一些具体细节。
简单理解就是,当天最高价比收盘价,开盘价高得多。
长上影匹配函数,简单,只有一行就搞定。
def long_up_shadow(o,c,h,l):
return True if (h-c)/c >=0.07 and (h-o)/o>=0.07 else False
然后把这个长上影函数应用到上面的同和药业。
得到的效果:
df = pd.read_excel("同和药业k.xlsx")
count_num = []
for row,item in df.iterrows():
if long_up_shadow(item['open'],item['close'],item['high'],item['low']):
count_num.append(row)
plot_image(df,count_num)图里面的4个箭头长上影是python自动标上去的,然后对着数据到同花顺核对一下,都是满足长度大于7%的。
可以看到在3月18日和28日的两根长上影之后,同和药业的股价走了一波趋势下跌。【PS:选这个股票并没有刻意去挑选,在集思录默认排名,找了一个跌幅第一个转债的正股就把代码拷贝过来测试】
那么,有这么多的形态,难道每一个都要自己写代码筛选形态吗? 不用哈,因为已经有人写了第三方的库,你只需要调用就可以了。
截取的部分函数名与说明
比如,像两只乌鸦,描述起来都感觉有点复杂,自己手撸代码都会搞出一堆bug。而用taLib这个库,你只需要一行调用代码,就可以完成这些复杂的形态筛选工作。
示例代码:
df['tow_crows'] = talib.CDL2CROWS(df['open'].values, df['high'].values, df['low'].values, df['close'].values)
pattern = df[(df['tow_crows'] == 100) | (df['tow_crows'] == -100)]
上面得到的pattern就是满足要求的形态,如CDL2CROWS 两只乌鸦。测试的个股是歌尔股份2020的日K线。
虽然我不知道两只乌鸦是什么玩意,但是可以通过遍历某个长周期(5-10年)下的全部A股数据,通过数据证伪,统计这个形态过后的一周或一个月(个人随意设定)涨跌幅,来证伪这个形态的有效性。
如果得到的是一个50%概率涨跌概况,那说明这个指标形态只是个游走在随机概率的指标,并不能作为一个有效指标参考。
(未完待续)
python判断可转债是否强赎
李魔佛 发表了文章 • 0 个评论 • 4007 次浏览 • 2021-04-02 13:41
占坑,后期把代码整理下放上来。
更新:
制作好了一个接口,用户可以直接调用。
数据来源与集思录。
获取 排除满足强赎天数剩余N天的可转债,排除强赎可转债。
比如:DAY=4 ,那么假设强赎满足天数为15天,那么返回市场上强赎强赎倒数天数大于4天的可转债,即返回小于或者等于11天以下的转债。把满足条件还差4天的转债排除掉了,当然,已经公告强赎的也会被排除。
import requests
URL = 'http://11.11.11.11/api/redeem/'
# DAY 强赎倒数剩余天数小于 DAY (4)天, 已经公告强赎的也是被排除的
DAY = 4
SIGN = '私信星主获取' # sign和以前一致
data = {'day': DAY,
'sign': SIGN}
r = requests.post(URL, data=data)
print(r.json())
具体用户可以关注知识星球: 查看全部
更新:
制作好了一个接口,用户可以直接调用。
数据来源与集思录。
获取 排除满足强赎天数剩余N天的可转债,排除强赎可转债。
比如:DAY=4 ,那么假设强赎满足天数为15天,那么返回市场上强赎强赎倒数天数大于4天的可转债,即返回小于或者等于11天以下的转债。把满足条件还差4天的转债排除掉了,当然,已经公告强赎的也会被排除。
import requests
URL = 'http://11.11.11.11/api/redeem/'
# DAY 强赎倒数剩余天数小于 DAY (4)天, 已经公告强赎的也是被排除的
DAY = 4
SIGN = '私信星主获取' # sign和以前一致
data = {'day': DAY,
'sign': SIGN}
r = requests.post(URL, data=data)
print(r.json())
具体用户可以关注知识星球: 查看全部
占坑,后期把代码整理下放上来。
更新:

制作好了一个接口,用户可以直接调用。
数据来源与集思录。
具体用户可以关注知识星球:

更新:
制作好了一个接口,用户可以直接调用。
数据来源与集思录。
获取 排除满足强赎天数剩余N天的可转债,排除强赎可转债。
比如:DAY=4 ,那么假设强赎满足天数为15天,那么返回市场上强赎强赎倒数天数大于4天的可转债,即返回小于或者等于11天以下的转债。把满足条件还差4天的转债排除掉了,当然,已经公告强赎的也会被排除。
import requests
URL = 'http://11.11.11.11/api/redeem/'
# DAY 强赎倒数剩余天数小于 DAY (4)天, 已经公告强赎的也是被排除的
DAY = 4
SIGN = '私信星主获取' # sign和以前一致
data = {'day': DAY,
'sign': SIGN}
r = requests.post(URL, data=data)
print(r.json())
具体用户可以关注知识星球:
发现numpy一个很坑的问题,要一定级别的高手才能发现问题
李魔佛 发表了文章 • 0 个评论 • 5685 次浏览 • 2019-04-30 00:04
一个二元一次方程:
y=X0**2+X1**2 # **2 是平方def function_2(x):
return x[0]**2+x[1]**2
下面是计算y的偏导数,分布计算X0和X1的偏导def numerical_gradient(f,x):
grad = np.zeros_like(x)
h=1e-4
for idx in range(x.size):
temp_v = x[idx]
x[idx]=temp_v+h
f1=f(x)
print(x,f1)
x[idx]=temp_v-h
f2=f(x)
print(x,f2)
ret = (f1-f2)/(2*h)
print(ret)
x[idx]=temp_v
grad[idx]=ret
return grad
然后调用numerical_gradient(function_2,np.array([3,4]))
计算的是二元一次方程 y=X0**2+X1**2 在点(3,4)的偏导的值
得到的是什么结果?
