
通知设置 新通知
QMT股票两融对冲建仓实盘
QMT • 李魔佛 发表了文章 • 0 个评论 • 3211 次浏览 • 2024-05-29 12:02
成交了多少量,就融券多少量。达到指标即可停止。
代写量化程序,可以关注公众号,后台联系。 价格比QMT官网低的多了。实战性选手,选过N多QMT,ptrade实盘代码。
查看全部

成交了多少量,就融券多少量。达到指标即可停止。
代写量化程序,可以关注公众号,后台联系。 价格比QMT官网低的多了。实战性选手,选过N多QMT,ptrade实盘代码。

QMT实时获取涨停股,筛选流通盘大于X的股票
QMT • 李魔佛 发表了文章 • 0 个评论 • 4664 次浏览 • 2024-02-07 18:28
直接上代码:# coding:gbk
import time
class G():
pass
g = G()
def init(ContextInfo):
g.hsa = [item for item in ContextInfo.get_stock_list_in_sector('沪深A股') if not item.endswith('BJ')]
g.vol_dict = {}
for stock in g.hsa:
g.vol_dict[stock] = ContextInfo.get_last_volume(stock)
ContextInfo.run_time("execution", "1nSecond", "2019-10-14 13:20:00")
def execution(ContextInfo):
t0 = time.time()
full_tick = ContextInfo.get_full_tick(g.hsa)
total_market_value = 0
total_ratio = 0
count = 0
for stock in g.hsa:
if full_tick[stock]['lastClose'] == 0:
continue
ratio = full_tick[stock]['lastPrice'] / full_tick[stock]['lastClose'] - 1
rise_price = round(full_tick[stock]['lastClose'] * 1.2, 2) if stock[0] == '3' or stock[:3] == '688' else round(
full_tick[stock]['lastClose'] * 1.1, 2)
# 如果要打印涨停品种
if abs(full_tick[stock]['lastPrice'] - rise_price) <0.01:
print(f"涨停股票 {stock} {ContextInfo.get_stock_name(stock)}")
market_value = full_tick[stock]['lastPrice'] * g.vol_dict[stock]
total_ratio += ratio * market_value
total_market_value += market_value
count += 1
# print(count)
total_ratio /= total_market_value
total_ratio *= 100
print(f'A股加权涨幅 {round(total_ratio, 2)}% 函数运行耗时{round(time.time() - t0, 5)}秒')
欢迎关注公众号:
可转债量化分析 查看全部
直接上代码:
# coding:gbk
import time
class G():
pass
g = G()
def init(ContextInfo):
g.hsa = [item for item in ContextInfo.get_stock_list_in_sector('沪深A股') if not item.endswith('BJ')]
g.vol_dict = {}
for stock in g.hsa:
g.vol_dict[stock] = ContextInfo.get_last_volume(stock)
ContextInfo.run_time("execution", "1nSecond", "2019-10-14 13:20:00")
def execution(ContextInfo):
t0 = time.time()
full_tick = ContextInfo.get_full_tick(g.hsa)
total_market_value = 0
total_ratio = 0
count = 0
for stock in g.hsa:
if full_tick[stock]['lastClose'] == 0:
continue
ratio = full_tick[stock]['lastPrice'] / full_tick[stock]['lastClose'] - 1
rise_price = round(full_tick[stock]['lastClose'] * 1.2, 2) if stock[0] == '3' or stock[:3] == '688' else round(
full_tick[stock]['lastClose'] * 1.1, 2)
# 如果要打印涨停品种
if abs(full_tick[stock]['lastPrice'] - rise_price) <0.01:
print(f"涨停股票 {stock} {ContextInfo.get_stock_name(stock)}")
market_value = full_tick[stock]['lastPrice'] * g.vol_dict[stock]
total_ratio += ratio * market_value
total_market_value += market_value
count += 1
# print(count)
total_ratio /= total_market_value
total_ratio *= 100
print(f'A股加权涨幅 {round(total_ratio, 2)}% 函数运行耗时{round(time.time() - t0, 5)}秒')

欢迎关注公众号:
可转债量化分析
QMT | Ptrade 量化策略代写服务
量化交易 • 李魔佛 发表了文章 • 0 个评论 • 5030 次浏览 • 2023-11-01 10:43
多年交易经验,量化交易与开发经验。所以很多策略,其实用户大体描述,就知道要注意哪些地方,会提出一些建议,用户要注意,需不需要添加一些判读条件等等。(当然,策略的具体参数都是设置可以调节的,你不需要把实际的参数告诉我,代码给你后,你自己运行策略的时候把你策略的真正参数填上去就好了。)
有偿,收费,价格美丽。根据策略实际的复杂程度与预估的工时,收费。(不根据代码数量,因为我写代码很精简)
我也帮你们咨询过了迅投的客服。 因为他们官网也有提供策略代写服务。他们是不问你策略,直接是5000起步哦。然后根据策略,在5000的基础上不断加。
咨询完,我都感觉我自己以前的报价太低了,呜。
PS: 之前还有迅投的前员工私底下接单写策略,然后到我的星球里面白嫖我的代码,调用我接口数据,被我发现后举报到星球的。后面那个客户发现代码里面藏有我的公众号信息哈,找到我让我修改接口数据哈。
需要的代写策略的盆友,可以关注公众号,在菜单栏那里的“代写量化程序”或者 后台回复:策略代写,获取联系方式哦
扫码关注公众号:
查看全部

迅投的QMT和恒生电子的Ptrade, 还有掘金, 量化策略编程, 实盘和回测都行。只要你的需求明确,白纸黑字描述清楚,都可以做。股票,ETF,可转债都行。
多年交易经验,量化交易与开发经验。所以很多策略,其实用户大体描述,就知道要注意哪些地方,会提出一些建议,用户要注意,需不需要添加一些判读条件等等。(当然,策略的具体参数都是设置可以调节的,你不需要把实际的参数告诉我,代码给你后,你自己运行策略的时候把你策略的真正参数填上去就好了。)
有偿,收费,价格美丽。根据策略实际的复杂程度与预估的工时,收费。(不根据代码数量,因为我写代码很精简)
我也帮你们咨询过了迅投的客服。 因为他们官网也有提供策略代写服务。他们是不问你策略,直接是5000起步哦。然后根据策略,在5000的基础上不断加。


咨询完,我都感觉我自己以前的报价太低了,呜。
PS: 之前还有迅投的前员工私底下接单写策略,然后到我的星球里面白嫖我的代码,调用我接口数据,被我发现后举报到星球的。后面那个客户发现代码里面藏有我的公众号信息哈,找到我让我修改接口数据哈。
需要的代写策略的盆友,可以关注公众号,在菜单栏那里的“代写量化程序”或者 后台回复:策略代写,获取联系方式哦
扫码关注公众号:
小市值轮动-量化交易-程序化交易-Ptrade实盘
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 4824 次浏览 • 2023-10-07 14:14
当前策略持有30只。
点击查看大图
点击查看大图
基于股票的策略不敢多买,属于试验阶段,后期仍然会不断根据市场调仓; 主仓依然在可转债。
公众号:可转债量化分析
如果需要策略代写,(ptrade、qmt,其他量化平台)
可以公众号后台回复:
策略代写
查看全部
当前策略持有30只。


基于股票的策略不敢多买,属于试验阶段,后期仍然会不断根据市场调仓; 主仓依然在可转债。
公众号:可转债量化分析
如果需要策略代写,(ptrade、qmt,其他量化平台)
可以公众号后台回复:
策略代写
ptrade qmt无法登录问题
量化交易 • 李魔佛 发表了文章 • 0 个评论 • 4672 次浏览 • 2023-08-08 14:44
实际上这是在周五晚上和周末出现的问题,这是计划内的维护。部分券商没有技术服务支持,用户可能连服务器日常维护服务通知都无法及时得到通知。
PS:其实,大部分券商基本也就那样,ptrade和qmt的技术支持基本等于0,不敢说全部,至少90%的情况是这样的。 以至于我自己维护了一个ptrade,qmt的技术群(审核才可以加),日常有空就在里面解决群友的问题。基本都是些基础问题,部分可能是券商数据问题,大部分是用户的代码问题。 查看全部


实际上这是在周五晚上和周末出现的问题,这是计划内的维护。部分券商没有技术服务支持,用户可能连服务器日常维护服务通知都无法及时得到通知。
PS:其实,大部分券商基本也就那样,ptrade和qmt的技术支持基本等于0,不敢说全部,至少90%的情况是这样的。 以至于我自己维护了一个ptrade,qmt的技术群(审核才可以加),日常有空就在里面解决群友的问题。基本都是些基础问题,部分可能是券商数据问题,大部分是用户的代码问题。
ptrade批量获取股票的昨天的收盘价,转为字典json【一】
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 5137 次浏览 • 2023-07-17 19:50
ptrade接口文档:https://ptradeapi.com
笔者这里接写几个最简单的方式,供读者朋友参考。
下面代码适用于实盘,回测。
code_list = ['113578.SS','123014.SZ'] # 股票池,这里可以填几千个股票也没问题的
zz_df_price = get_price(code_list, start_date=None, end_date=None, frequency='1d', fields='close', fq=None, count=1)
yesterday_price_dict = zz_df_price.iloc[0].to_json()
讲解:
1.
code_list = ['113578.SS','123014.SZ'] # 股票池,这里可以填几千个股票也没问题的,比如你可以先拿沪深300指数的成分股,然后传入这个函数。
2.
zz_df_price = get_price(code_list, start_date=None, end_date=None, frequency='1d', fields='close', fq=None, count=1)
get_price: 获取历史数据。 这里不用get_history,因为这个函数太多bug了,主要是券商数据可能是缺的。拿历史数据我基本不敢用get_history。
因为我拿昨天的收盘价,所以我就不指定日期,只用count=1,获取1条数据,因为数据是从最新开始的,那么这一条数据肯定是上一个交易日的。
正常情况返回的数据是一个Pannel,三维的。不过因为filed=‘close',单个字段,特殊情况,这里返回的是一个dataframe
输出:
zz_df_price.iloc[0].to_json()
index 113578.SS 123014.SZ
2023-07-14 93.036 118.36
所以接下来要做的是,获取dataframe的第一行数据,直接转为json
得到:
'{"113578.SS":93.036,"123014.SZ":118.36}'
更多技术支持与解答,欢迎加入星球。
查看全部
ptrade接口文档:https://ptradeapi.com
笔者这里接写几个最简单的方式,供读者朋友参考。
下面代码适用于实盘,回测。
code_list = ['113578.SS','123014.SZ'] # 股票池,这里可以填几千个股票也没问题的
zz_df_price = get_price(code_list, start_date=None, end_date=None, frequency='1d', fields='close', fq=None, count=1)
yesterday_price_dict = zz_df_price.iloc[0].to_json()
讲解:
1.
code_list = ['113578.SS','123014.SZ'] # 股票池,这里可以填几千个股票也没问题的,比如你可以先拿沪深300指数的成分股,然后传入这个函数。
2.
zz_df_price = get_price(code_list, start_date=None, end_date=None, frequency='1d', fields='close', fq=None, count=1)
get_price: 获取历史数据。 这里不用get_history,因为这个函数太多bug了,主要是券商数据可能是缺的。拿历史数据我基本不敢用get_history。
因为我拿昨天的收盘价,所以我就不指定日期,只用count=1,获取1条数据,因为数据是从最新开始的,那么这一条数据肯定是上一个交易日的。
正常情况返回的数据是一个Pannel,三维的。不过因为filed=‘close',单个字段,特殊情况,这里返回的是一个dataframe

输出:
zz_df_price.iloc[0].to_json()
index 113578.SS 123014.SZ
2023-07-14 93.036 118.36
所以接下来要做的是,获取dataframe的第一行数据,直接转为json
得到:
'{"113578.SS":93.036,"123014.SZ":118.36}'
更多技术支持与解答,欢迎加入星球。

目前支持量化接口的万一免五的券商有哪些?
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 7765 次浏览 • 2023-07-04 22:52
其中能够股票免五的有国金证券,国盛证券,国信证券,安信证券。
其中,国金证券,国盛证券支持QMT、MiniQMT、Ptrade。
国信证券,安信证券支持QMT。
东莞证券支持Ptrade
可转债默认免五。
开户后可加入量化技术交流群,可获得编程技术指导。
【提问者需要把问题描述清楚即可,PS: 有些人动不动就说:“Ptrade不行呀”,“QMT垃圾呀”,结果让他贴代码上来瞅瞅,是他本身代码写的拉垮,目前贴出来的已知的问题,90%是个人代码问题。】
扫码添加微信咨询开户:
查看全部

其中能够股票免五的有国金证券,国盛证券,国信证券,安信证券。
其中,国金证券,国盛证券支持QMT、MiniQMT、Ptrade。
国信证券,安信证券支持QMT。
东莞证券支持Ptrade
可转债默认免五。

开户后可加入量化技术交流群,可获得编程技术指导。
【提问者需要把问题描述清楚即可,PS: 有些人动不动就说:“Ptrade不行呀”,“QMT垃圾呀”,结果让他贴代码上来瞅瞅,是他本身代码写的拉垮,目前贴出来的已知的问题,90%是个人代码问题。】
扫码添加微信咨询开户:

Ptrade/QMT 可转债转股操作 python代码
量化交易 • 李魔佛 发表了文章 • 0 个评论 • 5181 次浏览 • 2023-06-19 18:14
而这个转股操作是要在交易时间,也就是盘中时间下一个债转股的命令,然后盘后交易所会更会你盘中下的转股指令,将对应的可转债转为对应的股票,这是,持仓里面的可转债会消失,变成该可转债对应的正股。
(当然这是在全部转股的前提下的情况,也有可能有部分人转债只转一部分,这样持仓里面还仍然会有部分可转债没有被转为股票)
那么在Ptrade和QMT里面,如何调用API接口进行可转债转股呢?
Ptrade:
def initialize(context):
g.security = "600570.SS"
set_universe(g.security)
def before_trading_start(context, data):
g.count = 0
def handle_data(context, data):
if g.count == 0:
# 对持仓内的贝斯进行转股操作
debt_to_stock_order("123075.SZ", -1000)
g.count += 1
# 查看委托状态
log.info(get_orders())
g.count += 1
主要是上面的函数,
debt_to_stock_order 传入可转债代码和转股的数量,注意数量用加一个负号。
QMT可转债转股操作
#coding:gbk
c = True
account = '11111111' # 个人账户
def init(ContextInfo):
pass
def handlebar(ContextInfo):
if not ContextInfo.is_last_bar():
#历史k线不应该发出实盘信号 跳过
return
if c:
passorder(80,1101,account,s,5,0,-100,'1',2,'tzbz',ContextInfo)
c=False
passorder 里面的 80是 普通账户可转债转股
更多Ptrade,qmt知识,可以关注公众号
查看全部
而这个转股操作是要在交易时间,也就是盘中时间下一个债转股的命令,然后盘后交易所会更会你盘中下的转股指令,将对应的可转债转为对应的股票,这是,持仓里面的可转债会消失,变成该可转债对应的正股。
(当然这是在全部转股的前提下的情况,也有可能有部分人转债只转一部分,这样持仓里面还仍然会有部分可转债没有被转为股票)
那么在Ptrade和QMT里面,如何调用API接口进行可转债转股呢?
Ptrade:
def initialize(context):
g.security = "600570.SS"
set_universe(g.security)
def before_trading_start(context, data):
g.count = 0
def handle_data(context, data):
if g.count == 0:
# 对持仓内的贝斯进行转股操作
debt_to_stock_order("123075.SZ", -1000)
g.count += 1
# 查看委托状态
log.info(get_orders())
g.count += 1
主要是上面的函数,
debt_to_stock_order 传入可转债代码和转股的数量,注意数量用加一个负号。
QMT可转债转股操作
#coding:gbk
c = True
account = '11111111' # 个人账户
def init(ContextInfo):
pass
def handlebar(ContextInfo):
if not ContextInfo.is_last_bar():
#历史k线不应该发出实盘信号 跳过
return
if c:
passorder(80,1101,account,s,5,0,-100,'1',2,'tzbz',ContextInfo)
c=False
passorder 里面的 80是 普通账户可转债转股
更多Ptrade,qmt知识,可以关注公众号
国金证券QMT量化新人培训教程
QMT • 李魔佛 发表了文章 • 0 个评论 • 10234 次浏览 • 2023-05-29 00:37
视频已经整理放到B站:
https://space.bilibili.com/73827743/channel/seriesdetail?sid=3326385&ctype=0
视频目录:
量化新人用QMT+chat GPT快速上手量化策略(一)QMT基础介绍
量化新人用QMT+chat GPT快速上手量化策略(二)QMT均线盘后选股
量化新人用QMT+chat GPT快速上手量化策略(三)一个基本的回测策略代码
量化新人用QMT+chat GPT快速上手量化策略(四) QMT运行一个策略的整体流程
量化新人用QMT+chat GPT快速上手量化策略(五) 获取股票数据
量化新人用QMT+chat GPT快速上手量化策略(六) tablib计算指标
量化新人用QMT+chat GPT快速上手量化策略(七) 下单代码编写
欢迎观看并提出疑问。
公众号:可转债量化分析 查看全部
视频已经整理放到B站:
https://space.bilibili.com/73827743/channel/seriesdetail?sid=3326385&ctype=0
视频目录:

量化新人用QMT+chat GPT快速上手量化策略(一)QMT基础介绍
量化新人用QMT+chat GPT快速上手量化策略(二)QMT均线盘后选股
量化新人用QMT+chat GPT快速上手量化策略(三)一个基本的回测策略代码
量化新人用QMT+chat GPT快速上手量化策略(四) QMT运行一个策略的整体流程
量化新人用QMT+chat GPT快速上手量化策略(五) 获取股票数据
量化新人用QMT+chat GPT快速上手量化策略(六) tablib计算指标
量化新人用QMT+chat GPT快速上手量化策略(七) 下单代码编写
欢迎观看并提出疑问。
公众号:可转债量化分析
用户问的比较多的关于ptrade基础问题
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 6167 次浏览 • 2023-05-04 01:19
1. 国金的Ptrade 实盘交易客户端是无法进行回测的,在任何时间段;
而模拟客户端可以,可以找自己的经理申请一个Ptrade模拟客户端账户;
2. 国盛的Ptrade实盘交易客户端仅在交易时间无法回测,但非交易时间可以回测;
主要是因为实盘回测和交易在同一个服务器,回测占用过多资源会影响实盘交易;模拟客户端没有这个问题;
任何时间段均可以回测; (之前某个券商的ptrade实盘服务器,因为某个用户开了40多个回测策略,一直在后台运行,而且是关于运算密集型的,导致实盘交易的程序也崩溃了)
3. 国金Ptrade无法回测星球上面的可转债实盘代码,实盘代码是基于当前的实时数据,用来进行回测没有意义,因为获取不到可转债的历史数据(溢价率,规模等),只有历史的价格数据;
4. 国金Ptrade无法使用星球上的可转债代码进行实盘,因为无法访问外网,无法访问我部署的接口数据; 而国盛的Ptrade可以;如果国金Ptrade需要实盘交易可转债,需要手工上传一些基础数据,Ptrade提供上传功能,具体操作可查找星球相关文章;
5. 在共享的Ptrade模拟试用账户上,不要保留个人代码记录,跑完后记得删除,否则其他共有同一个账户的人可以进去修改复制你的策略和代码;如果是单独的个人模拟账户,则没有这个问题。
查看全部
1. 国金的Ptrade 实盘交易客户端是无法进行回测的,在任何时间段;
而模拟客户端可以,可以找自己的经理申请一个Ptrade模拟客户端账户;
2. 国盛的Ptrade实盘交易客户端仅在交易时间无法回测,但非交易时间可以回测;
主要是因为实盘回测和交易在同一个服务器,回测占用过多资源会影响实盘交易;模拟客户端没有这个问题;
任何时间段均可以回测; (之前某个券商的ptrade实盘服务器,因为某个用户开了40多个回测策略,一直在后台运行,而且是关于运算密集型的,导致实盘交易的程序也崩溃了)
3. 国金Ptrade无法回测星球上面的可转债实盘代码,实盘代码是基于当前的实时数据,用来进行回测没有意义,因为获取不到可转债的历史数据(溢价率,规模等),只有历史的价格数据;
4. 国金Ptrade无法使用星球上的可转债代码进行实盘,因为无法访问外网,无法访问我部署的接口数据; 而国盛的Ptrade可以;如果国金Ptrade需要实盘交易可转债,需要手工上传一些基础数据,Ptrade提供上传功能,具体操作可查找星球相关文章;
5. 在共享的Ptrade模拟试用账户上,不要保留个人代码记录,跑完后记得删除,否则其他共有同一个账户的人可以进去修改复制你的策略和代码;如果是单独的个人模拟账户,则没有这个问题。

本地CPU部署的stable diffusion webui 环境,本地不受限,还可以生成色图黄图
深度学习 • 马化云 发表了文章 • 0 个评论 • 8347 次浏览 • 2023-04-17 00:27
需要不断调节词汇(英语),打造你想要的人物设定
由于本地使用的词汇不限制,还能够生成细节丰富的黄图。(宅男福音)
提供一个语法给你们用用:prompt: beautiful, masterpiece, best quality, extremely detailed face, perfect lighting, (1girl, solo, 1boy, 1girl, NemoNelly, Slight penetration, lying, on back, spread legs:1.5), street, crowd, ((skinny)), ((puffy eyes)), brown hair, medium hair, cowboy shot, medium breasts, swept bangs, walking, outdoors, sunshine, light_rays, fantasy, rococo, hair_flower,low tied hair, smile, half-closed eyes, dating, (nude), nsfw, (heavy breathing:1.5), tears, crying, blush, wet, sweat, <lora:koreanDollLikeness_v15:0.4>, <lora:povImminentPenetration_ipv1:0>, <lora:breastinclassBetter_v14:0.1>
整体来说,现在的AI技术和效果就像跃迁了一个台阶。
查看全部

.jpeg")
需要不断调节词汇(英语),打造你想要的人物设定

由于本地使用的词汇不限制,还能够生成细节丰富的黄图。(宅男福音)
提供一个语法给你们用用:
prompt: beautiful, masterpiece, best quality, extremely detailed face, perfect lighting, (1girl, solo, 1boy, 1girl, NemoNelly, Slight penetration, lying, on back, spread legs:1.5), street, crowd, ((skinny)), ((puffy eyes)), brown hair, medium hair, cowboy shot, medium breasts, swept bangs, walking, outdoors, sunshine, light_rays, fantasy, rococo, hair_flower,low tied hair, smile, half-closed eyes, dating, (nude), nsfw, (heavy breathing:1.5), tears, crying, blush, wet, sweat, <lora:koreanDollLikeness_v15:0.4>, <lora:povImminentPenetration_ipv1:0>, <lora:breastinclassBetter_v14:0.1>

整体来说,现在的AI技术和效果就像跃迁了一个台阶。

Ptrade QMT实盘策略记录 - 不定期更新
量化交易 • 李魔佛 发表了文章 • 0 个评论 • 4258 次浏览 • 2023-04-03 15:27
写出来的是已经实现且实盘稳定运行的;
涨停板;依赖ptrade的高速行情自动配合手动;两融账户的股票日内做T,持有底仓;股票小市值轮动+多因子可转债多因子(有N个版本+不同的排除因子 组合)可转债日内高频股票趋势动量ETF轮动套利脉冲卖出扫描
纯粹自己做的记录,便于自己平时复盘。
有兴趣的朋友可以关注公众号交流。 查看全部
写出来的是已经实现且实盘稳定运行的;
- 涨停板;依赖ptrade的高速行情自动配合手动;
- 两融账户的股票日内做T,持有底仓;
- 股票小市值轮动+多因子
- 可转债多因子(有N个版本+不同的排除因子 组合)
- 可转债日内高频
- 股票趋势动量
- ETF轮动套利
- 脉冲卖出扫描
纯粹自己做的记录,便于自己平时复盘。

有兴趣的朋友可以关注公众号交流。
Ptrade担保品买入卖出
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 3077 次浏览 • 2023-03-31 01:31
实际上是买卖股票,但在信用账户上,用只有资金买卖股票。
ptrade支持两融操作。
比如下面的示例代告诉我们,担保品买入股票的3个不同参数的效果:def initialize(context):
g.security = '600570.SS'
set_universe(g.security)
def handle_data(context, data):
# 以系统最新价委托
margin_trade(g.security, 100)
# 以72块价格下一个限价单
margin_trade(g.security, 100, limit_price=72)
# 以最优五档即时成交剩余撤销委托
margin_trade(g.security, 200, market_type=4) security:股票代码(str);
amount:交易数量,正数表示买入,负数表示卖出(int);
limit_price:买卖限价(float);
market_type:市价委托类型,上证非科创板股票支持参数1、4,上证科创板股票支持参数0、1、2、4,深证股票支持参数0、2、3、4、5(int);
0:对手方最优价格;
1:最优五档即时成交剩余转限价;
2:本方最优价格;
3:即时成交剩余撤销;
4:最优五档即时成交剩余撤销;
5:全额成交或撤单; 查看全部
担保品卖出指的是融资融券交易当中,用自有资金进行买卖的行为
实际上是买卖股票,但在信用账户上,用只有资金买卖股票。
ptrade支持两融操作。
比如下面的示例代告诉我们,担保品买入股票的3个不同参数的效果:
def initialize(context):
g.security = '600570.SS'
set_universe(g.security)
def handle_data(context, data):
# 以系统最新价委托
margin_trade(g.security, 100)
# 以72块价格下一个限价单
margin_trade(g.security, 100, limit_price=72)
# 以最优五档即时成交剩余撤销委托
margin_trade(g.security, 200, market_type=4)
security:股票代码(str);
amount:交易数量,正数表示买入,负数表示卖出(int);
limit_price:买卖限价(float);
market_type:市价委托类型,上证非科创板股票支持参数1、4,上证科创板股票支持参数0、1、2、4,深证股票支持参数0、2、3、4、5(int);
0:对手方最优价格;
1:最优五档即时成交剩余转限价;
2:本方最优价格;
3:即时成交剩余撤销;
4:最优五档即时成交剩余撤销;
5:全额成交或撤单;
qmt 可转债 双低(阈值)轮动 实盘代码
QMT • 李魔佛 发表了文章 • 0 个评论 • 4645 次浏览 • 2023-02-26 15:18
用已有的ptrade的代码,然后部分获取行情和交易接口按照qmt的接口文档(http://qmt.ptradeapi.com )重写,就给了一版。(对,很早以前就有一版ptrade的转债双低的了)
无论是qmt还是ptrade,都只是一个工具,用熟悉了,都无所哪个好哪个不好。
完整代码在个人星球。
觉得之前星球太便宜了,不仅给了代码,还部署了接口免费使用,通过接口获取可转债的实时数据,强赎天数,规模,溢价率,评级等等一系列数据。 而且随着时间的推移,里面积累的数据,代码也越来越多,感觉这样对前面进去并不断续费的星友有点公平,尽管以后他们续费都直接打折扣。所以还是按照一些大v运营的意见,逐年涨价策略。
越往后的朋友,因为前面积累的内容越多,因此价格也随之增长。
当然有能力可以自己写接口,部署,实盘,获取三方数据的大v,就没必要加了。
查看全部
用已有的ptrade的代码,然后部分获取行情和交易接口按照qmt的接口文档(http://qmt.ptradeapi.com )重写,就给了一版。(对,很早以前就有一版ptrade的转债双低的了)
无论是qmt还是ptrade,都只是一个工具,用熟悉了,都无所哪个好哪个不好。



完整代码在个人星球。
觉得之前星球太便宜了,不仅给了代码,还部署了接口免费使用,通过接口获取可转债的实时数据,强赎天数,规模,溢价率,评级等等一系列数据。 而且随着时间的推移,里面积累的数据,代码也越来越多,感觉这样对前面进去并不断续费的星友有点公平,尽管以后他们续费都直接打折扣。所以还是按照一些大v运营的意见,逐年涨价策略。
越往后的朋友,因为前面积累的内容越多,因此价格也随之增长。
当然有能力可以自己写接口,部署,实盘,获取三方数据的大v,就没必要加了。
qmt iquant最新接口文档
QMT • 李魔佛 发表了文章 • 0 个评论 • 3352 次浏览 • 2023-02-19 15:16
http://qmt.ptradeapi.com
除了官方的接口文档,还加入了一些个人平时编写的写法与回测,实盘代码。 不定期更新。
欢迎关注收藏。 查看全部
http://qmt.ptradeapi.com



除了官方的接口文档,还加入了一些个人平时编写的写法与回测,实盘代码。 不定期更新。
欢迎关注收藏。
迅投qmt入门教程(一)
QMT • 李魔佛 发表了文章 • 0 个评论 • 25786 次浏览 • 2023-02-06 19:43
1. 准备:
首先得开一个支持qmt的券商,目前市面上支持qmt的券商越来越丰富了。
初学者可以开一个门槛第一点的,一般入金1w-2w 不等,就可以申请开通了。
鉴于以学习为目的,真正投入到实盘中的资金不会很大,所以初始阶段也不一定就找万一免五的券商,毕竟目前要给免五,资金门槛比较高,一般要100w甚至以上。
笔者推荐国信,国金的qmt, 门槛只要1-2w就足够了,股票费率在万一,可转债万0.4-万0.5。适合初学者,这两家也可以在虚拟机运行,适合苹果mac的用户。 需要的朋友也可以在公众号后台留言: qmt开通
2. 假设已经在券商那里开通了qmt功能,接下来就开始进入教学:
这里以国信的qmt(iquant)为例:
首先要做的就是下载python库。 这个python库指的是qmt的python库,它的版本是3.6.8; 如果你只用qmt内置的python,你就不用自己到网上下载python安装程序,只需要在qmt的设置里面,点一下按钮,就可以安装python库。这里用默认的系统路径就可以了。
3. 第一个量化程序 hello world
新建策略后:
在编辑器里面输入下面的代码:#encoding:gbk
def init(ContextInfo):
print('hello world')
def handlebar(ContextInfo):
#计算当前主图的cci
print("handle bar")
点击回测:
得到输出结果
这里介绍2个概念:(3)Handlebar
handlebar 是整个 Python 模型中的核心执行函数。当模型从数据层获取到运行所需要的数据之后,会对数据集上的每一根 bar,调用一次 handlebar 函数,处理当前这根 bar 上的数据。也就是说,用户模型的核心逻辑都是写在该函数中的,如获取数据,设置下单条件等。在 handlebar 中处理完数据后,用户可以通过 paint 方法将需要绘图输出的结果返回给界面。界面会将输出结果如实的展示出来。 (4)ContextInfo
ContextInfo 是整个 Python 框架中的一个核心对象。它包含了各种与 Python 底层框架交互的 API 方法,也是一个全局的上下文环境,可以在 init 以及 handlebar 这两个函数中自由地传递用户创建的各种自定义数据。
文绉绉的,实际写一个策略,必须包含下面两个函数,而且参数也要一致,参数名随意,不过用默认的就好了。你随便改成没有意义的字符,后面自己看代码也是很麻烦。def init(ContextInfo):
pass
def handlebar(ContextInfo):
pass
init 和 handlebar 是 Python 模型中最重要的方法,也是唯二由 C++ 直接调用的方法,所有的执行代码都尽量写在这两个方法中或由其中的函数调用。【个人不太喜欢这样】
回测时间设置,在右边的菜单栏,有个回测参数,里面设置时间;在菜单“基本信息”里面 ,可以设置回测的时间间隔,可以使用分钟线,日线,小时等等不同周期,不过无法做到tick的回测。最小的只能到分钟。
但是如果你有秒的tick数据,自己写个回测框架也是可以做到秒级的tick级别的回测。很早前笔者就在星球上提供了完整的源码和数据,初学者也可以拿着去改,只要后续更新tick数据,就可以不断的回测策略的最新状态。
你写的回测实盘python代码,是保存在本地的文件夹的:
C:\iquant_gx\python, 前面的C:\iquant_gx 是你的iquant安装路径。
而且底下也有很多的现成的代码:
部分代码可以直接用pycharm就可以打开,没有加密的,但也有一些是加密了的。
比如这个自动逆回购是现成的:
对,这里就有,很多人还到处找人写;# encoding:gbk
import logging
from datetime import datetime, timedelta
from decimal import Decimal as D
from decimal import InvalidOperation
logging.basicConfig(level=logging.INFO)
# 挂单失败后的等待时长,以秒计
TIMEOUT_ON_FAIL_SEC = 30
# 等待account_callback的时长
# RUN_TIME_DELAY = 30
# how is this not defined in package??
MORNING_START = datetime.strptime(datetime.now().strftime('%Y%m%d') + '093000', '%Y%m%d%H%M%S')
MORNING_END = datetime.strptime(datetime.now().strftime('%Y%m%d') + '113000', '%Y%m%d%H%M%S')
NOON_START = datetime.strptime(datetime.now().strftime('%Y%m%d') + '130000', '%Y%m%d%H%M%S')
NOON_END = datetime.strptime(datetime.now().strftime('%Y%m%d') + '153000', '%Y%m%d%H%M%S')
# for SH only
TRANS_COST_1D = D('5e-6')
TRANS_COST_LONG = D('1.5e-7')
TRANS_COST_MAX = 100
# ORDER LIMITS
SH_UPPER = 1e7
SH_LOWER = 1e5
SZ_UPPER = 1e8
SZ_LOWER = 1e3
# ASSET NAME DICT
SH_REV_REPO = {'上交所1天': '204001.SH', '上交所2天': '204002.SH', '上交所3天': '204003.SH',
'上交所4天': '204004.SH', '上交所7天': '204007.SH', '上交所14天': '204014.SH',
'上交所28天': '204028.SH', '上交所91天': '204091.SH', '上交所182天': '204182.SH',
}
SZ_REV_REPO = {'深交所3天': '131800.SZ', '深交所7天': '131801.SZ', '深交所14天': '131802.SZ',
'深交所28天': '131803.SZ', '深交所91天': '131805.SZ', '深交所182天': '131806.SZ',
'深交所4天': '131809.SZ', '深交所1天': '131810.SZ', '深交所2天': '131811.SZ',
}
def init(ContextInfo):
ContextInfo.accID = account
ContextInfo.set_account(ContextInfo.accID)
ContextInfo.use_all_cap = False if ALL_CAP == '否' else True
# global trading control, set to False if detected error on user's side
# stop() does not halt strat
ContextInfo.order_control = False
if not ContextInfo.use_all_cap:
try:
ContextInfo.dollar_vol = float(D(DOLLAR_VOL))
except InvalidOperation:
ContextInfo.order_control = True
raise ValueError('读取资金量失败')
else:
if DOLLAR_VOL != '':
logging.warning('已设定使用全部账户资金,忽略所设置资金量')
try:
ContextInfo.start_time = datetime.strptime(datetime.now().strftime('%Y%m%d') + str(START_TIME), '%Y%m%d%H%M%S')
ContextInfo.asset_name = SH_REV_REPO[ASSET_NAME]
except KeyError:
ContextInfo.asset_name = SZ_REV_REPO[ASSET_NAME]
except ValueError as error:
if 'unconverted data remains' in str(error):
ContextInfo.order_control = True
raise ValueError('读取挂单时间失败')
if not (MORNING_END > ContextInfo.start_time >= MORNING_START) \
and not (NOON_END > ContextInfo.start_time >= NOON_START):
ContextInfo.order_control = True
raise ValueError('挂单时间不在可交易时间内')
ContextInfo.can_order = False
ContextInfo.order_done = False
if not ContextInfo.order_control:
ContextInfo.run_time("place_order", "{0}nSecond".format(TIMEOUT_ON_FAIL_SEC),
ContextInfo.start_time.strftime('%Y-%m-%d %H:%M:%S'), 'SH')
def account_callback(ContextInfo, accountInfo):
if not ContextInfo.can_order:
ContextInfo.can_order = True
if ContextInfo.use_all_cap:
ContextInfo.dollar_vol = accountInfo.m_dAvailable
else:
if ContextInfo.dollar_vol > accountInfo.m_dAvailable:
ContextInfo.order_control = True
raise ValueError('下单额度大于账户可用资金')
# check if order satisfies lower limit for each exchange
if ('SH' in ContextInfo.asset_name and ContextInfo.dollar_vol < SH_LOWER) \
or ('SZ' in ContextInfo.asset_name and ContextInfo.dollar_vol < SZ_LOWER):
ContextInfo.order_control = True
raise ValueError('下单额度低于交易所最低限额')
# checks dollar_vol and rounds the total amount
if 'SH' in ContextInfo.asset_name and ContextInfo.dollar_vol % SH_LOWER != 0:
ContextInfo.dollar_vol = (ContextInfo.dollar_vol // SH_LOWER) * SH_LOWER
logging.warning('下单额度已规整为:{0}'.format(ContextInfo.dollar_vol))
elif 'SZ' in ContextInfo.asset_name and ContextInfo.dollar_vol % SZ_LOWER != 0:
ContextInfo.dollar_vol = (ContextInfo.dollar_vol // SZ_LOWER) * SZ_LOWER
logging.warning('下单额度已规整为:{0}'.format(ContextInfo.dollar_vol))
'''
if 'SH' in ContextInfo.asset_name:
num_batch_order = int(ContextInfo.dollar_vol // SH_UPPER)
remain_order = ContextInfo.dollar_vol - num_batch_order * SH_UPPER
if ContextInfo.asset_name == '204001.SH':
transaction_cost = TRANS_COST_MAX * num_batch_order + remain_order * TRANS_COST_1D
else:
transaction_cost = TRANS_COST_MAX * num_batch_order + remain_order * TRANS_COST_LONG
if transaction_cost + ContextInfo.dollar_vol > accountInfo.m_dAvailable:
ContextInfo.order_control = True
raise ValueError('可用资金不足以垫付交易金额与手续费')
'''
ContextInfo.remain_vol = ContextInfo.dollar_vol
def handlebar(ContextInfo):
return
def place_order(ContextInfo):
if not ContextInfo.can_order or ContextInfo.order_control:
return
if not ContextInfo.order_done:
if 'SH' in ContextInfo.asset_name:
num_batch_order = int(ContextInfo.remain_vol // SH_UPPER)
remain_order = ContextInfo.remain_vol - num_batch_order * SH_UPPER
for _ in range(num_batch_order):
order_remark = '国债逆回购:尝试报单{0}元 {1}'.format(SH_UPPER, ContextInfo.asset_name)
passorder(24, 1102, ContextInfo.accID, ContextInfo.asset_name, 5, -1, SH_UPPER, order_remark, 1,
order_remark, ContextInfo)
else:
num_batch_order = int(ContextInfo.remain_vol // SZ_UPPER)
remain_order = ContextInfo.remain_vol - num_batch_order * SZ_UPPER
for _ in range(num_batch_order):
order_remark = '国债逆回购:尝试报单{0}元 {1}'.format(SZ_UPPER, ContextInfo.asset_name)
passorder(24, 1102, ContextInfo.accID, ContextInfo.asset_name, 5, -1, SZ_UPPER, order_remark, 1,
order_remark, ContextInfo)
order_remark = '国债逆回购:尝试报单{0}元 {1}'.format(remain_order, ContextInfo.asset_name)
passorder(24, 1102, ContextInfo.accID, ContextInfo.asset_name, 5, -1, remain_order, order_remark, 1,
order_remark, ContextInfo)
ContextInfo.remain_vol = 0
ContextInfo.order_done = True
def order_callback(ContextInfo, orderInfo):
curr_remark = orderInfo.m_strRemark
curr_status = orderInfo.m_nOrderStatus
if '国债逆回购' in curr_remark and ContextInfo.asset_name in curr_remark and curr_status == 57:
ContextInfo.order_done = False
# up the leftover dollar vol by failed amount
# logging.info('reported trade amount:{0}, reported_trade_volume:{1}'.format(orderInfo.m_dTradeAmount, orderInfo.m_nVolumeTotal))
# 单张100元
ContextInfo.remain_vol += orderInfo.m_nVolumeTotal * 100
if '交易时间不合法' in orderInfo.m_strCancelInfo:
ContextInfo.order_control = True
raise ValueError('国债逆回购:未能在交易时间内完成下单,停止报单。余量{0}元未报'.format(ContextInfo.remain_vol))
logging.warning('国债逆回购:报单废单,原因:\"{0}\",尝试重报'.format(orderInfo.m_strCancelInfo))
elif '国债逆回购' in curr_remark and ContextInfo.asset_name in curr_remark and curr_status == 50:
logging.info('国债逆回购:报单{0}元成功'.format(orderInfo.m_nVolumeTotal * 100))
return
待续,不定期更新
公众号:
星球:
查看全部
1. 准备:
首先得开一个支持qmt的券商,目前市面上支持qmt的券商越来越丰富了。
初学者可以开一个门槛第一点的,一般入金1w-2w 不等,就可以申请开通了。
鉴于以学习为目的,真正投入到实盘中的资金不会很大,所以初始阶段也不一定就找万一免五的券商,毕竟目前要给免五,资金门槛比较高,一般要100w甚至以上。
笔者推荐国信,国金的qmt, 门槛只要1-2w就足够了,股票费率在万一,可转债万0.4-万0.5。适合初学者,这两家也可以在虚拟机运行,适合苹果mac的用户。 需要的朋友也可以在公众号后台留言: qmt开通