为什么会得到这样的结果?
小白一般要花点时间才能找到原因。
查看全部
y=X0**2+X1**2 # **2 是平方def function_2(x):
return x[0]**2+x[1]**2
下面是计算y的偏导数,分布计算X0和X1的偏导def numerical_gradient(f,x):
grad = np.zeros_like(x)
h=1e-4
for idx in range(x.size):
temp_v = x[idx]
x[idx]=temp_v+h
f1=f(x)
print(x,f1)
x[idx]=temp_v-h
f2=f(x)
print(x,f2)
ret = (f1-f2)/(2*h)
print(ret)
x[idx]=temp_v
grad[idx]=ret
return grad
然后调用numerical_gradient(function_2,np.array([3,4]))
计算的是二元一次方程 y=X0**2+X1**2 在点(3,4)的偏导的值
得到的是什么结果?
为什么会得到这样的结果?
小白一般要花点时间才能找到原因。
查看全部
一个二元一次方程:
y=X0**2+X1**2 # **2 是平方
下面是计算y的偏导数,分布计算X0和X1的偏导
然后调用
计算的是二元一次方程 y=X0**2+X1**2 在点(3,4)的偏导的值
得到的是什么结果?
为什么会得到这样的结果?
小白一般要花点时间才能找到原因。
y=X0**2+X1**2 # **2 是平方
def function_2(x):
return x[0]**2+x[1]**2
下面是计算y的偏导数,分布计算X0和X1的偏导
def numerical_gradient(f,x):
grad = np.zeros_like(x)
h=1e-4
for idx in range(x.size):
temp_v = x[idx]
x[idx]=temp_v+h
f1=f(x)
print(x,f1)
x[idx]=temp_v-h
f2=f(x)
print(x,f2)
ret = (f1-f2)/(2*h)
print(ret)
x[idx]=temp_v
grad[idx]=ret
return grad
然后调用
numerical_gradient(function_2,np.array([3,4]))计算的是二元一次方程 y=X0**2+X1**2 在点(3,4)的偏导的值
得到的是什么结果?
为什么会得到这样的结果?
小白一般要花点时间才能找到原因。
numpy和dataframe轴的含义,axis为负数的含义
李魔佛 发表了文章 • 0 个评论 • 6744 次浏览 • 2019-04-28 14:22
比如有数组:
a=np.array([[[1,2],[3,4]],[[11,12],[13,14]]])
a
array([[[ 1, 2],
[ 3, 4]],
[[11, 12],
[13, 14]]])
a有3个中括号,那么就有3条轴,从0开始到2,分别是axis=0,1,2
那么我要对a进行求和,分别用axis=0,1,2进行运行。
a.sum(axis=0)得到:
array([[12, 14],
[16, 18]])意思是去掉一个中括号,然后运行。
同理:
a.sum(axis=1)对a去掉2个中括号,然后运行。
得到:
array([[ 4, 6],
[24, 26]])那么对a.sum(axis=2)的结果呢?读者可以自己上机去尝试吧。
而轴的负数,axis=-3和axis=0的意思是一样的,对于有3层轴的数组来说的话。
a.sum(axis=-3)
array([[12, 14],
[16, 18]])
查看全部
a=np.array([[[1,2],[3,4]],[[11,12],[13,14]]])
a
array([[[ 1, 2],
[ 3, 4]],
[[11, 12],
[13, 14]]])
a有3个中括号,那么就有3条轴,从0开始到2,分别是axis=0,1,2
那么我要对a进行求和,分别用axis=0,1,2进行运行。
a.sum(axis=0)得到:
array([[12, 14],
[16, 18]])意思是去掉一个中括号,然后运行。
同理:
a.sum(axis=1)对a去掉2个中括号,然后运行。
得到:
array([[ 4, 6],
[24, 26]])那么对a.sum(axis=2)的结果呢?读者可以自己上机去尝试吧。
而轴的负数,axis=-3和axis=0的意思是一样的,对于有3层轴的数组来说的话。
a.sum(axis=-3)
array([[12, 14],
[16, 18]])
查看全部
比如有数组:
a
a有3个中括号,那么就有3条轴,从0开始到2,分别是axis=0,1,2
那么我要对a进行求和,分别用axis=0,1,2进行运行。
同理:
得到:
而轴的负数,axis=-3和axis=0的意思是一样的,对于有3层轴的数组来说的话。
a=np.array([[[1,2],[3,4]],[[11,12],[13,14]]])
a
array([[[ 1, 2],
[ 3, 4]],
[[11, 12],
[13, 14]]])
a有3个中括号,那么就有3条轴,从0开始到2,分别是axis=0,1,2
那么我要对a进行求和,分别用axis=0,1,2进行运行。
a.sum(axis=0)得到:
array([[12, 14],意思是去掉一个中括号,然后运行。
[16, 18]])
同理:
a.sum(axis=1)对a去掉2个中括号,然后运行。
得到:
array([[ 4, 6],那么对a.sum(axis=2)的结果呢?读者可以自己上机去尝试吧。
[24, 26]])
而轴的负数,axis=-3和axis=0的意思是一样的,对于有3层轴的数组来说的话。
a.sum(axis=-3)
array([[12, 14],
[16, 18]])
【2019-03-16】市场热度预测 - 通过检测某个论坛(集思录)的热度衡量