2. 假设已经在券商那里开通了qmt功能,接下来就开始进入教学:
这里以国信的qmt(iquant)为例:
首先要做的就是下载python库。 这个python库指的是qmt的python库,它的版本是3.6.8; 如果你只用qmt内置的python,你就不用自己到网上下载python安装程序,只需要在qmt的设置里面,点一下按钮,就可以安装python库。这里用默认的系统路径就可以了。

3. 第一个量化程序 hello world
新建策略后:
在编辑器里面输入下面的代码:
#encoding:gbk
def init(ContextInfo):
print('hello world')
def handlebar(ContextInfo):
#计算当前主图的cci
print("handle bar")
点击回测:
得到输出结果

这里介绍2个概念:
(3)Handlebar
handlebar 是整个 Python 模型中的核心执行函数。当模型从数据层获取到运行所需要的数据之后,会对数据集上的每一根 bar,调用一次 handlebar 函数,处理当前这根 bar 上的数据。也就是说,用户模型的核心逻辑都是写在该函数中的,如获取数据,设置下单条件等。在 handlebar 中处理完数据后,用户可以通过 paint 方法将需要绘图输出的结果返回给界面。界面会将输出结果如实的展示出来。
(4)ContextInfo
ContextInfo 是整个 Python 框架中的一个核心对象。它包含了各种与 Python 底层框架交互的 API 方法,也是一个全局的上下文环境,可以在 init 以及 handlebar 这两个函数中自由地传递用户创建的各种自定义数据。
文绉绉的,实际写一个策略,必须包含下面两个函数,而且参数也要一致,参数名随意,不过用默认的就好了。你随便改成没有意义的字符,后面自己看代码也是很麻烦。
def init(ContextInfo):
pass
def handlebar(ContextInfo):
pass
init 和 handlebar 是 Python 模型中最重要的方法,也是唯二由 C++ 直接调用的方法,所有的执行代码都尽量写在这两个方法中或由其中的函数调用。【个人不太喜欢这样】
回测时间设置,在右边的菜单栏,有个回测参数,里面设置时间;在菜单“基本信息”里面 ,可以设置回测的时间间隔,可以使用分钟线,日线,小时等等不同周期,不过无法做到tick的回测。最小的只能到分钟。
但是如果你有秒的tick数据,自己写个回测框架也是可以做到秒级的tick级别的回测。很早前笔者就在星球上提供了完整的源码和数据,初学者也可以拿着去改,只要后续更新tick数据,就可以不断的回测策略的最新状态。
你写的回测实盘python代码,是保存在本地的文件夹的:
C:\iquant_gx\python, 前面的C:\iquant_gx 是你的iquant安装路径。
而且底下也有很多的现成的代码:

部分代码可以直接用pycharm就可以打开,没有加密的,但也有一些是加密了的。
比如这个自动逆回购是现成的:

对,这里就有,很多人还到处找人写;
# encoding:gbk
import logging
from datetime import datetime, timedelta
from decimal import Decimal as D
from decimal import InvalidOperation
logging.basicConfig(level=logging.INFO)
# 挂单失败后的等待时长,以秒计
TIMEOUT_ON_FAIL_SEC = 30
# 等待account_callback的时长
# RUN_TIME_DELAY = 30
# how is this not defined in package??
MORNING_START = datetime.strptime(datetime.now().strftime('%Y%m%d') + '093000', '%Y%m%d%H%M%S')
MORNING_END = datetime.strptime(datetime.now().strftime('%Y%m%d') + '113000', '%Y%m%d%H%M%S')
NOON_START = datetime.strptime(datetime.now().strftime('%Y%m%d') + '130000', '%Y%m%d%H%M%S')
NOON_END = datetime.strptime(datetime.now().strftime('%Y%m%d') + '153000', '%Y%m%d%H%M%S')
# for SH only
TRANS_COST_1D = D('5e-6')
TRANS_COST_LONG = D('1.5e-7')
TRANS_COST_MAX = 100
# ORDER LIMITS
SH_UPPER = 1e7
SH_LOWER = 1e5
SZ_UPPER = 1e8
SZ_LOWER = 1e3
# ASSET NAME DICT
SH_REV_REPO = {'上交所1天': '204001.SH', '上交所2天': '204002.SH', '上交所3天': '204003.SH',
'上交所4天': '204004.SH', '上交所7天': '204007.SH', '上交所14天': '204014.SH',
'上交所28天': '204028.SH', '上交所91天': '204091.SH', '上交所182天': '204182.SH',
}
SZ_REV_REPO = {'深交所3天': '131800.SZ', '深交所7天': '131801.SZ', '深交所14天': '131802.SZ',
'深交所28天': '131803.SZ', '深交所91天': '131805.SZ', '深交所182天': '131806.SZ',
'深交所4天': '131809.SZ', '深交所1天': '131810.SZ', '深交所2天': '131811.SZ',
}
def init(ContextInfo):
ContextInfo.accID = account
ContextInfo.set_account(ContextInfo.accID)
ContextInfo.use_all_cap = False if ALL_CAP == '否' else True
# global trading control, set to False if detected error on user's side
# stop() does not halt strat
ContextInfo.order_control = False
if not ContextInfo.use_all_cap:
try:
ContextInfo.dollar_vol = float(D(DOLLAR_VOL))
except InvalidOperation:
ContextInfo.order_control = True
raise ValueError('读取资金量失败')
else:
if DOLLAR_VOL != '':
logging.warning('已设定使用全部账户资金,忽略所设置资金量')
try:
ContextInfo.start_time = datetime.strptime(datetime.now().strftime('%Y%m%d') + str(START_TIME), '%Y%m%d%H%M%S')
ContextInfo.asset_name = SH_REV_REPO[ASSET_NAME]
except KeyError:
ContextInfo.asset_name = SZ_REV_REPO[ASSET_NAME]
except ValueError as error:
if 'unconverted data remains' in str(error):
ContextInfo.order_control = True
raise ValueError('读取挂单时间失败')
if not (MORNING_END > ContextInfo.start_time >= MORNING_START) \
and not (NOON_END > ContextInfo.start_time >= NOON_START):
ContextInfo.order_control = True
raise ValueError('挂单时间不在可交易时间内')
ContextInfo.can_order = False
ContextInfo.order_done = False
if not ContextInfo.order_control:
ContextInfo.run_time("place_order", "{0}nSecond".format(TIMEOUT_ON_FAIL_SEC),
ContextInfo.start_time.strftime('%Y-%m-%d %H:%M:%S'), 'SH')
def account_callback(ContextInfo, accountInfo):
if not ContextInfo.can_order:
ContextInfo.can_order = True
if ContextInfo.use_all_cap:
ContextInfo.dollar_vol = accountInfo.m_dAvailable
else:
if ContextInfo.dollar_vol > accountInfo.m_dAvailable:
ContextInfo.order_control = True
raise ValueError('下单额度大于账户可用资金')
# check if order satisfies lower limit for each exchange
if ('SH' in ContextInfo.asset_name and ContextInfo.dollar_vol < SH_LOWER) \
or ('SZ' in ContextInfo.asset_name and ContextInfo.dollar_vol < SZ_LOWER):
ContextInfo.order_control = True
raise ValueError('下单额度低于交易所最低限额')
# checks dollar_vol and rounds the total amount
if 'SH' in ContextInfo.asset_name and ContextInfo.dollar_vol % SH_LOWER != 0:
ContextInfo.dollar_vol = (ContextInfo.dollar_vol // SH_LOWER) * SH_LOWER
logging.warning('下单额度已规整为:{0}'.format(ContextInfo.dollar_vol))
elif 'SZ' in ContextInfo.asset_name and ContextInfo.dollar_vol % SZ_LOWER != 0:
ContextInfo.dollar_vol = (ContextInfo.dollar_vol // SZ_LOWER) * SZ_LOWER
logging.warning('下单额度已规整为:{0}'.format(ContextInfo.dollar_vol))
'''
if 'SH' in ContextInfo.asset_name:
num_batch_order = int(ContextInfo.dollar_vol // SH_UPPER)
remain_order = ContextInfo.dollar_vol - num_batch_order * SH_UPPER
if ContextInfo.asset_name == '204001.SH':
transaction_cost = TRANS_COST_MAX * num_batch_order + remain_order * TRANS_COST_1D
else:
transaction_cost = TRANS_COST_MAX * num_batch_order + remain_order * TRANS_COST_LONG
if transaction_cost + ContextInfo.dollar_vol > accountInfo.m_dAvailable:
ContextInfo.order_control = True
raise ValueError('可用资金不足以垫付交易金额与手续费')
'''
ContextInfo.remain_vol = ContextInfo.dollar_vol
def handlebar(ContextInfo):
return
def place_order(ContextInfo):
if not ContextInfo.can_order or ContextInfo.order_control:
return
if not ContextInfo.order_done:
if 'SH' in ContextInfo.asset_name:
num_batch_order = int(ContextInfo.remain_vol // SH_UPPER)
remain_order = ContextInfo.remain_vol - num_batch_order * SH_UPPER
for _ in range(num_batch_order):
order_remark = '国债逆回购:尝试报单{0}元 {1}'.format(SH_UPPER, ContextInfo.asset_name)
passorder(24, 1102, ContextInfo.accID, ContextInfo.asset_name, 5, -1, SH_UPPER, order_remark, 1,
order_remark, ContextInfo)
else:
num_batch_order = int(ContextInfo.remain_vol // SZ_UPPER)
remain_order = ContextInfo.remain_vol - num_batch_order * SZ_UPPER
for _ in range(num_batch_order):
order_remark = '国债逆回购:尝试报单{0}元 {1}'.format(SZ_UPPER, ContextInfo.asset_name)
passorder(24, 1102, ContextInfo.accID, ContextInfo.asset_name, 5, -1, SZ_UPPER, order_remark, 1,
order_remark, ContextInfo)
order_remark = '国债逆回购:尝试报单{0}元 {1}'.format(remain_order, ContextInfo.asset_name)
passorder(24, 1102, ContextInfo.accID, ContextInfo.asset_name, 5, -1, remain_order, order_remark, 1,
order_remark, ContextInfo)
ContextInfo.remain_vol = 0
ContextInfo.order_done = True
def order_callback(ContextInfo, orderInfo):
curr_remark = orderInfo.m_strRemark
curr_status = orderInfo.m_nOrderStatus
if '国债逆回购' in curr_remark and ContextInfo.asset_name in curr_remark and curr_status == 57:
ContextInfo.order_done = False
# up the leftover dollar vol by failed amount
# logging.info('reported trade amount:{0}, reported_trade_volume:{1}'.format(orderInfo.m_dTradeAmount, orderInfo.m_nVolumeTotal))
# 单张100元
ContextInfo.remain_vol += orderInfo.m_nVolumeTotal * 100
if '交易时间不合法' in orderInfo.m_strCancelInfo:
ContextInfo.order_control = True
raise ValueError('国债逆回购:未能在交易时间内完成下单,停止报单。余量{0}元未报'.format(ContextInfo.remain_vol))
logging.warning('国债逆回购:报单废单,原因:\"{0}\",尝试重报'.format(orderInfo.m_strCancelInfo))
elif '国债逆回购' in curr_remark and ContextInfo.asset_name in curr_remark and curr_status == 50:
logging.info('国债逆回购:报单{0}元成功'.format(orderInfo.m_nVolumeTotal * 100))
return
待续,不定期更新
公众号:
星球:
ptrade获取分时成交数据-LEVEL2数据逐笔数据
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 6414 次浏览 • 2023-02-04 12:27
中提供了获取分时成交的数据。
使用场景
该函数在交易模块可用
接口说明
该接口用于获取当日分时成交行情数据。
注意事项:
1、沪深市场都有分时成交数据;
2、分时成交数据需开通level2行情才有数据推送,否则无数据返回;
返回字段:
返回
返回一个OrderedDict对象,包含每只代码的分时成交行情数据。(OrderedDict([(),()...]))
返回结果字段介绍:
time_stamp: 时间戳毫秒级(str:numpy.int64);
hq_px: 价格(str:numpy.float64);
hq_px64: 价格(str:numpy.int64)(行情暂不支持,返回均为0);
business_amount: 成交数量(str:numpy.int64);
business_balance: 成交金额(str:numpy.int64);
business_count: 成交笔数(str:numpy.int64);
business_direction: 成交方向(0:卖,1:买,2:平盘)(str:numpy.int64);
amount: 持仓量(str:numpy.int64)(行情暂不支持,返回均为0);
start_index: 分笔关联的逐笔开始序号(str:numpy.int64)(行情暂不支持,返回均为0);
end_index: 分笔关联的逐笔结束序号(str:numpy.int64)(行情暂不支持,返回均为0);
示例代码:
def initialize(context):
g.security = '000001.SZ'
set_universe(g.security)
def handle_data(context, data):
#获取000001.SZ的分时成交数据
direction_data = get_tick_direction(g.security)
log.info(direction_data)
#获取指定股票列表分时成交数据
direction_data = get_tick_direction(['000002.SZ','000032.SZ'])
log.info(direction_data)
#获取成交量
business_amount = direction_data['000002.SZ']['business_amount']
log.info('分时成交的成交量为:%s' % business_amount)
不过在handle_bar中或者tick_data中,实际行情推送最快也要3s,所以拿到的level2的是切片数据,即使拿到很多数据,可是行情获取时间间隔还是3s, 无法做到和qmt那样的level2逐笔订阅驱动。还有level2数据需要收费。ptrade目前常用的几个券商都不支持level2的。
目前有万一免五的qmt ptrade量化交易接口的券商吗?
查看全部
中提供了获取分时成交的数据。
使用场景
该函数在交易模块可用
接口说明
该接口用于获取当日分时成交行情数据。
注意事项:
1、沪深市场都有分时成交数据;
2、分时成交数据需开通level2行情才有数据推送,否则无数据返回;
返回字段:
返回
返回一个OrderedDict对象,包含每只代码的分时成交行情数据。(OrderedDict([(),()...]))
返回结果字段介绍:
time_stamp: 时间戳毫秒级(str:numpy.int64);
hq_px: 价格(str:numpy.float64);
hq_px64: 价格(str:numpy.int64)(行情暂不支持,返回均为0);
business_amount: 成交数量(str:numpy.int64);
business_balance: 成交金额(str:numpy.int64);
business_count: 成交笔数(str:numpy.int64);
business_direction: 成交方向(0:卖,1:买,2:平盘)(str:numpy.int64);
amount: 持仓量(str:numpy.int64)(行情暂不支持,返回均为0);
start_index: 分笔关联的逐笔开始序号(str:numpy.int64)(行情暂不支持,返回均为0);
end_index: 分笔关联的逐笔结束序号(str:numpy.int64)(行情暂不支持,返回均为0);
示例代码:
def initialize(context):
g.security = '000001.SZ'
set_universe(g.security)
def handle_data(context, data):
#获取000001.SZ的分时成交数据
direction_data = get_tick_direction(g.security)
log.info(direction_data)
#获取指定股票列表分时成交数据
direction_data = get_tick_direction(['000002.SZ','000032.SZ'])
log.info(direction_data)
#获取成交量
business_amount = direction_data['000002.SZ']['business_amount']
log.info('分时成交的成交量为:%s' % business_amount)
不过在handle_bar中或者tick_data中,实际行情推送最快也要3s,所以拿到的level2的是切片数据,即使拿到很多数据,可是行情获取时间间隔还是3s, 无法做到和qmt那样的level2逐笔订阅驱动。还有level2数据需要收费。ptrade目前常用的几个券商都不支持level2的。
目前有万一免五的qmt ptrade量化交易接口的券商吗?
国信可以使用miniqmt吗?
QMT • 李魔佛 发表了文章 • 0 个评论 • 8447 次浏览 • 2023-01-21 15:52
所以笔者特意去问了下国信的好友兼营业部经理,但他回复说,个人只要申请,就可以开通mini qmt。如果不申请,是无法使用的,无法连接上去。
但因为开通这个是不用门槛的,可能会有部分不懂的或者不愿意的经理会和客户说不支持,或者需要机构这样话语。
具体情况,具体分析。
1. 国信证券iQuant策略交易平台精简版是指国信证券iQuant策略交易平台更专业快速且简洁的版本,满足股票、期货、期权、基金等全品种交易需求。
2. 风险等级:R4
投资期限:0-1年
投资品种:权益类投资品种如股票、混合型基金、偏股型基金、股票型基金等。
3. 平台使用不收取费用。
具体的申请表如下:
不过申请了这个权限后,只能进行拉取数据,并没有交易权限。。交易权限需要机构才能开通。郁闷,看来国信的miniqmt是无法进行交易的了,只能白嫖点数据。
如果需要文字word版本,
可以到公众号后台回复: 国信mini申请
获取word版本。
或者加微信开通指定的营业部的国信qmt(iquant), 也可以帮你开通mini qmt。
查看全部