李魔佛 发表了文章 • 4 个评论 • 5230 次浏览 • 2019-03-16 18:03
很早前就有这个想法,只是最终实践最近才完成,其实并不是很大难度,只是把这个事情早早抛诸脑后。
首先得有数据,有了数据就可以慢慢分析了。
首先是集思录,把数据进行重新采用,按照周采样,然后绘图:
看到这张图后,瞬间也是震惊了,我觉得应该要逃离了。当然不是马上撤离,但是应该时间不会太久,1-2周就应该空仓了。
感觉这个是不错逃顶抄底指标呀。
文章中的数据每周更新,敬请留意。
原创文章
转载请注明出处:
http://30daydo.com/article/428
查看全部
首先得有数据,有了数据就可以慢慢分析了。
首先是集思录,把数据进行重新采用,按照周采样,然后绘图:
看到这张图后,瞬间也是震惊了,我觉得应该要逃离了。当然不是马上撤离,但是应该时间不会太久,1-2周就应该空仓了。
感觉这个是不错逃顶抄底指标呀。
文章中的数据每周更新,敬请留意。
原创文章
转载请注明出处:
http://30daydo.com/article/428
查看全部
很早前就有这个想法,只是最终实践最近才完成,其实并不是很大难度,只是把这个事情早早抛诸脑后。
首先得有数据,有了数据就可以慢慢分析了。
首先是集思录,把数据进行重新采用,按照周采样,然后绘图:

看到这张图后,瞬间也是震惊了,我觉得应该要逃离了。当然不是马上撤离,但是应该时间不会太久,1-2周就应该空仓了。
感觉这个是不错逃顶抄底指标呀。
文章中的数据每周更新,敬请留意。
原创文章
转载请注明出处:
http://30daydo.com/article/428
首先得有数据,有了数据就可以慢慢分析了。
首先是集思录,把数据进行重新采用,按照周采样,然后绘图:
看到这张图后,瞬间也是震惊了,我觉得应该要逃离了。当然不是马上撤离,但是应该时间不会太久,1-2周就应该空仓了。
感觉这个是不错逃顶抄底指标呀。
文章中的数据每周更新,敬请留意。
原创文章
转载请注明出处:
http://30daydo.com/article/428
可转债价格分布堆叠图 绘制 可视化 python+pyecharts
李魔佛 发表了文章 • 0 个评论 • 13165 次浏览 • 2019-01-30 10:59
这一节课带大家学习如何利用可视化,更好的呈现数据。
即使你有很多数据,可是,你无法直观地看到数据的总体趋势。使用可视化的绘图,可以帮助我们看到数据背后看不到的数据。 比如我已经有每一个可转债的价格,评级。数据如下:
点击查看大图
如果我用下面的图形就可以看出规律:
点击查看大图
横坐标是价格,纵坐标是落在该价格的可转债数量,不同颜色代表不同评级的可转债。
可以看到大部分AA-评级(浅橙色)的可转债价格都在100元以下,而AA(浅蓝色)的可转债价格分布较为平均,从90到110都有。而AA+和AAA的一般都在100以上。
那么如何使用代码实现呢?from setting import get_mysql_conn,get_engine
import pandas as pd
import pymongo
from pyecharts import Geo,Style,Map
engine = get_engine('db_stock',local='local')
# 堆叠图
from pyecharts import Bar
df = pd.read_sql('tb_bond_jisilu',con=engine)
result ={}
for name,grades in df.groupby('评级'):
# print(name,grades[['可转债名称','可转债价格']])
for each in grades['可转债价格']:
result.setdefault(name,)
result[name].append(each)
# 确定价格的范围
value = [str(i) for i in range(85,140)]
ret = [0]*len(value)
ret1 = dict(zip(value,ret))
ret_A_add = ret1.copy()
for item in result['A+']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
ret_A_add[k]+=1
retAA_ = ret1.copy()
for item in result['']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
retAA_[k]+=1
retAA = ret1.copy()
for item in result['AA']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
retAA[k]+=1
retAA_add = ret1.copy()
for item in result['AA+']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
retAA_add[k]+=1
retAAA = ret1.copy()
for item in result['AAA']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
retAAA[k]+=1
bar = Bar('可转债价格分布')
bar.add('A+',value,list(ret_A_add.values()),is_stack=True,yaxis_max=11)
bar.add('',value,list(retAA_.values()),is_stack=True,yaxis_max=11)
bar.add('AA',value,list(retAA.values()),is_stack=True,yaxis_max=11)
bar.add('AA+',value,list(retAA_add.values()),is_stack=True,yaxis_max=11)
bar.add('AAA',value,list(retAAA.values()),is_stack=True,yaxis_max=11)
如果没有安装pyecharts,需要用pip安装即可。
原创文章
转载请注明出处:
http://30daydo.com/article/400
查看全部
即使你有很多数据,可是,你无法直观地看到数据的总体趋势。使用可视化的绘图,可以帮助我们看到数据背后看不到的数据。 比如我已经有每一个可转债的价格,评级。数据如下:
点击查看大图
如果我用下面的图形就可以看出规律:
点击查看大图
横坐标是价格,纵坐标是落在该价格的可转债数量,不同颜色代表不同评级的可转债。
可以看到大部分AA-评级(浅橙色)的可转债价格都在100元以下,而AA(浅蓝色)的可转债价格分布较为平均,从90到110都有。而AA+和AAA的一般都在100以上。
那么如何使用代码实现呢?from setting import get_mysql_conn,get_engine
import pandas as pd
import pymongo
from pyecharts import Geo,Style,Map
engine = get_engine('db_stock',local='local')
# 堆叠图
from pyecharts import Bar
df = pd.read_sql('tb_bond_jisilu',con=engine)
result ={}
for name,grades in df.groupby('评级'):
# print(name,grades[['可转债名称','可转债价格']])
for each in grades['可转债价格']:
result.setdefault(name,)
result[name].append(each)
# 确定价格的范围
value = [str(i) for i in range(85,140)]
ret = [0]*len(value)
ret1 = dict(zip(value,ret))
ret_A_add = ret1.copy()
for item in result['A+']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
ret_A_add[k]+=1
retAA_ = ret1.copy()
for item in result['']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
retAA_[k]+=1
retAA = ret1.copy()
for item in result['AA']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
retAA[k]+=1
retAA_add = ret1.copy()
for item in result['AA+']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
retAA_add[k]+=1
retAAA = ret1.copy()
for item in result['AAA']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
retAAA[k]+=1
bar = Bar('可转债价格分布')
bar.add('A+',value,list(ret_A_add.values()),is_stack=True,yaxis_max=11)
bar.add('',value,list(retAA_.values()),is_stack=True,yaxis_max=11)
bar.add('AA',value,list(retAA.values()),is_stack=True,yaxis_max=11)
bar.add('AA+',value,list(retAA_add.values()),is_stack=True,yaxis_max=11)
bar.add('AAA',value,list(retAAA.values()),is_stack=True,yaxis_max=11)
如果没有安装pyecharts,需要用pip安装即可。
原创文章
转载请注明出处:
http://30daydo.com/article/400
查看全部
这一节课带大家学习如何利用可视化,更好的呈现数据。
即使你有很多数据,可是,你无法直观地看到数据的总体趋势。使用可视化的绘图,可以帮助我们看到数据背后看不到的数据。 比如我已经有每一个可转债的价格,评级。数据如下:

点击查看大图
如果我用下面的图形就可以看出规律:

点击查看大图
横坐标是价格,纵坐标是落在该价格的可转债数量,不同颜色代表不同评级的可转债。
可以看到大部分AA-评级(浅橙色)的可转债价格都在100元以下,而AA(浅蓝色)的可转债价格分布较为平均,从90到110都有。而AA+和AAA的一般都在100以上。
那么如何使用代码实现呢?
如果没有安装pyecharts,需要用pip安装即可。
原创文章
转载请注明出处:
http://30daydo.com/article/400
即使你有很多数据,可是,你无法直观地看到数据的总体趋势。使用可视化的绘图,可以帮助我们看到数据背后看不到的数据。 比如我已经有每一个可转债的价格,评级。数据如下:
点击查看大图
如果我用下面的图形就可以看出规律:
点击查看大图
横坐标是价格,纵坐标是落在该价格的可转债数量,不同颜色代表不同评级的可转债。
可以看到大部分AA-评级(浅橙色)的可转债价格都在100元以下,而AA(浅蓝色)的可转债价格分布较为平均,从90到110都有。而AA+和AAA的一般都在100以上。
那么如何使用代码实现呢?