之前群里有国信的小伙伴说,国信的mini qmt无法使用的。
所以笔者特意去问了下国信的好友兼营业部经理,但他回复说,个人只要申请,就可以开通mini qmt。如果不申请,是无法使用的,无法连接上去。
但因为开通这个是不用门槛的,可能会有部分不懂的或者不愿意的经理会和客户说不支持,或者需要机构这样话语。
具体情况,具体分析。
1. 国信证券iQuant策略交易平台精简版是指国信证券iQuant策略交易平台更专业快速且简洁的版本,满足股票、期货、期权、基金等全品种交易需求。
2. 风险等级:R4
投资期限:0-1年
投资品种:权益类投资品种如股票、混合型基金、偏股型基金、股票型基金等。
3. 平台使用不收取费用。
具体的申请表如下:

不过申请了这个权限后,只能进行拉取数据,并没有交易权限。。交易权限需要机构才能开通。郁闷,看来国信的miniqmt是无法进行交易的了,只能白嫖点数据。
如果需要文字word版本,
可以到公众号后台回复: 国信mini申请
获取word版本。
或者加微信开通指定的营业部的国信qmt(iquant), 也可以帮你开通mini qmt。
目前有万一免五的qmt ptrade量化交易接口的券商吗?
券商万一免五 • 李魔佛 发表了文章 • 0 个评论 • 6588 次浏览 • 2023-01-08 19:31
目前量化qmt 有可以免五的券商了,国信,国元
国元证券万一免五,最低0元起步,免五门槛入金1w,不过开通qmt的门槛是100w
国信证券万一免五,门槛是100门槛,不过如果只是开通qmt(iquant),它的门槛是比较低的,入金2w就可以了
综合来看,如要要用qmt+万一免五,入金要100w的。
目前(截至2023-01-08日) 市场上已经没有可以免五的支持qmt,ptrade的量化交易券商。
当然动辄入金500w-5000W的券商就忽略了,大部分散户是达不到这个资金要求的。
在正常条件下,入金1W 到 50W的范围内,目前多家券商已经停止股票免五了,费率最低是万一, 不过可以在开户后2-6月申请免五。【国金】
或者先把户开了,把量化接口的权限也开了,等到券商可以重新申请免五的时候申请即可。 目前多家券商的营业部老板也承诺了,只要后续免五开放,就可以帮有量化交易权限的用户申请免五。
(最晚大概3月低可以免5)【国盛】
当然如果如果有券商营业部可以支持免五,也可以联系微信自荐,诚意合作。
查看全部
目前量化qmt 有可以免五的券商了,国信,国元
国元证券万一免五,最低0元起步,免五门槛入金1w,不过开通qmt的门槛是100w
国信证券万一免五,门槛是100门槛,不过如果只是开通qmt(iquant),它的门槛是比较低的,入金2w就可以了
综合来看,如要要用qmt+万一免五,入金要100w的。
目前(截至2023-01-08日) 市场上已经没有可以免五的支持qmt,ptrade的量化交易券商。
当然动辄入金500w-5000W的券商就忽略了,大部分散户是达不到这个资金要求的。
在正常条件下,入金1W 到 50W的范围内,目前多家券商已经停止股票免五了,费率最低是万一, 不过可以在开户后2-6月申请免五。【国金】
或者先把户开了,把量化接口的权限也开了,等到券商可以重新申请免五的时候申请即可。 目前多家券商的营业部老板也承诺了,只要后续免五开放,就可以帮有量化交易权限的用户申请免五。
(最晚大概3月低可以免5)【国盛】

当然如果如果有券商营业部可以支持免五,也可以联系微信自荐,诚意合作。

Ptrade获取可转债强赎数据
Ptrade • 李魔佛 发表了文章 • 0 个评论 • 3580 次浏览 • 2022-12-21 15:50
所以在可转债的策略里面,把强赎的转债排除掉,是一个不错的因子。
但内置的ptrade接口数据并无提供任何转债相关的数据。
不过笔者这里提供了一个自研的数据接口。
http://ptradeapi.com/#%E5%8F%AF%E8%BD%AC%E5%80%BA%E5%BC%BA%E8%B5%8E%E4%B8%8E%E6%95%B0%E6%97%A5%E5%AD%90
方便在ptrade里面调用。
查看全部

所以在可转债的策略里面,把强赎的转债排除掉,是一个不错的因子。
但内置的ptrade接口数据并无提供任何转债相关的数据。
不过笔者这里提供了一个自研的数据接口。
http://ptradeapi.com/#%E5%8F%AF%E8%BD%AC%E5%80%BA%E5%BC%BA%E8%B5%8E%E4%B8%8E%E6%95%B0%E6%97%A5%E5%AD%90
方便在ptrade里面调用。

Ptrade QMT 哪家费率最便宜,门槛最低?
券商万一免五 • 绫波丽 发表了文章 • 0 个评论 • 6536 次浏览 • 2022-11-27 19:09
笔者只会推荐合适的券商和量化接口给你,而不会推荐坑爹的券商给你。
如果你不信任,绕路即可,莫浪费大家时间。或者你有好的资源或者券商,你也可以推荐给我,可以给你发红包,奖励你提供有用的情报信息。
目前支持ptrade,qmt可以股票可以免五(0.1元起步)的券商,只有国盛,需要的可以找我开。 但是有入金门槛,ptrade门槛30w, qmt 的门槛50w。 国盛的ptrade可以链接外网。其他家的不行。但国盛的qmt不支持运行在云服务器。
其他家的qmt是支持的云服务器的,但国金的qmt会每天自动退出,需要每次手动点击登录,我也写了一个自动登录的小脚本,开完户的朋友可以拿去用用。
门槛低的国信,适合新手使用,但是没有miniqmt,这个东西也不一定适合你。 真的需要这个功能,在qmt里面可以写一段代码,让它把下单接口变成http指令,把下单功能独立出来,也是可以的。不过这个属于进阶功能。 需要的也可以把代码给你。
笔者用过大部分券商的ptrade qmt,所以个人的指导与推荐还是很有指导意见的。 写过的策略也大部分人(99%)多, 平台好坏,坑的多寡,哪里有雷,都已经摸清摸楚。 可以大大节省你们的时间。 当然你也可以忽略,自己去折腾折腾。选ptrade 还是qmt,然后哪个券商,什么费率。
需要开通ptrade - qmt 低门槛 低费率 的 或者可以提供更低费用的资源的可以加微信:
ptrade 接口文档: http://ptradeapi.com
查看全部
笔者只会推荐合适的券商和量化接口给你,而不会推荐坑爹的券商给你。
如果你不信任,绕路即可,莫浪费大家时间。或者你有好的资源或者券商,你也可以推荐给我,可以给你发红包,奖励你提供有用的情报信息。
目前支持ptrade,qmt可以股票可以免五(0.1元起步)的券商,只有国盛,需要的可以找我开。 但是有入金门槛,ptrade门槛30w, qmt 的门槛50w。 国盛的ptrade可以链接外网。其他家的不行。但国盛的qmt不支持运行在云服务器。
其他家的qmt是支持的云服务器的,但国金的qmt会每天自动退出,需要每次手动点击登录,我也写了一个自动登录的小脚本,开完户的朋友可以拿去用用。
门槛低的国信,适合新手使用,但是没有miniqmt,这个东西也不一定适合你。 真的需要这个功能,在qmt里面可以写一段代码,让它把下单接口变成http指令,把下单功能独立出来,也是可以的。不过这个属于进阶功能。 需要的也可以把代码给你。
笔者用过大部分券商的ptrade qmt,所以个人的指导与推荐还是很有指导意见的。 写过的策略也大部分人(99%)多, 平台好坏,坑的多寡,哪里有雷,都已经摸清摸楚。 可以大大节省你们的时间。 当然你也可以忽略,自己去折腾折腾。选ptrade 还是qmt,然后哪个券商,什么费率。

需要开通ptrade - qmt 低门槛 低费率 的 或者可以提供更低费用的资源的可以加微信:
ptrade 接口文档: http://ptradeapi.com
linux监控shell进程是否运行,不运行的时候自动启动
Linux • 李魔佛 发表了文章 • 0 个评论 • 3197 次浏览 • 2022-07-13 00:17
保存为monitor.sh
#!/bin/bash
line=$(ps -aux | grep -c /usr/sbin/ssh | grep -v "grep")
# 匹配的行数
if [ $line -eq 1 ];
then
sudo /etc/init.d/ssh restart
# 重启ssh服务
else
echo ssh is running....
# 向日志发送邮件,显示ssh运行中。。。
fi
给个执行权限
chmod +x monitor.sh
然后设置定时任务,
比如隔5分钟运行一次上面的脚本
*/5 * * * * monitor.sh
查看全部
保存为monitor.sh
#!/bin/bash
line=$(ps -aux | grep -c /usr/sbin/ssh | grep -v "grep")
# 匹配的行数
if [ $line -eq 1 ];
then
sudo /etc/init.d/ssh restart
# 重启ssh服务
else
echo ssh is running....
# 向日志发送邮件,显示ssh运行中。。。
fi
给个执行权限
chmod +x monitor.sh
然后设置定时任务,
比如隔5分钟运行一次上面的脚本
*/5 * * * * monitor.sh
不同券商的ptrade的异同
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 0 个评论 • 4481 次浏览 • 2022-06-17 16:36
1. 湘财无法访问外网,国盛的可以
2.
get_cb_list 获取可转债列表 的 国盛没有
get_history 获取历史数据函数
get_history(5, frequency='1d', field='close', security_list=['123084.SZ'], fq=None, include=False, fill='nan')国盛是没有fill参数的。
持续更新。。。待续
Ptrade开户联系:
查看全部
1. 湘财无法访问外网,国盛的可以
2.

get_cb_list 获取可转债列表 的 国盛没有
get_history 获取历史数据函数
get_history(5, frequency='1d', field='close', security_list=['123084.SZ'], fq=None, include=False, fill='nan')国盛是没有fill参数的。持续更新。。。待续
Ptrade开户联系:
星球文章 获取所有文章 爬虫
python爬虫 • 李魔佛 发表了文章 • 0 个评论 • 3405 次浏览 • 2022-06-03 13:49
群里没有人没有吐槽过这个搜索功能的。
所以只好自己写个程序把自己的文章抓下来,作为文章目录:
生成的markdown文件
每次只需要运行python main.py 就可以拿到最新的星球文章链接了。
需要源码可以在公众号联系~
查看全部

群里没有人没有吐槽过这个搜索功能的。
所以只好自己写个程序把自己的文章抓下来,作为文章目录:


生成的markdown文件

每次只需要运行python main.py 就可以拿到最新的星球文章链接了。
需要源码可以在公众号联系~
ptrade qmt量化平台收费吗?
券商万一免五 • 李魔佛 回复了问题 • 2 人关注 • 1 个回复 • 7486 次浏览 • 2022-07-13 17:04
python识别股票K线形态,准确率回测(一)
量化交易-Ptrade-QMT • 李魔佛 发表了文章 • 1 个评论 • 13562 次浏览 • 2022-05-22 01:13
对于一些做股票技术分析的投资者来说,对常见的k线形态应该都不陌生,比如十字星,红三兵,头肩顶(底),岛型反转,吊颈线,两只乌鸦,三只乌鸦,四只乌鸦(哈)
做价投的投资者可能会对这些划线的嗤之以鼻,而短线操盘者却有可能把它奉为圭臬,以之作为买卖标准。
海乃百川,兼听则明,笔者认为多吸收不同的观点与技术,可以更加全面的加深投资认知。你画的圆圈越大,圆圈外的未知空间也越大。
本文介绍使用python对A股市场的股票(转债也可以)的K线进行识别,然后回测某个形态出现后接下来的涨跌幅,还可以通过设定的形态进行选股。
举个例子,我们可以统计所有个股出现了“早晨之星“这一形态后,一周后甚至一个月后,个股是涨了还是跌了,从大量结果中统计出一些有意义的结果。
为了便于验证查看结果图形,我们先介绍如何使用python来画股票K线图。
有数据之后,剩下画图是很简单的,很多第三方的库已经封装好了各种蜡烛图绘制函数。我们要做只是传入每天开,收盘价,以及最高最低价。
获取股票的数据
市面有不少第三方的库可以获取股票和可转债的日线数据,比如tushare和akshare。本文以股票数据为例。
以akshare为例,代码如下所示:
# pip install akshare
import akshare as ak
def get_k_line(code="sz002241"): #
df = ak.stock_zh_a_daily(symbol=code, start_date="20220101", end_date="20220515",
adjust="qfq")
# 这个函数只适合取股票数据,转债会报错,转债的日线数据可以使用其他函数,这里选择股价前复权
df.to_excel("同和药业k.xlsx")
如上面代码所示,我们使用stock_zh_a_daily方法获取一段时间的数据,这里的日期可以根据你的需求进行调整,比如设置start_date=“20200101”,end_date=“20220515”,就可以获取一年时间段的股票数据。
而股票的代码有sh与sz之分,sz代表深市的股票,所有深市的股票前面都必须带上sz,比如这里的同和药业,就是sz002241。
同样的,sh是上证交易所的股票,所有上证的股票前面必须带上sh。
这里,我们来看看获取的同和药业股票数据格式,如下图所示:
date:交易日期
open:代表开盘价
high:当天最高价
low:当天最低价
close:当天收盘价
volume:当天成交量(元)
outstanding_share:流动股本(股)
turnover:换手率
既然已经拿到了数据,下面我们来绘制K线图。
绘制K线图
在python中,绘制K线图需要用到mpl_finance库,而这个库提供了4种方式绘制K线图,这里我们介绍其中的一种,代码如下所示:
import mpl_finance as mpf
import matplotlib.pyplot as plt
import pandas as pd
#创建绘图的基本参数
fig=plt.figure(figsize=(12, 8))
ax=fig.add_subplot(111)
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
#显示出来
plt.show()
运行此段代码后,会显示如下效果图:
和东财上的同和药业的k线图基本一致的。
不过,这个K线图有一个问题,就是X坐标轴并不是显示的时间,而是数字,这是因为我们绘制K线图的方法,并没有提供X轴的参数,那怎么让下面的数字替换为时间呢?
我们先来看一段代码:
import matplotlib.ticker as ticker
#将股票时间转换为标准时间,不带时分秒的数据
def date_to_num(dates):
num_time = []
for date in dates:
date_time = datetime.strptime(date, '%Y-%m-%d')
num_date = date2num(date_time)
num_time.append(num_date)
return num_time
#创建绘图的基本参数
fig=plt.figure(figsize=(12, 8))
ax=fig.add_subplot(111)
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
df['date'] = pd.to_datetime(df['date'])
df['date'] = df['date'].apply(lambda x: x.strftime('%Y-%m-%d'))
def format_date(x, pos=None):
if x < 0 or x > len(df['date']) - 1:
return ''
return df['date'][int(x)]
ax.xaxis.set_major_formatter(ticker.FuncFormatter(format_date))
plt.setp(plt.gca().get_xticklabels(), rotation=45, horizontalalignment='right')
#显示出来
plt.show()
这里,我们定义了2个方法:第1个方法date_to_num主要的作用就是将获取的时间数据转换为标准的日期数据;第2个方法,就是根据X的数值替换时间值。
其中,set_major_formatter方法是将数值替换为时间值的操作库,而plt.setup的功能就是设置X轴的标签倾斜45度以及右对齐。运行之后,我们的K线图就显示的非常完美了,如下图所示:
均线图
虽然我们实现了K线图,但是有没有发现,其实大多数的股票交易软件K线图上面其实还标记有均线,比如常用的有5日均线,10日均线,30均线。
所以,我们需要将均线一起添加到我们的K线图之上。
计算均线的方式如下:
df["SMA5"] = df["close"].rolling(5).mean()
df["SMA10"] = df["close"].rolling(10).mean()
df["SMA30"] = df["close"].rolling(30).mean()
3行代码就可以获取到股票的均线值。
接着,我们可以使用上面的ax进行绘制均线了,
添加的代码如下所示:
ax.plot(np.arange(0, len(df)), df['SMA5']) # 绘制5日均线
ax.plot(np.arange(0, len(df)), df['SMA10']) # 绘制10日均线
ax.plot(np.arange(0, len(df)), df['SMA30']) # 绘制30日均线
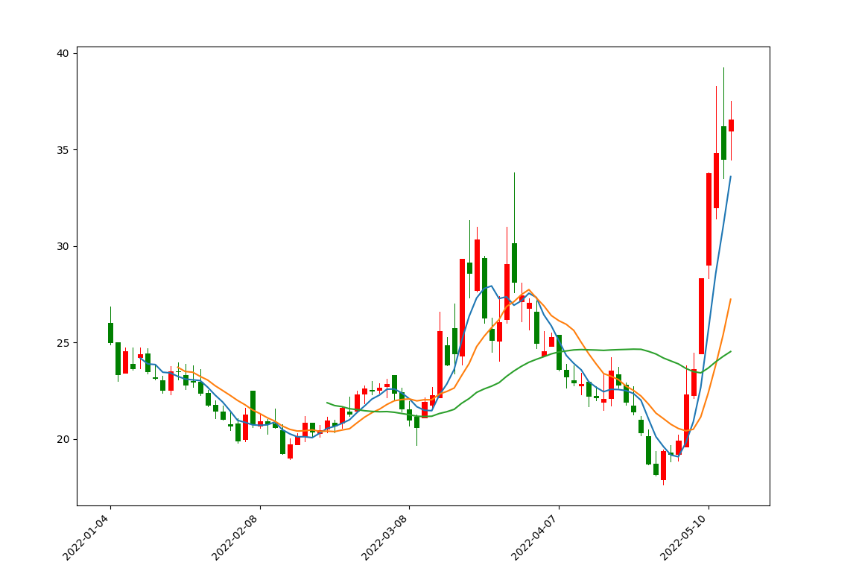
这里,同样将X轴设置为数字,将这两段代码添加到上面的K线图代码中,自然也会将X轴替换为时间。运行之后,显示效果如下图所示:
这里5日均线为蓝色,10日均线为橙色,30日均线为绿色,如果需要自己设置颜色,可以在每条均线的的绘制方法中加入color参数。
细心的读者肯定发现30日均线只有最后一小段,这是因为前29日不够30日是算不出均线的,同样的5,10日均线也是如此。
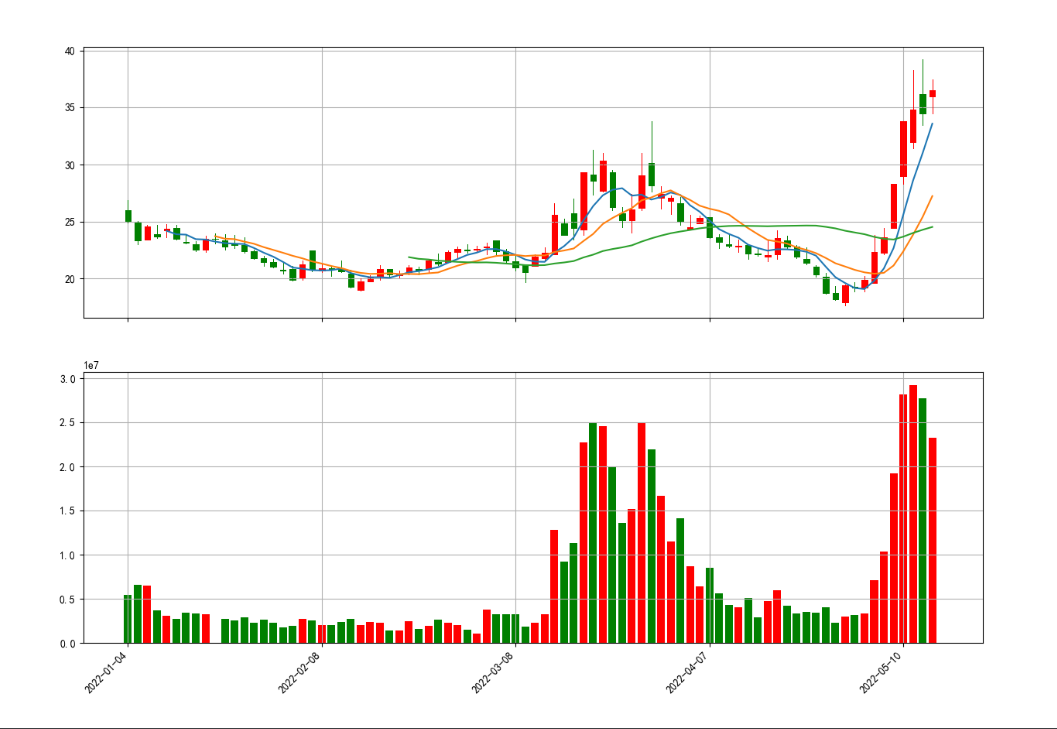
成交量
最后,我们还需要绘制成交量。在多数的股票交易软件中,上面是K线图,一般下面对应的就是成交量,这样对比起来看,往往能直观的看到数据的变化。
但是,因为上面有个K线图,那么同一个画布中就有了2个图片,且它们共用一个X轴,那么我们需要更改一下基本的参数,
代码如下所示:
import mpl_finance as mpf
import matplotlib.pyplot as plt
import pandas as pd
import matplotlib.ticker as ticker
import numpy as np
#创建绘图的基本参数
fig, axes = plt.subplots(2, 1, sharex=True, figsize=(15, 10))
ax1, ax2 = axes.flatten()
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax1, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
df['date'] = pd.to_datetime(df['date'])
df['date'] = df['date'].apply(lambda x: x.strftime('%Y-%m-%d'))
def format_date(x, pos=None):
if x < 0 or x > len(df['date']) - 1:
return ''
return df['date'][int(x)]
df["SMA5"] = df["close"].rolling(5).mean()
df["SMA10"] = df["close"].rolling(10).mean()
df["SMA30"] = df["close"].rolling(30).mean()
ax1.plot(np.arange(0, len(df)), df['SMA5']) # 绘制5日均线
ax1.plot(np.arange(0, len(df)), df['SMA10']) # 绘制10日均线
ax1.plot(np.arange(0, len(df)), df['SMA30']) # 绘制30日均线
ax1.xaxis.set_major_formatter(ticker.FuncFormatter(format_date))
plt.setp(plt.gca().get_xticklabels(), rotation=45, horizontalalignment='right')
#显示出来
plt.show()
这里,我们将绘图的画布设置为2行1列。同时,将上面绘制的所有数据都更改为ax1,这样均线与K线图会绘制到第一个子图中。
接着,我们需要绘制成交量,但是我们知道,一般股票交易软件都将上涨的那天成交量设置为红色,而将下跌的成交量绘制成绿色。所以,首先我们要做的是将获取的股票数据根据当天的涨跌情况进行分类。
具体代码如下:
red_pred = np.where(df["close"] > df["open"], df["volume"], 0)
blue_pred = np.where(df["close"] < df["open"], df["volume"], 0)
如上面代码所示,我们通过np.where(condition, x, y)筛选数据。这里满足条件condition,输出X,不满足条件输出Y,这样我们就将涨跌的成交量数据进行了分类。
最后,我们直接通过柱状图方法绘制成交量,
具体代码如下所示:
ax2.bar(np.arange(0, len(df)), red_pred, facecolor="red")
ax2.bar(np.arange(0, len(df)), blue_pred, facecolor="blue")
将这4行代码,全部加入到plt.show()代码的前面即可。
运行之后,输出的效果图如下:
根据定义编写形态
接下来,我们根据定义来构造一个简单的形态函数,比如长上影线。
上影线
根据网络上的定义:
⑤上影阳线:开盘后价格冲高回落,涨势受阻,虽然收盘价仍高于开盘价,但上方有阻力,可视为弱势。
⑥上影阴线:开盘后价格冲高受阻,涨势受阻,收盘价低于开盘价,上方有阻力,可视为弱势。
那么简单定义为:(high - close)/close > 7%,(high - open)/open > 7% ,可能不是太精确,这里只是为了演示,忽略一些具体细节。
简单理解就是,当天最高价比收盘价,开盘价高得多。
长上影匹配函数,简单,只有一行就搞定。
def long_up_shadow(o,c,h,l):
return True if (h-c)/c >=0.07 and (h-o)/o>=0.07 else False
然后把这个长上影函数应用到上面的同和药业。
得到的效果:
df = pd.read_excel("同和药业k.xlsx")
count_num = []
for row,item in df.iterrows():
if long_up_shadow(item['open'],item['close'],item['high'],item['low']):
count_num.append(row)
plot_image(df,count_num)
图里面的4个箭头长上影是python自动标上去的,然后对着数据到同花顺核对一下,都是满足长度大于7%的。
可以看到在3月18日和28日的两根长上影之后,同和药业的股价走了一波趋势下跌。【PS:选这个股票并没有刻意去挑选,在集思录默认排名,找了一个跌幅第一个转债的正股就把代码拷贝过来测试】
那么,有这么多的形态,难道每一个都要自己写代码筛选形态吗? 不用哈,因为已经有人写了第三方的库,你只需要调用就可以了。
截取的部分函数名与说明
比如,像两只乌鸦,描述起来都感觉有点复杂,自己手撸代码都会搞出一堆bug。而用taLib这个库,你只需要一行调用代码,就可以完成这些复杂的形态筛选工作。
示例代码:
df['tow_crows'] = talib.CDL2CROWS(df['open'].values, df['high'].values, df['low'].values, df['close'].values)
pattern = df[(df['tow_crows'] == 100) | (df['tow_crows'] == -100)]
上面得到的pattern就是满足要求的形态,如CDL2CROWS 两只乌鸦。测试的个股是歌尔股份2020的日K线。
虽然我不知道两只乌鸦是什么玩意,但是可以通过遍历某个长周期(5-10年)下的全部A股数据,通过数据证伪,统计这个形态过后的一周或一个月(个人随意设定)涨跌幅,来证伪这个形态的有效性。
如果得到的是一个50%概率涨跌概况,那说明这个指标形态只是个游走在随机概率的指标,并不能作为一个有效指标参考。
(未完待续) 查看全部
对于一些做股票技术分析的投资者来说,对常见的k线形态应该都不陌生,比如十字星,红三兵,头肩顶(底),岛型反转,吊颈线,两只乌鸦,三只乌鸦,四只乌鸦(哈)

做价投的投资者可能会对这些划线的嗤之以鼻,而短线操盘者却有可能把它奉为圭臬,以之作为买卖标准。
海乃百川,兼听则明,笔者认为多吸收不同的观点与技术,可以更加全面的加深投资认知。你画的圆圈越大,圆圈外的未知空间也越大。
本文介绍使用python对A股市场的股票(转债也可以)的K线进行识别,然后回测某个形态出现后接下来的涨跌幅,还可以通过设定的形态进行选股。
举个例子,我们可以统计所有个股出现了“早晨之星“这一形态后,一周后甚至一个月后,个股是涨了还是跌了,从大量结果中统计出一些有意义的结果。
为了便于验证查看结果图形,我们先介绍如何使用python来画股票K线图。
有数据之后,剩下画图是很简单的,很多第三方的库已经封装好了各种蜡烛图绘制函数。我们要做只是传入每天开,收盘价,以及最高最低价。
获取股票的数据
市面有不少第三方的库可以获取股票和可转债的日线数据,比如tushare和akshare。本文以股票数据为例。
以akshare为例,代码如下所示:
# pip install akshare
import akshare as ak
def get_k_line(code="sz002241"): #
df = ak.stock_zh_a_daily(symbol=code, start_date="20220101", end_date="20220515",
adjust="qfq")
# 这个函数只适合取股票数据,转债会报错,转债的日线数据可以使用其他函数,这里选择股价前复权
df.to_excel("同和药业k.xlsx")
如上面代码所示,我们使用stock_zh_a_daily方法获取一段时间的数据,这里的日期可以根据你的需求进行调整,比如设置start_date=“20200101”,end_date=“20220515”,就可以获取一年时间段的股票数据。
而股票的代码有sh与sz之分,sz代表深市的股票,所有深市的股票前面都必须带上sz,比如这里的同和药业,就是sz002241。
同样的,sh是上证交易所的股票,所有上证的股票前面必须带上sh。
这里,我们来看看获取的同和药业股票数据格式,如下图所示:
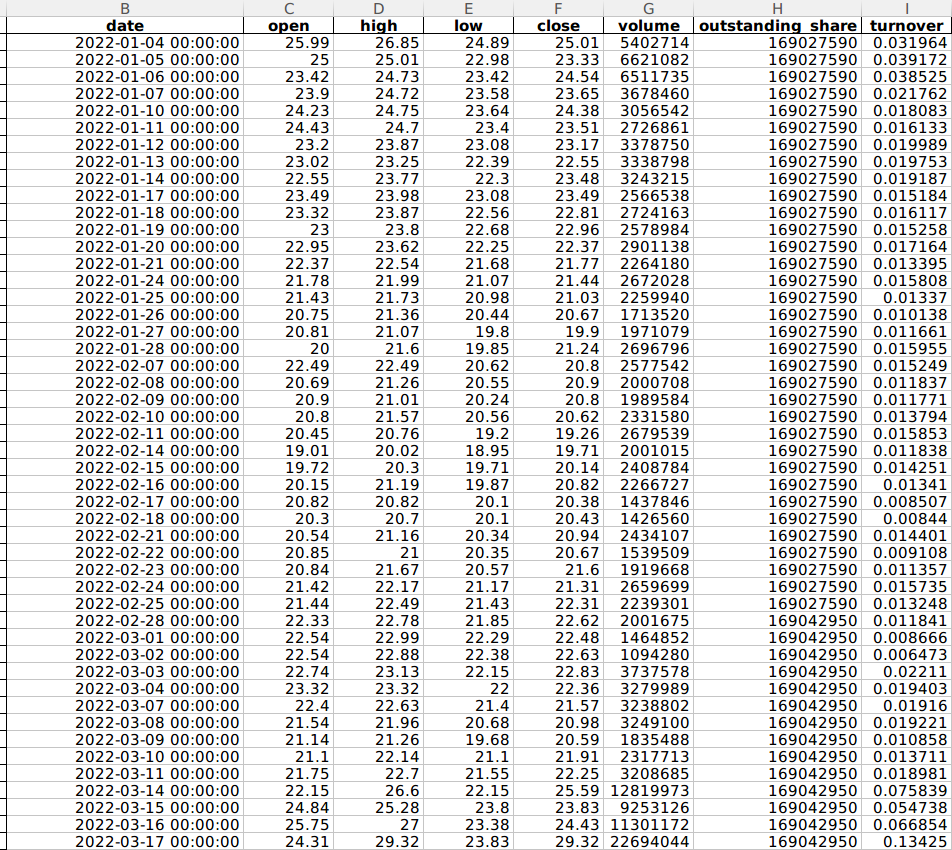
date:交易日期
open:代表开盘价
high:当天最高价
low:当天最低价
close:当天收盘价
volume:当天成交量(元)
outstanding_share:流动股本(股)
turnover:换手率
既然已经拿到了数据,下面我们来绘制K线图。
绘制K线图
在python中,绘制K线图需要用到mpl_finance库,而这个库提供了4种方式绘制K线图,这里我们介绍其中的一种,代码如下所示:
import mpl_finance as mpf
import matplotlib.pyplot as plt
import pandas as pd
#创建绘图的基本参数
fig=plt.figure(figsize=(12, 8))
ax=fig.add_subplot(111)
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
#显示出来
plt.show()
运行此段代码后,会显示如下效果图:
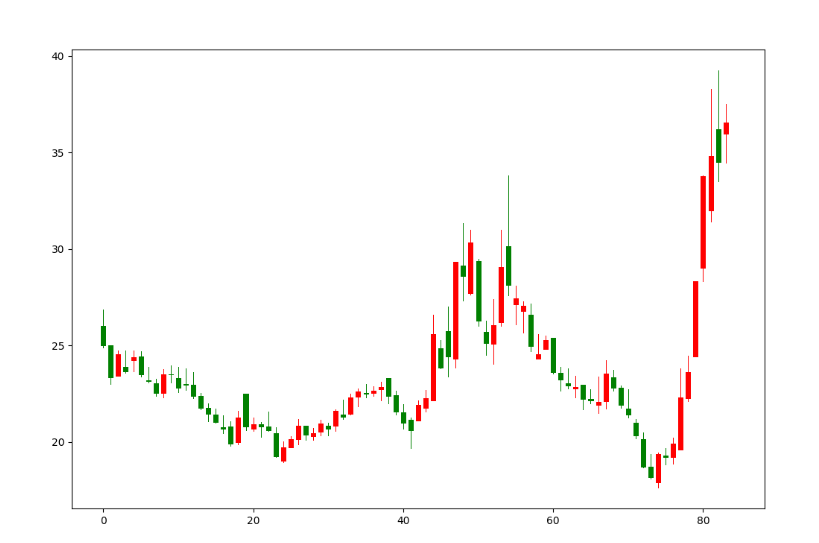
和东财上的同和药业的k线图基本一致的。
不过,这个K线图有一个问题,就是X坐标轴并不是显示的时间,而是数字,这是因为我们绘制K线图的方法,并没有提供X轴的参数,那怎么让下面的数字替换为时间呢?
我们先来看一段代码:
import matplotlib.ticker as ticker
#将股票时间转换为标准时间,不带时分秒的数据
def date_to_num(dates):
num_time = []
for date in dates:
date_time = datetime.strptime(date, '%Y-%m-%d')
num_date = date2num(date_time)
num_time.append(num_date)
return num_time
#创建绘图的基本参数
fig=plt.figure(figsize=(12, 8))
ax=fig.add_subplot(111)
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
df['date'] = pd.to_datetime(df['date'])
df['date'] = df['date'].apply(lambda x: x.strftime('%Y-%m-%d'))
def format_date(x, pos=None):
if x < 0 or x > len(df['date']) - 1:
return ''
return df['date'][int(x)]
ax.xaxis.set_major_formatter(ticker.FuncFormatter(format_date))
plt.setp(plt.gca().get_xticklabels(), rotation=45, horizontalalignment='right')
#显示出来
plt.show()
这里,我们定义了2个方法:第1个方法date_to_num主要的作用就是将获取的时间数据转换为标准的日期数据;第2个方法,就是根据X的数值替换时间值。
其中,set_major_formatter方法是将数值替换为时间值的操作库,而plt.setup的功能就是设置X轴的标签倾斜45度以及右对齐。运行之后,我们的K线图就显示的非常完美了,如下图所示:
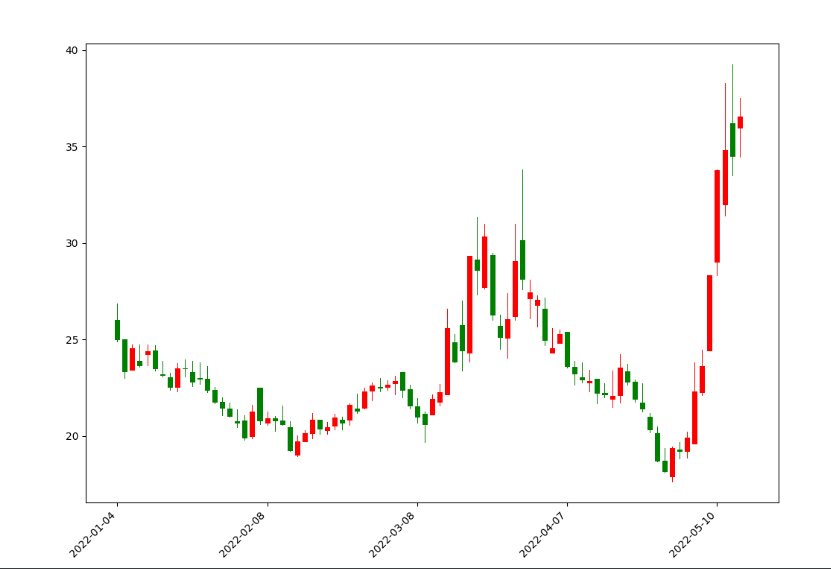
均线图
虽然我们实现了K线图,但是有没有发现,其实大多数的股票交易软件K线图上面其实还标记有均线,比如常用的有5日均线,10日均线,30均线。
所以,我们需要将均线一起添加到我们的K线图之上。
计算均线的方式如下:
df["SMA5"] = df["close"].rolling(5).mean()
df["SMA10"] = df["close"].rolling(10).mean()
df["SMA30"] = df["close"].rolling(30).mean()
3行代码就可以获取到股票的均线值。
接着,我们可以使用上面的ax进行绘制均线了,
添加的代码如下所示:
ax.plot(np.arange(0, len(df)), df['SMA5']) # 绘制5日均线
ax.plot(np.arange(0, len(df)), df['SMA10']) # 绘制10日均线
ax.plot(np.arange(0, len(df)), df['SMA30']) # 绘制30日均线
这里,同样将X轴设置为数字,将这两段代码添加到上面的K线图代码中,自然也会将X轴替换为时间。运行之后,显示效果如下图所示:
这里5日均线为蓝色,10日均线为橙色,30日均线为绿色,如果需要自己设置颜色,可以在每条均线的的绘制方法中加入color参数。
细心的读者肯定发现30日均线只有最后一小段,这是因为前29日不够30日是算不出均线的,同样的5,10日均线也是如此。
成交量
最后,我们还需要绘制成交量。在多数的股票交易软件中,上面是K线图,一般下面对应的就是成交量,这样对比起来看,往往能直观的看到数据的变化。
但是,因为上面有个K线图,那么同一个画布中就有了2个图片,且它们共用一个X轴,那么我们需要更改一下基本的参数,
代码如下所示:
import mpl_finance as mpf
import matplotlib.pyplot as plt
import pandas as pd
import matplotlib.ticker as ticker
import numpy as np
#创建绘图的基本参数
fig, axes = plt.subplots(2, 1, sharex=True, figsize=(15, 10))
ax1, ax2 = axes.flatten()
#获取刚才的股票数据
df = pd.read_excel("同和药业k.xlsx")
mpf.candlestick2_ochl(ax1, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
df['date'] = pd.to_datetime(df['date'])
df['date'] = df['date'].apply(lambda x: x.strftime('%Y-%m-%d'))
def format_date(x, pos=None):
if x < 0 or x > len(df['date']) - 1:
return ''
return df['date'][int(x)]
df["SMA5"] = df["close"].rolling(5).mean()
df["SMA10"] = df["close"].rolling(10).mean()
df["SMA30"] = df["close"].rolling(30).mean()
ax1.plot(np.arange(0, len(df)), df['SMA5']) # 绘制5日均线
ax1.plot(np.arange(0, len(df)), df['SMA10']) # 绘制10日均线
ax1.plot(np.arange(0, len(df)), df['SMA30']) # 绘制30日均线
ax1.xaxis.set_major_formatter(ticker.FuncFormatter(format_date))
plt.setp(plt.gca().get_xticklabels(), rotation=45, horizontalalignment='right')
#显示出来
plt.show()
这里,我们将绘图的画布设置为2行1列。同时,将上面绘制的所有数据都更改为ax1,这样均线与K线图会绘制到第一个子图中。
接着,我们需要绘制成交量,但是我们知道,一般股票交易软件都将上涨的那天成交量设置为红色,而将下跌的成交量绘制成绿色。所以,首先我们要做的是将获取的股票数据根据当天的涨跌情况进行分类。
具体代码如下:
red_pred = np.where(df["close"] > df["open"], df["volume"], 0)
blue_pred = np.where(df["close"] < df["open"], df["volume"], 0)
如上面代码所示,我们通过np.where(condition, x, y)筛选数据。这里满足条件condition,输出X,不满足条件输出Y,这样我们就将涨跌的成交量数据进行了分类。
最后,我们直接通过柱状图方法绘制成交量,
具体代码如下所示:
ax2.bar(np.arange(0, len(df)), red_pred, facecolor="red")
ax2.bar(np.arange(0, len(df)), blue_pred, facecolor="blue")
将这4行代码,全部加入到plt.show()代码的前面即可。
运行之后,输出的效果图如下:
根据定义编写形态
接下来,我们根据定义来构造一个简单的形态函数,比如长上影线。
上影线

根据网络上的定义:
⑤上影阳线:开盘后价格冲高回落,涨势受阻,虽然收盘价仍高于开盘价,但上方有阻力,可视为弱势。
⑥上影阴线:开盘后价格冲高受阻,涨势受阻,收盘价低于开盘价,上方有阻力,可视为弱势。

那么简单定义为:(high - close)/close > 7%,(high - open)/open > 7% ,可能不是太精确,这里只是为了演示,忽略一些具体细节。
简单理解就是,当天最高价比收盘价,开盘价高得多。
长上影匹配函数,简单,只有一行就搞定。
def long_up_shadow(o,c,h,l):
return True if (h-c)/c >=0.07 and (h-o)/o>=0.07 else False
然后把这个长上影函数应用到上面的同和药业。
得到的效果:
df = pd.read_excel("同和药业k.xlsx")
count_num = []
for row,item in df.iterrows():
if long_up_shadow(item['open'],item['close'],item['high'],item['low']):
count_num.append(row)
plot_image(df,count_num)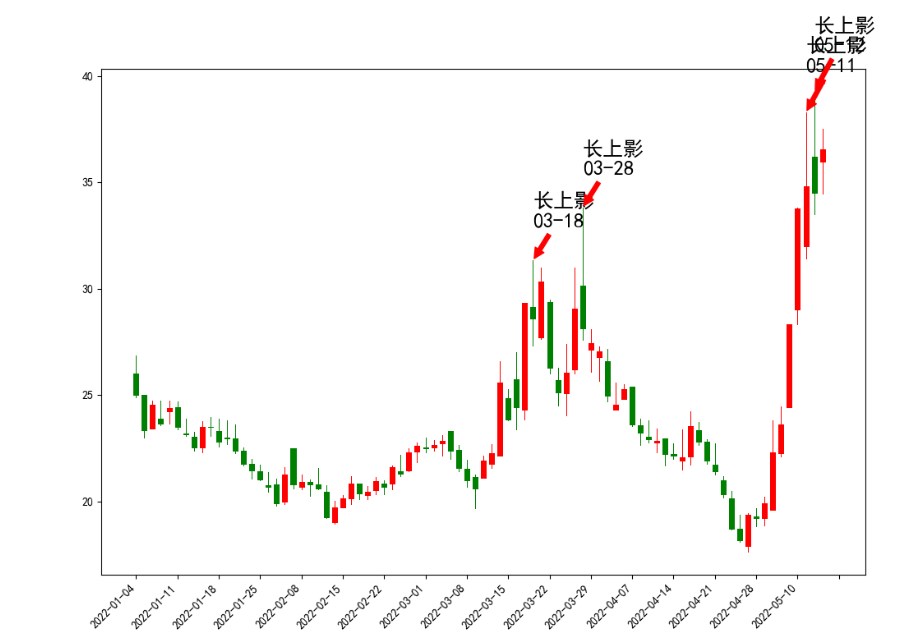
图里面的4个箭头长上影是python自动标上去的,然后对着数据到同花顺核对一下,都是满足长度大于7%的。
可以看到在3月18日和28日的两根长上影之后,同和药业的股价走了一波趋势下跌。【PS:选这个股票并没有刻意去挑选,在集思录默认排名,找了一个跌幅第一个转债的正股就把代码拷贝过来测试】
那么,有这么多的形态,难道每一个都要自己写代码筛选形态吗? 不用哈,因为已经有人写了第三方的库,你只需要调用就可以了。

截取的部分函数名与说明
比如,像两只乌鸦,描述起来都感觉有点复杂,自己手撸代码都会搞出一堆bug。而用taLib这个库,你只需要一行调用代码,就可以完成这些复杂的形态筛选工作。
示例代码:
df['tow_crows'] = talib.CDL2CROWS(df['open'].values, df['high'].values, df['low'].values, df['close'].values)
pattern = df[(df['tow_crows'] == 100) | (df['tow_crows'] == -100)]
上面得到的pattern就是满足要求的形态,如CDL2CROWS 两只乌鸦。测试的个股是歌尔股份2020的日K线。
虽然我不知道两只乌鸦是什么玩意,但是可以通过遍历某个长周期(5-10年)下的全部A股数据,通过数据证伪,统计这个形态过后的一周或一个月(个人随意设定)涨跌幅,来证伪这个形态的有效性。
如果得到的是一个50%概率涨跌概况,那说明这个指标形态只是个游走在随机概率的指标,并不能作为一个有效指标参考。
(未完待续)
B站批量下载某个UP主的所有视频
python • 李魔佛 发表了文章 • 0 个评论 • 5437 次浏览 • 2022-05-21 18:48
使用python实现
https://github.com/Rockyzsu/bilibili
B站视频下载
自动批量下载B站一个系列的视频
下载某个UP主的所有视频
使用:
下载you-get库,git clone https://github.com/soimort/you-get.git 复制其本地路径,比如/root/you-get/you-get
初次运行,删除history.db 文件, 修改配置文件config.py
START=1 # 下载系列视频的 第一个
END=1 # 下载系列视频的最后一个 , 比如一个系列教程有30个视频, start=5 ,end = 20 下载从第5个到第20个
ID='BV1oK411L7au' # 视频的ID
YOU_GET_PATH='/home/xda/othergit/you-get/you-get' # 你的you-get路径
MINS=1 # 每次循环等待1分钟
user_id = '518973111' # UP主的ID
total_page = 3 # up主的视频的页数
执行 python downloader.py ,进行下载循环
python people.py ,把某个up主的视频链接加入到待下载队列
python add_data.py --id=BV1oK411L7au --start=4 --end=8 下载视频id为BV1oK411L7au的系列教程,从第4开始,到第8个结束,如果只有一个的话,start和end设为1即可。
可以不断地往队列里面添加下载链接。
主要代码:
# @Time : 2019/1/28 14:19
# @File : youtube_downloader.py
import logging
import os
import subprocess
import datetime
import sqlite3
import time
from config import YOU_GET_PATH,MINS
CMD = 'python {} {}'
filename = 'url.txt'
class SQLite():
def __init__(self):
self.conn = sqlite3.connect('history.db')
self.cursor = self.conn.cursor()
self.create_table()
def create_table(self):
create_sql = 'create table if not exists tb_download (url varchar(100),status tinyint,crawltime datetime)'
create_record_tb = 'create table if not exists tb_record (idx varchar(100) PRIMARY KEY,start tinyint,end tinyint,status tinyint)'
self.cursor.execute(create_record_tb)
self.conn.commit()
self.cursor.execute(create_sql)
self.conn.commit()
def exists(self,url):
querySet = 'select * from tb_download where url = ? and status = 1'
self.cursor.execute(querySet,(url,))
ret = self.cursor.fetchone()
return True if ret else False
def insert_history(self,url,status):
query = 'select * from tb_download where url=?'
self.cursor.execute(query,(url,))
ret = self.cursor.fetchone()
current = datetime.datetime.now()
if ret:
insert_sql='update tb_download set status=?,crawltime=? where url = ?'
args=(status,status,current,url)
else:
insert_sql = 'insert into tb_download values(?,?,?)'
args=(url,status,current)
try:
self.cursor.execute(insert_sql,args)
except:
self.conn.rollback()
return False
else:
self.conn.commit()
return True
def get(self):
sql = 'select idx,start,end from tb_record where status=0'
self.cursor.execute(sql)
ret= self.cursor.fetchone()
return ret
def set(self,idx):
print('set status =1')
sql='update tb_record set status=1 where idx=?'
self.cursor.execute(sql,(idx,))
self.conn.commit()
def llogger(filename):
logger = logging.getLogger(filename) # 不加名称设置root logger
logger.setLevel(logging.DEBUG) # 设置输出级别
formatter = logging.Formatter(
'[%(asctime)s][%(filename)s][line: %(lineno)d]\[%(levelname)s] ## %(message)s)',
datefmt='%Y-%m-%d %H:%M:%S')
# 使用FileHandler输出到文件
prefix = os.path.splitext(filename)[0]
fh = logging.FileHandler(prefix + '.log')
fh.setLevel(logging.DEBUG)
fh.setFormatter(formatter)
# 使用StreamHandler输出到屏幕
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG)
ch.setFormatter(formatter)
# 添加两个Handler
logger.addHandler(ch)
logger.addHandler(fh)
return logger
logger = llogger('download.log')
sql_obj = SQLite()
def run():
while 1:
result = sql_obj.get()
print(result)
if result:
idx=result[0]
start=result[1]
end=result[2]
try:
download_bilibili(idx,start,end)
except:
pass
else:
sql_obj.set(idx)
else:
time.sleep(MINS*60)
def download_bilibili(id,start_page,total_page):
global doc
bilibili_url = 'https://www.bilibili.com/video/{}?p={}'
for i in range(start_page, total_page+1):
next_url = bilibili_url.format(id, i)
if sql_obj.exists(next_url):
print('have download')
continue
try:
command = CMD.format(YOU_GET_PATH, next_url)
p = subprocess.Popen(command, stdout=subprocess.PIPE, stderr=subprocess.PIPE,
shell=True)
output, error = p.communicate()
except Exception as e:
print('has execption')
sql_obj.insert_history(next_url,status=0)
logger.error(e)
continue
else:
output_str = output.decode()
if len(output_str) == 0:
sql_obj.insert_history(next_url,status=0)
logger.info('下载失败')
continue
logger.info('{} has been downloaded !'.format(next_url))
sql_obj.insert_history(next_url,status=1)
run()
查看全部