from setting import get_mysql_conn,get_engine
import pandas as pd
import pymongo
from pyecharts import Geo,Style,Map
engine = get_engine('db_stock',local='local')
# 堆叠图
from pyecharts import Bar
df = pd.read_sql('tb_bond_jisilu',con=engine)
result ={}
for name,grades in df.groupby('评级'):
# print(name,grades[['可转债名称','可转债价格']])
for each in grades['可转债价格']:
result.setdefault(name,)
result[name].append(each)
# 确定价格的范围
value = [str(i) for i in range(85,140)]
ret = [0]*len(value)
ret1 = dict(zip(value,ret))
ret_A_add = ret1.copy()
for item in result['A+']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
ret_A_add[k]+=1
retAA_ = ret1.copy()
for item in result['']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
retAA_[k]+=1
retAA = ret1.copy()
for item in result['AA']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
retAA[k]+=1
retAA_add = ret1.copy()
for item in result['AA+']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
retAA_add[k]+=1
retAAA = ret1.copy()
for item in result['AAA']:
for k in ret1:
if float(k)+0.5>item and float(k)-0.5<=item:
retAAA[k]+=1
bar = Bar('可转债价格分布')
bar.add('A+',value,list(ret_A_add.values()),is_stack=True,yaxis_max=11)
bar.add('',value,list(retAA_.values()),is_stack=True,yaxis_max=11)
bar.add('AA',value,list(retAA.values()),is_stack=True,yaxis_max=11)
bar.add('AA+',value,list(retAA_add.values()),is_stack=True,yaxis_max=11)
bar.add('AAA',value,list(retAAA.values()),is_stack=True,yaxis_max=11)
如果没有安装pyecharts,需要用pip安装即可。
原创文章
转载请注明出处:
http://30daydo.com/article/400
可转债套利【一】 python找出折价可转债个股
李魔佛 发表了文章 • 9 个评论 • 25901 次浏览 • 2018-03-16 17:17
关于可转债的定义,可以到https://xueqiu.com/6832369826/103042836 这里科普一下。
下面的内容默认你对可转债已经有一定的了解。
可转债的价值=正股价格/转股价格 + 利息,忽略可转债的利息,直接用公式 可转债的价值=正股价格/转股价格 计算可转债的价值。
如果当前可转债的交易价格(在交易软件上显示的价格)如:
所以万信转债的价格是121.5元,然后万信转债的价值呢? 按照上面的公式,万信转债的正股是万达信息,今天万达信息 (2018-03-16)的股价是
以收盘价为例,17.25。
而万信转债的股转价格呢? 这个可以到万信转债F10页面的公告中找到,为13.11元。 所以万信转债的价值是
17.25/13.11 = 1.315 , 可转债单位是100, 所以万信转债的内在价值是1.315*100=131.5, 而当前的交易价格为 121.5
也就是你用121.5元买到一个价值 131.5的商品, 所以相当于打折买到了一个超值的商品,所以当前的万信转债是折价状态。
所以本次任务就是要找出可交易的可转债中折价状态的可转债。
然后直接上干货。上python代码。#-*-coding=utf-8
'''
可转债监控
'''
import tushare as ts
from setting import get_engine
engine = get_engine('db_bond')
import pandas as pd
import datetime
class ConvertBond():
def __init__(self):
self.conn=ts.get_apis()
self.allBonds=ts.new_cbonds(pause=2)
self.onSellBond=self.allBonds.dropna(subset=['marketprice'])
self.today=datetime.datetime.now().strftime('%Y-%m-%d %H:%M')
def stockPrice(self,code):
stock_df = ts.get_realtime_quotes(code)
price = float(stock_df['price'].values[0])
return price
def dataframe(self):
price_list=
for code in self.onSellBond['scode']:
price_list.append(self.stockPrice(code))
self.onSellBond['stock_price']=price_list
self.onSellBond['ratio'] = (
self.onSellBond['marketprice']
/(self.onSellBond['stock_price'] / self.onSellBond['convprice'])-1)*100
self.onSellBond['Updated']=self.today
self.onSellBond.to_sql('tb_bond',engine,if_exists='replace')
def closed(self):
ts.close_apis(self.conn)
def main():
bond=ConvertBond()
bond.dataframe()
bond.closed()
if __name__=='__main__':
main()
上面的setting库,把下面的*** 替换成你自己的Mysql用户和密码即可。import os
import MySQLdb
MYSQL_USER = *********
MYSQL_PASSWORD = ********
MYSQL_HOST = *********
MYSQL_PORT = *****
def get_engine(db):
engine = create_engine('mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8'.format(MYSQL_USER, MYSQL_PASSWORD, MYSQL_HOST, MYSQL_PORT, db))
return engine
上面的少于100行的代码就能够满足你的要求。
运行后会把结果保存在MySQL 数据库。如下图所示:
点击放大
2018-03-16 可转债表格
其中折价率是ratio列。按照ratio列进行排列,只有2个是正,也就是当前市场是只有2只可转债是处于折价状态的,其余的都是溢价状态(价格比内在价值要贵,忽略利息的前提下,如果把4~5%的利息也算进去的话,-3~4%的折价率其实也算小折价吧)
目前万信转债折价10个点,宝信转债折价5.8个点。 所以适合低风险投资者建仓。 因为可转债有兜底价格,所以出现亏损的概率很低(除非遇到黑天鹅,公司破产了,像遇到乐视这种PPT独角兽公司,欠债不还的。 但是A股上能够有资格发行可转债的,本身对公司的盈利,分红都有硬性要求)。
所以可以保存上面的代码,可以每天运行一次,可以很方便地找出折价的个股,当然也可以在盘中一直监测,因为可转债的价格是实时变化的,一旦遇到大跌,跌到折价状态,你也可以择时入手标的。
原文链接:
http://30daydo.com/article/286
转载请注明出处
可转债低费率,沪市百万分之二,深圳十万分之四,免五 开户
加微信开通
查看全部
下面的内容默认你对可转债已经有一定的了解。
可转债的价值=正股价格/转股价格 + 利息,忽略可转债的利息,直接用公式 可转债的价值=正股价格/转股价格 计算可转债的价值。
如果当前可转债的交易价格(在交易软件上显示的价格)如:
所以万信转债的价格是121.5元,然后万信转债的价值呢? 按照上面的公式,万信转债的正股是万达信息,今天万达信息 (2018-03-16)的股价是
以收盘价为例,17.25。
而万信转债的股转价格呢? 这个可以到万信转债F10页面的公告中找到,为13.11元。 所以万信转债的价值是
17.25/13.11 = 1.315 , 可转债单位是100, 所以万信转债的内在价值是1.315*100=131.5, 而当前的交易价格为 121.5
也就是你用121.5元买到一个价值 131.5的商品, 所以相当于打折买到了一个超值的商品,所以当前的万信转债是折价状态。
所以本次任务就是要找出可交易的可转债中折价状态的可转债。
然后直接上干货。上python代码。#-*-coding=utf-8
'''
可转债监控
'''
import tushare as ts
from setting import get_engine
engine = get_engine('db_bond')
import pandas as pd
import datetime
class ConvertBond():
def __init__(self):
self.conn=ts.get_apis()
self.allBonds=ts.new_cbonds(pause=2)
self.onSellBond=self.allBonds.dropna(subset=['marketprice'])
self.today=datetime.datetime.now().strftime('%Y-%m-%d %H:%M')
def stockPrice(self,code):
stock_df = ts.get_realtime_quotes(code)
price = float(stock_df['price'].values[0])
return price
def dataframe(self):
price_list=
for code in self.onSellBond['scode']:
price_list.append(self.stockPrice(code))
self.onSellBond['stock_price']=price_list
self.onSellBond['ratio'] = (
self.onSellBond['marketprice']
/(self.onSellBond['stock_price'] / self.onSellBond['convprice'])-1)*100
self.onSellBond['Updated']=self.today
self.onSellBond.to_sql('tb_bond',engine,if_exists='replace')
def closed(self):
ts.close_apis(self.conn)
def main():
bond=ConvertBond()
bond.dataframe()
bond.closed()
if __name__=='__main__':
main()
上面的setting库,把下面的*** 替换成你自己的Mysql用户和密码即可。import os
import MySQLdb
MYSQL_USER = *********
MYSQL_PASSWORD = ********
MYSQL_HOST = *********
MYSQL_PORT = *****
def get_engine(db):
engine = create_engine('mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8'.format(MYSQL_USER, MYSQL_PASSWORD, MYSQL_HOST, MYSQL_PORT, db))
return engine
上面的少于100行的代码就能够满足你的要求。
运行后会把结果保存在MySQL 数据库。如下图所示:
点击放大
2018-03-16 可转债表格
其中折价率是ratio列。按照ratio列进行排列,只有2个是正,也就是当前市场是只有2只可转债是处于折价状态的,其余的都是溢价状态(价格比内在价值要贵,忽略利息的前提下,如果把4~5%的利息也算进去的话,-3~4%的折价率其实也算小折价吧)
目前万信转债折价10个点,宝信转债折价5.8个点。 所以适合低风险投资者建仓。 因为可转债有兜底价格,所以出现亏损的概率很低(除非遇到黑天鹅,公司破产了,像遇到乐视这种PPT独角兽公司,欠债不还的。 但是A股上能够有资格发行可转债的,本身对公司的盈利,分红都有硬性要求)。
所以可以保存上面的代码,可以每天运行一次,可以很方便地找出折价的个股,当然也可以在盘中一直监测,因为可转债的价格是实时变化的,一旦遇到大跌,跌到折价状态,你也可以择时入手标的。
原文链接:
http://30daydo.com/article/286
转载请注明出处
可转债低费率,沪市百万分之二,深圳十万分之四,免五 开户
加微信开通
查看全部
关于可转债的定义,可以到https://xueqiu.com/6832369826/103042836 这里科普一下。
下面的内容默认你对可转债已经有一定的了解。
可转债的价值=正股价格/转股价格 + 利息,忽略可转债的利息,直接用公式 可转债的价值=正股价格/转股价格 计算可转债的价值。
如果当前可转债的交易价格(在交易软件上显示的价格)如:

所以万信转债的价格是121.5元,然后万信转债的价值呢? 按照上面的公式,万信转债的正股是万达信息,今天万达信息 (2018-03-16)的股价是

以收盘价为例,17.25。
而万信转债的股转价格呢? 这个可以到万信转债F10页面的公告中找到,为13.11元。 所以万信转债的价值是
17.25/13.11 = 1.315 , 可转债单位是100, 所以万信转债的内在价值是1.315*100=131.5, 而当前的交易价格为 121.5
也就是你用121.5元买到一个价值 131.5的商品, 所以相当于打折买到了一个超值的商品,所以当前的万信转债是折价状态。
所以本次任务就是要找出可交易的可转债中折价状态的可转债。
然后直接上干货。上python代码。
上面的setting库,把下面的*** 替换成你自己的Mysql用户和密码即可。
上面的少于100行的代码就能够满足你的要求。
运行后会把结果保存在MySQL 数据库。如下图所示:

点击放大
2018-03-16 可转债表格
其中折价率是ratio列。按照ratio列进行排列,只有2个是正,也就是当前市场是只有2只可转债是处于折价状态的,其余的都是溢价状态(价格比内在价值要贵,忽略利息的前提下,如果把4~5%的利息也算进去的话,-3~4%的折价率其实也算小折价吧)
目前万信转债折价10个点,宝信转债折价5.8个点。 所以适合低风险投资者建仓。 因为可转债有兜底价格,所以出现亏损的概率很低(除非遇到黑天鹅,公司破产了,像遇到乐视这种PPT独角兽公司,欠债不还的。 但是A股上能够有资格发行可转债的,本身对公司的盈利,分红都有硬性要求)。
所以可以保存上面的代码,可以每天运行一次,可以很方便地找出折价的个股,当然也可以在盘中一直监测,因为可转债的价格是实时变化的,一旦遇到大跌,跌到折价状态,你也可以择时入手标的。
原文链接:
http://30daydo.com/article/286
转载请注明出处
可转债低费率,沪市百万分之二,深圳十万分之四,免五 开户
加微信开通

下面的内容默认你对可转债已经有一定的了解。
可转债的价值=正股价格/转股价格 + 利息,忽略可转债的利息,直接用公式 可转债的价值=正股价格/转股价格 计算可转债的价值。
如果当前可转债的交易价格(在交易软件上显示的价格)如:
所以万信转债的价格是121.5元,然后万信转债的价值呢? 按照上面的公式,万信转债的正股是万达信息,今天万达信息 (2018-03-16)的股价是
以收盘价为例,17.25。
而万信转债的股转价格呢? 这个可以到万信转债F10页面的公告中找到,为13.11元。 所以万信转债的价值是
17.25/13.11 = 1.315 , 可转债单位是100, 所以万信转债的内在价值是1.315*100=131.5, 而当前的交易价格为 121.5
也就是你用121.5元买到一个价值 131.5的商品, 所以相当于打折买到了一个超值的商品,所以当前的万信转债是折价状态。
所以本次任务就是要找出可交易的可转债中折价状态的可转债。
然后直接上干货。上python代码。
#-*-coding=utf-8
'''
可转债监控
'''
import tushare as ts
from setting import get_engine
engine = get_engine('db_bond')
import pandas as pd
import datetime
class ConvertBond():
def __init__(self):
self.conn=ts.get_apis()
self.allBonds=ts.new_cbonds(pause=2)
self.onSellBond=self.allBonds.dropna(subset=['marketprice'])
self.today=datetime.datetime.now().strftime('%Y-%m-%d %H:%M')
def stockPrice(self,code):
stock_df = ts.get_realtime_quotes(code)
price = float(stock_df['price'].values[0])
return price
def dataframe(self):
price_list=
for code in self.onSellBond['scode']:
price_list.append(self.stockPrice(code))
self.onSellBond['stock_price']=price_list
self.onSellBond['ratio'] = (
self.onSellBond['marketprice']
/(self.onSellBond['stock_price'] / self.onSellBond['convprice'])-1)*100
self.onSellBond['Updated']=self.today
self.onSellBond.to_sql('tb_bond',engine,if_exists='replace')
def closed(self):
ts.close_apis(self.conn)
def main():
bond=ConvertBond()
bond.dataframe()
bond.closed()
if __name__=='__main__':
main()
上面的setting库,把下面的*** 替换成你自己的Mysql用户和密码即可。
import os
import MySQLdb
MYSQL_USER = *********
MYSQL_PASSWORD = ********
MYSQL_HOST = *********
MYSQL_PORT = *****
def get_engine(db):
engine = create_engine('mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8'.format(MYSQL_USER, MYSQL_PASSWORD, MYSQL_HOST, MYSQL_PORT, db))
return engine
上面的少于100行的代码就能够满足你的要求。
运行后会把结果保存在MySQL 数据库。如下图所示:
点击放大
2018-03-16 可转债表格
其中折价率是ratio列。按照ratio列进行排列,只有2个是正,也就是当前市场是只有2只可转债是处于折价状态的,其余的都是溢价状态(价格比内在价值要贵,忽略利息的前提下,如果把4~5%的利息也算进去的话,-3~4%的折价率其实也算小折价吧)
目前万信转债折价10个点,宝信转债折价5.8个点。 所以适合低风险投资者建仓。 因为可转债有兜底价格,所以出现亏损的概率很低(除非遇到黑天鹅,公司破产了,像遇到乐视这种PPT独角兽公司,欠债不还的。 但是A股上能够有资格发行可转债的,本身对公司的盈利,分红都有硬性要求)。
所以可以保存上面的代码,可以每天运行一次,可以很方便地找出折价的个股,当然也可以在盘中一直监测,因为可转债的价格是实时变化的,一旦遇到大跌,跌到折价状态,你也可以择时入手标的。
原文链接:
http://30daydo.com/article/286
转载请注明出处
可转债低费率,沪市百万分之二,深圳十万分之四,免五 开户
加微信开通
dataframe reindex和reset_index区别
李魔佛 发表了文章 • 0 个评论 • 90347 次浏览 • 2017-12-30 15:58
reset_index的作用是重新设置dataframe的index,范围为0~len(df)。 df = pd.DataFrame({'A': [1, 2, 3, 4, 5], 'B': [10, 20, 30, 40, 50]})
df2 = pd.DataFrame({'A': [6], 'B': [60]})
print('df', df)
print('df2', df2)
df_x = [df, df2]
result = pd.concat(df_x)
print('first result ', result)
上面代码把df和df2合并为一个result,但是result的index是乱的。
那么执行result2= result.reset_index()
得到如下的result2: (默认只是返回一个copy,原来的result没有发生改变,所以需要副本赋值给result2)
可以看到,原来的一列index现在变成了columns之一,新的index为[0,1,2,3,4,5]
如果添加参数 reset_index(drop=True) 那么原index会被丢弃,不会显示为一个新列。result2 = result.reset_index(drop=True)
reindex的作用是按照原有的列进行重新生成一个新的df。
还是使用上面的代码
result目前是df和df2的合并序列。
如下:
可以看到index为[0,1,2,3,4,0]
执行 result3 = result.reindex(columns=['A','C'])
可以看到,原index并没有发生改变,而列变成了A和C,因为C是不存在的,所以使用了NaB填充,这个值的内容可以自己填充,可以改为默认填充0或者任意你想要的数据。reindex(columns=..)的作用类似于重新把列的顺序整理一遍, 而使用reindex(index=....) 则按照行重新整理一遍。
原文链接:http://30daydo.com/article/257
欢迎转载,注明出处
查看全部
df2 = pd.DataFrame({'A': [6], 'B': [60]})
print('df', df)
print('df2', df2)
df_x = [df, df2]
result = pd.concat(df_x)
print('first result ', result)
上面代码把df和df2合并为一个result,但是result的index是乱的。
那么执行result2= result.reset_index()
得到如下的result2: (默认只是返回一个copy,原来的result没有发生改变,所以需要副本赋值给result2)
可以看到,原来的一列index现在变成了columns之一,新的index为[0,1,2,3,4,5]
如果添加参数 reset_index(drop=True) 那么原index会被丢弃,不会显示为一个新列。result2 = result.reset_index(drop=True)
reindex的作用是按照原有的列进行重新生成一个新的df。
还是使用上面的代码
result目前是df和df2的合并序列。
如下:
可以看到index为[0,1,2,3,4,0]
执行 result3 = result.reindex(columns=['A','C'])
可以看到,原index并没有发生改变,而列变成了A和C,因为C是不存在的,所以使用了NaB填充,这个值的内容可以自己填充,可以改为默认填充0或者任意你想要的数据。reindex(columns=..)的作用类似于重新把列的顺序整理一遍, 而使用reindex(index=....) 则按照行重新整理一遍。
原文链接:http://30daydo.com/article/257
欢迎转载,注明出处
查看全部
reset_index的作用是重新设置dataframe的index,范围为0~len(df)。
上面代码把df和df2合并为一个result,但是result的index是乱的。

那么执行
得到如下的result2: (默认只是返回一个copy,原来的result没有发生改变,所以需要副本赋值给result2)

可以看到,原来的一列index现在变成了columns之一,新的index为[0,1,2,3,4,5]
如果添加参数 reset_index(drop=True) 那么原index会被丢弃,不会显示为一个新列。

reindex的作用是按照原有的列进行重新生成一个新的df。
还是使用上面的代码
result目前是df和df2的合并序列。
如下:

可以看到index为[0,1,2,3,4,0]
执行

可以看到,原index并没有发生改变,而列变成了A和C,因为C是不存在的,所以使用了NaB填充,这个值的内容可以自己填充,可以改为默认填充0或者任意你想要的数据。reindex(columns=..)的作用类似于重新把列的顺序整理一遍, 而使用reindex(index=....) 则按照行重新整理一遍。
原文链接:http://30daydo.com/article/257
欢迎转载,注明出处
df = pd.DataFrame({'A': [1, 2, 3, 4, 5], 'B': [10, 20, 30, 40, 50]})
df2 = pd.DataFrame({'A': [6], 'B': [60]})
print('df', df)
print('df2', df2)
df_x = [df, df2]
result = pd.concat(df_x)
print('first result ', result) 上面代码把df和df2合并为一个result,但是result的index是乱的。
那么执行
result2= result.reset_index()
得到如下的result2: (默认只是返回一个copy,原来的result没有发生改变,所以需要副本赋值给result2)
可以看到,原来的一列index现在变成了columns之一,新的index为[0,1,2,3,4,5]
如果添加参数 reset_index(drop=True) 那么原index会被丢弃,不会显示为一个新列。
result2 = result.reset_index(drop=True)
reindex的作用是按照原有的列进行重新生成一个新的df。
还是使用上面的代码
result目前是df和df2的合并序列。
如下:
可以看到index为[0,1,2,3,4,0]
执行
result3 = result.reindex(columns=['A','C'])
可以看到,原index并没有发生改变,而列变成了A和C,因为C是不存在的,所以使用了NaB填充,这个值的内容可以自己填充,可以改为默认填充0或者任意你想要的数据。reindex(columns=..)的作用类似于重新把列的顺序整理一遍, 而使用reindex(index=....) 则按照行重新整理一遍。
原文链接:http://30daydo.com/article/257
欢迎转载,注明出处