使用python实现
https://github.com/Rockyzsu/bilibili
B站视频下载
自动批量下载B站一个系列的视频
下载某个UP主的所有视频
使用:
下载you-get库,git clone https://github.com/soimort/you-get.git 复制其本地路径,比如/root/you-get/you-get
初次运行,删除history.db 文件, 修改配置文件config.py
START=1 # 下载系列视频的 第一个
END=1 # 下载系列视频的最后一个 , 比如一个系列教程有30个视频, start=5 ,end = 20 下载从第5个到第20个
ID='BV1oK411L7au' # 视频的ID
YOU_GET_PATH='/home/xda/othergit/you-get/you-get' # 你的you-get路径
MINS=1 # 每次循环等待1分钟
user_id = '518973111' # UP主的ID
total_page = 3 # up主的视频的页数
执行 python downloader.py ,进行下载循环
python people.py ,把某个up主的视频链接加入到待下载队列
python add_data.py --id=BV1oK411L7au --start=4 --end=8 下载视频id为BV1oK411L7au的系列教程,从第4开始,到第8个结束,如果只有一个的话,start和end设为1即可。
可以不断地往队列里面添加下载链接。
主要代码:
# @Time : 2019/1/28 14:19
# @File : youtube_downloader.py
import logging
import os
import subprocess
import datetime
import sqlite3
import time
from config import YOU_GET_PATH,MINS
CMD = 'python {} {}'
filename = 'url.txt'
class SQLite():
def __init__(self):
self.conn = sqlite3.connect('history.db')
self.cursor = self.conn.cursor()
self.create_table()
def create_table(self):
create_sql = 'create table if not exists tb_download (url varchar(100),status tinyint,crawltime datetime)'
create_record_tb = 'create table if not exists tb_record (idx varchar(100) PRIMARY KEY,start tinyint,end tinyint,status tinyint)'
self.cursor.execute(create_record_tb)
self.conn.commit()
self.cursor.execute(create_sql)
self.conn.commit()
def exists(self,url):
querySet = 'select * from tb_download where url = ? and status = 1'
self.cursor.execute(querySet,(url,))
ret = self.cursor.fetchone()
return True if ret else False
def insert_history(self,url,status):
query = 'select * from tb_download where url=?'
self.cursor.execute(query,(url,))
ret = self.cursor.fetchone()
current = datetime.datetime.now()
if ret:
insert_sql='update tb_download set status=?,crawltime=? where url = ?'
args=(status,status,current,url)
else:
insert_sql = 'insert into tb_download values(?,?,?)'
args=(url,status,current)
try:
self.cursor.execute(insert_sql,args)
except:
self.conn.rollback()
return False
else:
self.conn.commit()
return True
def get(self):
sql = 'select idx,start,end from tb_record where status=0'
self.cursor.execute(sql)
ret= self.cursor.fetchone()
return ret
def set(self,idx):
print('set status =1')
sql='update tb_record set status=1 where idx=?'
self.cursor.execute(sql,(idx,))
self.conn.commit()
def llogger(filename):
logger = logging.getLogger(filename) # 不加名称设置root logger
logger.setLevel(logging.DEBUG) # 设置输出级别
formatter = logging.Formatter(
'[%(asctime)s][%(filename)s][line: %(lineno)d]\[%(levelname)s] ## %(message)s)',
datefmt='%Y-%m-%d %H:%M:%S')
# 使用FileHandler输出到文件
prefix = os.path.splitext(filename)[0]
fh = logging.FileHandler(prefix + '.log')
fh.setLevel(logging.DEBUG)
fh.setFormatter(formatter)
# 使用StreamHandler输出到屏幕
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG)
ch.setFormatter(formatter)
# 添加两个Handler
logger.addHandler(ch)
logger.addHandler(fh)
return logger
logger = llogger('download.log')
sql_obj = SQLite()
def run():
while 1:
result = sql_obj.get()
print(result)
if result:
idx=result[0]
start=result[1]
end=result[2]
try:
download_bilibili(idx,start,end)
except:
pass
else:
sql_obj.set(idx)
else:
time.sleep(MINS*60)
def download_bilibili(id,start_page,total_page):
global doc
bilibili_url = 'https://www.bilibili.com/video/{}?p={}'
for i in range(start_page, total_page+1):
next_url = bilibili_url.format(id, i)
if sql_obj.exists(next_url):
print('have download')
continue
try:
command = CMD.format(YOU_GET_PATH, next_url)
p = subprocess.Popen(command, stdout=subprocess.PIPE, stderr=subprocess.PIPE,
shell=True)
output, error = p.communicate()
except Exception as e:
print('has execption')
sql_obj.insert_history(next_url,status=0)
logger.error(e)
continue
else:
output_str = output.decode()
if len(output_str) == 0:
sql_obj.insert_history(next_url,status=0)
logger.info('下载失败')
continue
logger.info('{} has been downloaded !'.format(next_url))
sql_obj.insert_history(next_url,status=1)
run()
持有封基老师文章合集 word版【包含公众号所有文字】
股票 • 绫波丽 发表了文章 • 0 个评论 • 4122 次浏览 • 2021-09-03 16:11
用程序爬取的数据,不得不说,封基老师从18年开始写文章。坚持每天写一篇。
里面有不少理念都是很适合上班族的。
文章是word版
下载地址:
链接:https://pan.baidu.com/s/1EZwJ6tsFiS92ftAdeNKWDw
提取码:dcp4
查看全部

用程序爬取的数据,不得不说,封基老师从18年开始写文章。坚持每天写一篇。
里面有不少理念都是很适合上班族的。
文章是word版


下载地址:
链接:https://pan.baidu.com/s/1EZwJ6tsFiS92ftAdeNKWDw
提取码:dcp4
开通Ptrade Python量化接口 国金证券/国盛证券
股票 • 绫波丽 发表了文章 • 0 个评论 • 31137 次浏览 • 2021-07-06 08:40
而退而求其次使用按键精灵,模拟点击交易软件进行点击下单,非常不稳定,无法判断下单后是否成交,也无法实时获取行情数据。如果使用tushare或者新浪接口数据,扫描一次全市场的行情用时很久且不稳定,等扫描结束,再下单,此时价格可能已经是几分钟前的了,且此类接口调用次数多是会被封IP的。
笔者使用的是券商提供的量化软件:Ptrade。是恒生电子研发的提供给机构使用的程序化交易软件。提供策略回测,下单API接口,实时行情获取,并且使用的开发语言python,易于上手。
策略回测与实盘交易
研究页面
研究页面,熟悉python jupyter notebook的朋友对这个界面肯定很熟悉。
研究的页面实际就运行你逐行输出调试程序,了解每个函数的具体使用,或者你策略的中途结果调试。
回测策略
实际代码需要在回测策略里面写,写完后确定无误,就可以放在仿真环境下真实运行。如果你运行得到的结果很满意,那么就可以直接部署到实盘服务器上。实盘服务器是在券商那边,不需要个人购买服务器,也不需要本地开着这个Ptrade,就是说不需要在个人电脑上一直开着跑,你的最终代码和程序是在券商服务器上部署与运行,除非有报错异常停止,不然在你不暂停或者停止的前提下,可以一直运行下去。
条件满足后下单
可视化量化
同时也提供一些常见的现成的量化策略,选中后只要鼠标点点点也能够自动化跑这些策略了,当然里面很多参数都可以用鼠标点点点修改。
接口文档也非常详细:
一些常见策略代码:
集合竞价追涨停策略def initialize(context):
# 初始化此策略
# 设置我们要操作的股票池, 这里我们只操作一支股票
g.security = '600570.SS'
set_universe(g.security)
#每天9:23分运行集合竞价处理函数
run_daily(context, aggregate_auction_func, time='9:23')
def aggregate_auction_func(context):
stock = g.security
#最新价
snapshot = get_snapshot(stock)
price = snapshot[stock]['last_px']
#涨停价
up_limit = snapshot[stock]['up_px']
#如果最新价不小于涨停价,买入
if float(price) >= float(up_limit):
order(g.security, 100, limit_price=up_limit)
def handle_data(context, data):
pass
双均线策略def initialize(context):
# 初始化此策略
# 设置我们要操作的股票池, 这里我们只操作一支股票
g.security = '600570.SS'
set_universe(g.security)
pass
#当五日均线高于十日均线时买入,当五日均线低于十日均线时卖出
def handle_data(context, data):
security = g.security
#得到十日历史价格
df = get_history(10, '1d', 'close', security, fq=None, include=False)
# 得到五日均线价格
ma5 = round(df['close'][-5:].mean(), 3)
# 得到十日均线价格
ma10 = round(df['close'][-10:].mean(), 3)
# 取得昨天收盘价
price = data[security]['close']
# 得到当前资金余额
cash = context.portfolio.cash
# 如果当前有余额,并且五日均线大于十日均线
if ma5 > ma10:
# 用所有 cash 买入股票
order_value(security, cash)
# 记录这次买入
log.info("Buying %s" % (security))
# 如果五日均线小于十日均线,并且目前有头寸
elif ma5 < ma10 and get_position(security).amount > 0:
# 全部卖出
order_target(security, 0)
# 记录这次卖出
log.info("Selling %s" % (security))
tick级别均线策略
通俗点就是按照秒级别进行操作。def initialize(context):
# 初始化此策略
# 设置我们要操作的股票池, 这里我们只操作一支股票
g.security = '600570.SS'
set_universe(g.security)
#每3秒运行一次主函数
run_interval(context, func, seconds=3)
#盘前准备历史数据
def before_trading_start(context, data):
history = get_history(10, '1d', 'close', g.security, fq='pre', include=False)
g.close_array = history['close'].values
#当五日均线高于十日均线时买入,当五日均线低于十日均线时卖出
def func(context):
stock = g.security
#获取最新价
snapshot = get_snapshot(stock)
price = snapshot[stock]['last_px']
# 得到五日均线价格
days = 5
ma5 = get_MA_day(stock, days, g.close_array[-4:], price)
# 得到十日均线价格
days = 10
ma10 = get_MA_day(stock, days, g.close_array[-9:], price)
# 得到当前资金余额
cash = context.portfolio.cash
# 如果当前有余额,并且五日均线大于十日均线
if ma5 > ma10:
# 用所有 cash 买入股票
order_value(stock, cash)
# 记录这次买入
log.info("Buying %s" % (stock))
# 如果五日均线小于十日均线,并且目前有头寸
elif ma5 < ma10 and get_position(stock).amount > 0:
# 全部卖出
order_target(stock, 0)
# 记录这次卖出
log.info("Selling %s" % (stock))
#计算实时均线函数
def get_MA_day(stock,days,close_array,current_price):
close_sum = close_array[-(days-1):].sum()
MA = (current_price + close_sum)/days
return MA
def handle_data(context, data):
pass
macd策略def f_expma(N,m,EXPMA1,price):
a = m/(N+1)
EXPMA2 = a * price + (1 - a)*EXPMA1
return EXPMA2 #2为后一天值
#定义macd函数,输入平滑系数参数、前一日值,输出当日值
def macd(N1,N2,N3,m,EXPMA12_1,EXPMA26_1,DEA1,price):
EXPMA12_2 = f_expma(N1,m,EXPMA12_1,price)
EXPMA26_2 = f_expma(N2,m,EXPMA26_1,price)
DIF2 = EXPMA12_2 - EXPMA26_2
a = m/(N3+1)
DEA2 = a * DIF2 + (1 - a)*DEA1
BAR2=2*(DIF2-DEA2)
return EXPMA12_2,EXPMA26_2,DIF2,DEA2,BAR2
def initialize(context):
global init_price
init_price = None
# 获取沪深300股票
g.security = get_index_stocks('000300.SS')
#g.security = ['600570.SS']
# 设置我们要操作的股票池, 这里我们只操作一支股票
set_universe(g.security)
def handle_data(context, data):
# 获取历史数据,这里只获取了2天的数据,如果希望最终MACD指标结果更准确最好是获取
# 从股票上市至今的所有历史数据,即增加获取的天数
close_price = get_history(2, '1d', field='close', security_list=g.security)
#如果是停牌不进行计算
for security in g.security:
if data[security].is_open >0:
global init_price,EXPMA12_1,EXPMA26_1,EXPMA12_2,EXPMA26_2,DIF1,DIF2,DEA1,DEA2
if init_price is None:
init_price = close_price[security].mean()#nan和N-1个数,mean为N-1个数的均值
EXPMA12_1 = init_price
EXPMA26_1 = init_price
DIF1 = init_price
DEA1 = init_price
# m用于计算平滑系数a=m/(N+1)
m = 2.0
#设定指数平滑基期数
N1 = 12
N2 = 26
N3 = 9
EXPMA12_2,EXPMA26_2,DIF2,DEA2,BAR2 = macd(N1,N2,N3,m,EXPMA12_1,EXPMA26_1,DEA1,close_price[security][-1])
# 取得当前价格
current_price = data[security].price
# 取得当前的现金
cash = context.portfolio.cash
# DIF、DEA均为正,DIF向上突破DEA,买入信号参考
if DIF2 > 0 and DEA2 > 0 and DIF1 < DEA1 and DIF2 > DEA2:
# 计算可以买多少只股票
number_of_shares = int(cash/current_price)
# 购买量大于0时,下单
if number_of_shares > 0:
# 以市单价买入股票,日回测时即是开盘价
order(security, +number_of_shares)
# 记录这次买入
log.info("Buying %s" % (security))
# DIF、DEA均为负,DIF向下突破DEA,卖出信号参考
elif DIF2 < 0 and DEA2 < 0 and DIF1 > DEA1 and DIF2 < DEA2 and get_position(security).amount > 0:
# 卖出所有股票,使这只股票的最终持有量为0
order_target(security, 0)
# 记录这次卖出
log.info("Selling %s" % (security))
# 将今日的值赋给全局变量作为下一次前一日的值
DEA1 = DEA2
DIF1 = DIF2
EXPMA12_1 = EXPMA12_2
EXPMA26_1 = EXPMA26_2
软件与交易接口开通条件:
开通该券商后,存入资金指定资金即可开通。开通后股票交易费率万一
本身券商的交易费率为股票万一,可转债沪百万分之五,深十万分之五,基金万0.5,非常厚道。
不太了解量化行业的可以了解下,不少面向机构的量化交易软件的佣金是万2.5的,且开户门槛高,基本是500W以上,比如华泰的matic量化的门槛是1千万元起步。
所以笔者还是很推荐目前该券商的量化交易接口。
需要开通咨询了解的朋友可以扫码联系:
开通券商账户后可以 可以先试用,再考虑是否开通量化接口权限 查看全部
而退而求其次使用按键精灵,模拟点击交易软件进行点击下单,非常不稳定,无法判断下单后是否成交,也无法实时获取行情数据。如果使用tushare或者新浪接口数据,扫描一次全市场的行情用时很久且不稳定,等扫描结束,再下单,此时价格可能已经是几分钟前的了,且此类接口调用次数多是会被封IP的。
笔者使用的是券商提供的量化软件:Ptrade。是恒生电子研发的提供给机构使用的程序化交易软件。提供策略回测,下单API接口,实时行情获取,并且使用的开发语言python,易于上手。
策略回测与实盘交易

研究页面
研究页面,熟悉python jupyter notebook的朋友对这个界面肯定很熟悉。
研究的页面实际就运行你逐行输出调试程序,了解每个函数的具体使用,或者你策略的中途结果调试。

回测策略
实际代码需要在回测策略里面写,写完后确定无误,就可以放在仿真环境下真实运行。如果你运行得到的结果很满意,那么就可以直接部署到实盘服务器上。实盘服务器是在券商那边,不需要个人购买服务器,也不需要本地开着这个Ptrade,就是说不需要在个人电脑上一直开着跑,你的最终代码和程序是在券商服务器上部署与运行,除非有报错异常停止,不然在你不暂停或者停止的前提下,可以一直运行下去。


条件满足后下单
可视化量化
同时也提供一些常见的现成的量化策略,选中后只要鼠标点点点也能够自动化跑这些策略了,当然里面很多参数都可以用鼠标点点点修改。

接口文档也非常详细:

一些常见策略代码:
集合竞价追涨停策略
def initialize(context):
# 初始化此策略
# 设置我们要操作的股票池, 这里我们只操作一支股票
g.security = '600570.SS'
set_universe(g.security)
#每天9:23分运行集合竞价处理函数
run_daily(context, aggregate_auction_func, time='9:23')
def aggregate_auction_func(context):
stock = g.security
#最新价
snapshot = get_snapshot(stock)
price = snapshot[stock]['last_px']
#涨停价
up_limit = snapshot[stock]['up_px']
#如果最新价不小于涨停价,买入
if float(price) >= float(up_limit):
order(g.security, 100, limit_price=up_limit)
def handle_data(context, data):
pass
双均线策略
def initialize(context):
# 初始化此策略
# 设置我们要操作的股票池, 这里我们只操作一支股票
g.security = '600570.SS'
set_universe(g.security)
pass
#当五日均线高于十日均线时买入,当五日均线低于十日均线时卖出
def handle_data(context, data):
security = g.security
#得到十日历史价格
df = get_history(10, '1d', 'close', security, fq=None, include=False)
# 得到五日均线价格
ma5 = round(df['close'][-5:].mean(), 3)
# 得到十日均线价格
ma10 = round(df['close'][-10:].mean(), 3)
# 取得昨天收盘价
price = data[security]['close']
# 得到当前资金余额
cash = context.portfolio.cash
# 如果当前有余额,并且五日均线大于十日均线
if ma5 > ma10:
# 用所有 cash 买入股票
order_value(security, cash)
# 记录这次买入
log.info("Buying %s" % (security))
# 如果五日均线小于十日均线,并且目前有头寸
elif ma5 < ma10 and get_position(security).amount > 0:
# 全部卖出
order_target(security, 0)
# 记录这次卖出
log.info("Selling %s" % (security))
tick级别均线策略
通俗点就是按照秒级别进行操作。
def initialize(context):
# 初始化此策略
# 设置我们要操作的股票池, 这里我们只操作一支股票
g.security = '600570.SS'
set_universe(g.security)
#每3秒运行一次主函数
run_interval(context, func, seconds=3)
#盘前准备历史数据
def before_trading_start(context, data):
history = get_history(10, '1d', 'close', g.security, fq='pre', include=False)
g.close_array = history['close'].values
#当五日均线高于十日均线时买入,当五日均线低于十日均线时卖出
def func(context):
stock = g.security
#获取最新价
snapshot = get_snapshot(stock)
price = snapshot[stock]['last_px']
# 得到五日均线价格
days = 5
ma5 = get_MA_day(stock, days, g.close_array[-4:], price)
# 得到十日均线价格
days = 10
ma10 = get_MA_day(stock, days, g.close_array[-9:], price)
# 得到当前资金余额
cash = context.portfolio.cash
# 如果当前有余额,并且五日均线大于十日均线
if ma5 > ma10:
# 用所有 cash 买入股票
order_value(stock, cash)
# 记录这次买入
log.info("Buying %s" % (stock))
# 如果五日均线小于十日均线,并且目前有头寸
elif ma5 < ma10 and get_position(stock).amount > 0:
# 全部卖出
order_target(stock, 0)
# 记录这次卖出
log.info("Selling %s" % (stock))
#计算实时均线函数
def get_MA_day(stock,days,close_array,current_price):
close_sum = close_array[-(days-1):].sum()
MA = (current_price + close_sum)/days
return MA
def handle_data(context, data):
pass
macd策略
def f_expma(N,m,EXPMA1,price):
a = m/(N+1)
EXPMA2 = a * price + (1 - a)*EXPMA1
return EXPMA2 #2为后一天值
#定义macd函数,输入平滑系数参数、前一日值,输出当日值
def macd(N1,N2,N3,m,EXPMA12_1,EXPMA26_1,DEA1,price):
EXPMA12_2 = f_expma(N1,m,EXPMA12_1,price)
EXPMA26_2 = f_expma(N2,m,EXPMA26_1,price)
DIF2 = EXPMA12_2 - EXPMA26_2
a = m/(N3+1)
DEA2 = a * DIF2 + (1 - a)*DEA1
BAR2=2*(DIF2-DEA2)
return EXPMA12_2,EXPMA26_2,DIF2,DEA2,BAR2
def initialize(context):
global init_price
init_price = None
# 获取沪深300股票
g.security = get_index_stocks('000300.SS')
#g.security = ['600570.SS']
# 设置我们要操作的股票池, 这里我们只操作一支股票
set_universe(g.security)
def handle_data(context, data):
# 获取历史数据,这里只获取了2天的数据,如果希望最终MACD指标结果更准确最好是获取
# 从股票上市至今的所有历史数据,即增加获取的天数
close_price = get_history(2, '1d', field='close', security_list=g.security)
#如果是停牌不进行计算
for security in g.security:
if data[security].is_open >0:
global init_price,EXPMA12_1,EXPMA26_1,EXPMA12_2,EXPMA26_2,DIF1,DIF2,DEA1,DEA2
if init_price is None:
init_price = close_price[security].mean()#nan和N-1个数,mean为N-1个数的均值
EXPMA12_1 = init_price
EXPMA26_1 = init_price
DIF1 = init_price
DEA1 = init_price
# m用于计算平滑系数a=m/(N+1)
m = 2.0
#设定指数平滑基期数
N1 = 12
N2 = 26
N3 = 9
EXPMA12_2,EXPMA26_2,DIF2,DEA2,BAR2 = macd(N1,N2,N3,m,EXPMA12_1,EXPMA26_1,DEA1,close_price[security][-1])
# 取得当前价格
current_price = data[security].price
# 取得当前的现金
cash = context.portfolio.cash
# DIF、DEA均为正,DIF向上突破DEA,买入信号参考
if DIF2 > 0 and DEA2 > 0 and DIF1 < DEA1 and DIF2 > DEA2:
# 计算可以买多少只股票
number_of_shares = int(cash/current_price)
# 购买量大于0时,下单
if number_of_shares > 0:
# 以市单价买入股票,日回测时即是开盘价
order(security, +number_of_shares)
# 记录这次买入
log.info("Buying %s" % (security))
# DIF、DEA均为负,DIF向下突破DEA,卖出信号参考
elif DIF2 < 0 and DEA2 < 0 and DIF1 > DEA1 and DIF2 < DEA2 and get_position(security).amount > 0:
# 卖出所有股票,使这只股票的最终持有量为0
order_target(security, 0)
# 记录这次卖出
log.info("Selling %s" % (security))
# 将今日的值赋给全局变量作为下一次前一日的值
DEA1 = DEA2
DIF1 = DIF2
EXPMA12_1 = EXPMA12_2
EXPMA26_1 = EXPMA26_2
软件与交易接口开通条件:
开通该券商后,存入资金指定资金即可开通。开通后股票交易费率万一
本身券商的交易费率为股票万一,可转债沪百万分之五,深十万分之五,基金万0.5,非常厚道。
不太了解量化行业的可以了解下,不少面向机构的量化交易软件的佣金是万2.5的,且开户门槛高,基本是500W以上,比如华泰的matic量化的门槛是1千万元起步。
所以笔者还是很推荐目前该券商的量化交易接口。
需要开通咨询了解的朋友可以扫码联系:
开通券商账户后可以 可以先试用,再考虑是否开通量化接口权限
量化交易接口python A股
股票 • 绫波丽 发表了文章 • 0 个评论 • 13960 次浏览 • 2021-07-01 11:22
实际操作也好,几乎没见几个人教你怎么用程序下单,实盘交易。
稍微好点的easytrader使用的是模拟点击交易软件进行点击下单,基本无法判断下单后是否成交,也无法实时获取行情数据。别跟我说用tushare或者新浪这些接口数据,除非你做的是低频交易。
试试扫描一次全市场的行情看看用时多少?等得到满足条件了,再下单,此时价格可能已经在涨停板上封住了。
笔者使用的是券商提供的量化软件:Ptrade。
是恒生电子研发的提供给券商机构使用的程序化交易软件。提供策略回测,自动下单功能,使用的开发语言python。
策略回测与实盘交易
研究页面
研究页面,熟悉python jupyter notebook的朋友对这个界面肯定很熟悉。
研究的页面实际就运行你逐行输出调试程序,了解每个函数的具体使用,或者你策略的中途结果调试。
回测策略
实际代码需要在回测策略里面写,写完后确定无误,就可以放在仿真环境下真实运行。
如果你运行得到的结果很满意,那么就可以直接部署到实盘服务器上。
实盘服务器是在券商那边,不需要个人购买服务器,也不需要本地开着这个Ptrade,就是说不需要在个人电脑上一直开着跑,你的最终代码和程序是在券商服务器上部署与运行,除非有报错异常停止,不然在你不暂停或者停止的前提下,可以一直运行下去。
条件满足后下单
可视化量化
同时也提供一些常见的现成的量化策略,选中后只要鼠标点点点也能够自动化跑这些策略了,当然里面很多参数都可以用鼠标点点点修改。
接口文档也非常详细:
一些常见策略代码:
双均线策略 def initialize(context):
2 # 初始化此策略
3 # 设置我们要操作的股票池, 这里我们只操作一支股票
4 g.security = '600570.SS'
5 set_universe(g.security)
6 pass
7
8 #当五日均线高于十日均线时买入,当五日均线低于十日均线时卖出
9 def handle_data(context, data):
10 security = g.security
11
12 #得到十日历史价格
13 df = get_history(10, '1d', 'close', security, fq=None, include=False)
14
15 # 得到五日均线价格
16 ma5 = round(df['close'][-5:].mean(), 3)
17
18 # 得到十日均线价格
19 ma10 = round(df['close'][-10:].mean(), 3)
20
21 # 取得昨天收盘价
22 price = data[security]['close']
23
24 # 得到当前资金余额
25 cash = context.portfolio.cash
26
27 # 如果当前有余额,并且五日均线大于十日均线
28 if ma5 > ma10:
29 # 用所有 cash 买入股票
30 order_value(security, cash)
31 # 记录这次买入
32 log.info("Buying %s" % (security))
33
34 # 如果五日均线小于十日均线,并且目前有头寸
35 elif ma5 < ma10 and get_position(security).amount > 0:
36 # 全部卖出
37 order_target(security, 0)
38 # 记录这次卖出
39 log.info("Selling %s" % (security))
macd策略
指数平滑均线函数,以price计算,可以选择收盘、开盘价等价格,N为时间周期,m用于计算平滑系数a=m/(N+1),EXPMA1为前一日值 def f_expma(N,m,EXPMA1,price):
2 a = m/(N+1)
3 EXPMA2 = a * price + (1 - a)*EXPMA1
4 return EXPMA2 #2为后一天值
5
6 #定义macd函数,输入平滑系数参数、前一日值,输出当日值
7 def macd(N1,N2,N3,m,EXPMA12_1,EXPMA26_1,DEA1,price):
8 EXPMA12_2 = f_expma(N1,m,EXPMA12_1,price)
9 EXPMA26_2 = f_expma(N2,m,EXPMA26_1,price)
10 DIF2 = EXPMA12_2 - EXPMA26_2
11 a = m/(N3+1)
12 DEA2 = a * DIF2 + (1 - a)*DEA1
13 BAR2=2*(DIF2-DEA2)
14 return EXPMA12_2,EXPMA26_2,DIF2,DEA2,BAR2
15
16 def initialize(context):
17 global init_price
18 init_price = None
19 # 获取沪深300股票
20 g.security = get_index_stocks('000300.SS')
21 #g.security = ['600570.SS']
22 # 设置我们要操作的股票池, 这里我们只操作一支股票
23 set_universe(g.security)
24
25 def handle_data(context, data):
26 # 获取历史数据,这里只获取了2天的数据,如果希望最终MACD指标结果更准确最好是获取
27 # 从股票上市至今的所有历史数据,即增加获取的天数
28 close_price = get_history(2, '1d', field='close', security_list=g.security)
29 #如果是停牌不进行计算
30 for security in g.security:
31 if data[security].is_open >0:
32 global init_price,EXPMA12_1,EXPMA26_1,EXPMA12_2,EXPMA26_2,DIF1,DIF2,DEA1,DEA2
33 if init_price is None:
34 init_price = close_price[security].mean()#nan和N-1个数,mean为N-1个数的均值
35 EXPMA12_1 = init_price
36 EXPMA26_1 = init_price
37 DIF1 = init_price
38 DEA1 = init_price
39 # m用于计算平滑系数a=m/(N+1)
40 m = 2.0
41 #设定指数平滑基期数
42 N1 = 12
43 N2 = 26
44 N3 = 9
45 EXPMA12_2,EXPMA26_2,DIF2,DEA2,BAR2 = macd(N1,N2,N3,m,EXPMA12_1,EXPMA26_1,DEA1,close_price[security][-1])
46 # 取得当前价格
47 current_price = data[security].price
48 # 取得当前的现金
49 cash = context.portfolio.cash
50 # DIF、DEA均为正,DIF向上突破DEA,买入信号参考
51 if DIF2 > 0 and DEA2 > 0 and DIF1 < DEA1 and DIF2 > DEA2:
52 # 计算可以买多少只股票
53 number_of_shares = int(cash/current_price)
54 # 购买量大于0时,下单
55 if number_of_shares > 0:
56 # 以市单价买入股票,日回测时即是开盘价
57 order(security, +number_of_shares)
58 # 记录这次买入
59 log.info("Buying %s" % (security))
60 # DIF、DEA均为负,DIF向下突破DEA,卖出信号参考
61 elif DIF2 < 0 and DEA2 < 0 and DIF1 > DEA1 and DIF2 < DEA2 and get_position(security).amount > 0:
62 # 卖出所有股票,使这只股票的最终持有量为0
63 order_target(security, 0)
64 # 记录这次卖出
65 log.info("Selling %s" % (security))
66 # 将今日的值赋给全局变量作为下一次前一日的值
67 DEA1 = DEA2
68 DIF1 = DIF2
69 EXPMA12_1 = EXPMA12_2
70 EXPMA26_1 = EXPMA26_2
同时也支持可转债T+0交易,笔者平时也主要是进行的可转债的交易。
软件与交易接口开通条件,
开通改券商后,存入资金50W放2周即可开通,开通后可取出。
本身券商的交易费率为股票万一免五,可转债百万分之二,非常厚道,因为不少面向机构的量化交易软件的佣金是万2.5的,笔者之前在国金渠道开的就是,坑的一比。所以笔者还是很推荐目前该券商的量化交易接口。
需要可以关注公众号获取开通链接: 查看全部
实际操作也好,几乎没见几个人教你怎么用程序下单,实盘交易。
稍微好点的easytrader使用的是模拟点击交易软件进行点击下单,基本无法判断下单后是否成交,也无法实时获取行情数据。别跟我说用tushare或者新浪这些接口数据,除非你做的是低频交易。
试试扫描一次全市场的行情看看用时多少?等得到满足条件了,再下单,此时价格可能已经在涨停板上封住了。
笔者使用的是券商提供的量化软件:Ptrade。
是恒生电子研发的提供给券商机构使用的程序化交易软件。提供策略回测,自动下单功能,使用的开发语言python。
策略回测与实盘交易

研究页面
研究页面,熟悉python jupyter notebook的朋友对这个界面肯定很熟悉。
研究的页面实际就运行你逐行输出调试程序,了解每个函数的具体使用,或者你策略的中途结果调试。

回测策略
实际代码需要在回测策略里面写,写完后确定无误,就可以放在仿真环境下真实运行。
如果你运行得到的结果很满意,那么就可以直接部署到实盘服务器上。
实盘服务器是在券商那边,不需要个人购买服务器,也不需要本地开着这个Ptrade,就是说不需要在个人电脑上一直开着跑,你的最终代码和程序是在券商服务器上部署与运行,除非有报错异常停止,不然在你不暂停或者停止的前提下,可以一直运行下去。


条件满足后下单
可视化量化
同时也提供一些常见的现成的量化策略,选中后只要鼠标点点点也能够自动化跑这些策略了,当然里面很多参数都可以用鼠标点点点修改。

接口文档也非常详细:

一些常见策略代码:
双均线策略
def initialize(context):
2 # 初始化此策略
3 # 设置我们要操作的股票池, 这里我们只操作一支股票
4 g.security = '600570.SS'
5 set_universe(g.security)
6 pass
7
8 #当五日均线高于十日均线时买入,当五日均线低于十日均线时卖出
9 def handle_data(context, data):
10 security = g.security
11
12 #得到十日历史价格
13 df = get_history(10, '1d', 'close', security, fq=None, include=False)
14
15 # 得到五日均线价格
16 ma5 = round(df['close'][-5:].mean(), 3)
17
18 # 得到十日均线价格
19 ma10 = round(df['close'][-10:].mean(), 3)
20
21 # 取得昨天收盘价
22 price = data[security]['close']
23
24 # 得到当前资金余额
25 cash = context.portfolio.cash
26
27 # 如果当前有余额,并且五日均线大于十日均线
28 if ma5 > ma10:
29 # 用所有 cash 买入股票
30 order_value(security, cash)
31 # 记录这次买入
32 log.info("Buying %s" % (security))
33
34 # 如果五日均线小于十日均线,并且目前有头寸
35 elif ma5 < ma10 and get_position(security).amount > 0:
36 # 全部卖出
37 order_target(security, 0)
38 # 记录这次卖出
39 log.info("Selling %s" % (security))
macd策略
指数平滑均线函数,以price计算,可以选择收盘、开盘价等价格,N为时间周期,m用于计算平滑系数a=m/(N+1),EXPMA1为前一日值
def f_expma(N,m,EXPMA1,price):
2 a = m/(N+1)
3 EXPMA2 = a * price + (1 - a)*EXPMA1
4 return EXPMA2 #2为后一天值
5
6 #定义macd函数,输入平滑系数参数、前一日值,输出当日值
7 def macd(N1,N2,N3,m,EXPMA12_1,EXPMA26_1,DEA1,price):
8 EXPMA12_2 = f_expma(N1,m,EXPMA12_1,price)
9 EXPMA26_2 = f_expma(N2,m,EXPMA26_1,price)
10 DIF2 = EXPMA12_2 - EXPMA26_2
11 a = m/(N3+1)
12 DEA2 = a * DIF2 + (1 - a)*DEA1
13 BAR2=2*(DIF2-DEA2)
14 return EXPMA12_2,EXPMA26_2,DIF2,DEA2,BAR2
15
16 def initialize(context):
17 global init_price
18 init_price = None
19 # 获取沪深300股票
20 g.security = get_index_stocks('000300.SS')
21 #g.security = ['600570.SS']
22 # 设置我们要操作的股票池, 这里我们只操作一支股票
23 set_universe(g.security)
24
25 def handle_data(context, data):
26 # 获取历史数据,这里只获取了2天的数据,如果希望最终MACD指标结果更准确最好是获取
27 # 从股票上市至今的所有历史数据,即增加获取的天数
28 close_price = get_history(2, '1d', field='close', security_list=g.security)
29 #如果是停牌不进行计算
30 for security in g.security:
31 if data[security].is_open >0:
32 global init_price,EXPMA12_1,EXPMA26_1,EXPMA12_2,EXPMA26_2,DIF1,DIF2,DEA1,DEA2
33 if init_price is None:
34 init_price = close_price[security].mean()#nan和N-1个数,mean为N-1个数的均值
35 EXPMA12_1 = init_price
36 EXPMA26_1 = init_price
37 DIF1 = init_price
38 DEA1 = init_price
39 # m用于计算平滑系数a=m/(N+1)
40 m = 2.0
41 #设定指数平滑基期数
42 N1 = 12
43 N2 = 26
44 N3 = 9
45 EXPMA12_2,EXPMA26_2,DIF2,DEA2,BAR2 = macd(N1,N2,N3,m,EXPMA12_1,EXPMA26_1,DEA1,close_price[security][-1])
46 # 取得当前价格
47 current_price = data[security].price
48 # 取得当前的现金
49 cash = context.portfolio.cash
50 # DIF、DEA均为正,DIF向上突破DEA,买入信号参考
51 if DIF2 > 0 and DEA2 > 0 and DIF1 < DEA1 and DIF2 > DEA2:
52 # 计算可以买多少只股票
53 number_of_shares = int(cash/current_price)
54 # 购买量大于0时,下单
55 if number_of_shares > 0:
56 # 以市单价买入股票,日回测时即是开盘价
57 order(security, +number_of_shares)
58 # 记录这次买入
59 log.info("Buying %s" % (security))
60 # DIF、DEA均为负,DIF向下突破DEA,卖出信号参考
61 elif DIF2 < 0 and DEA2 < 0 and DIF1 > DEA1 and DIF2 < DEA2 and get_position(security).amount > 0:
62 # 卖出所有股票,使这只股票的最终持有量为0
63 order_target(security, 0)
64 # 记录这次卖出
65 log.info("Selling %s" % (security))
66 # 将今日的值赋给全局变量作为下一次前一日的值
67 DEA1 = DEA2
68 DIF1 = DIF2
69 EXPMA12_1 = EXPMA12_2
70 EXPMA26_1 = EXPMA26_2
同时也支持可转债T+0交易,笔者平时也主要是进行的可转债的交易。
软件与交易接口开通条件,
开通改券商后,存入资金50W放2周即可开通,开通后可取出。
本身券商的交易费率为股票万一免五,可转债百万分之二,非常厚道,因为不少面向机构的量化交易软件的佣金是万2.5的,笔者之前在国金渠道开的就是,坑的一比。所以笔者还是很推荐目前该券商的量化交易接口。
需要可以关注公众号获取开通链接:
